
Spring源码之循环依赖之三级缓存详解
作者:一定会去到彩虹海的麦当
循环依赖
定义
循环依赖就 循环引用,就是两个或多个 bean 相互之间的持有对方,比如 CircleA 引用 CircleB , CircleB 引用 CircleC, CircleC 引用 CircleA ,则它们最终反映为 个环。此处不是循环调用,循环调用是方法之间的环调用。
循环调用是无法解决的,除非有终结条件,否则就是死循环,最终导致内存溢出错误
三种循环依赖的情况
Spring容器将每一个正在创建的bean标识符放在一个“当前创建bean池”中,bean标识符在创建过程中将一直保持在这个池中,因此如果在创建bean过程中发现自己已经在“当前创建bean池”里时,将抛出BeanCurrentlylnCreationException异常表示循环依赖;而对于创建完毕的bean将从“当前创建bean池"中清除掉。
1.构造器循环依赖
表示通过构造器注入构成的循环依赖,此依赖是无法解决的,只能抛出异常
2.settler循环依赖
表示通过setter注入方式构成的循环依赖。对于setter注入造成的依赖是通过Spring容器提前暴露刚完成构造器注入但未完成其他步骤(如setter注人)的bean来完成的,而且只能解决单例作用域的bean循环依赖。通过提前暴露一个单例工厂方法,从而使其他bean能引用到该bean。
3.prototype范围的依赖处理
对于"prototype"作用域bean,Spring容器无法完成依赖注人,因为Spring容器不进行缓存"prototype"作用域的bean,因此无法提前暴露一个创建中的bean。
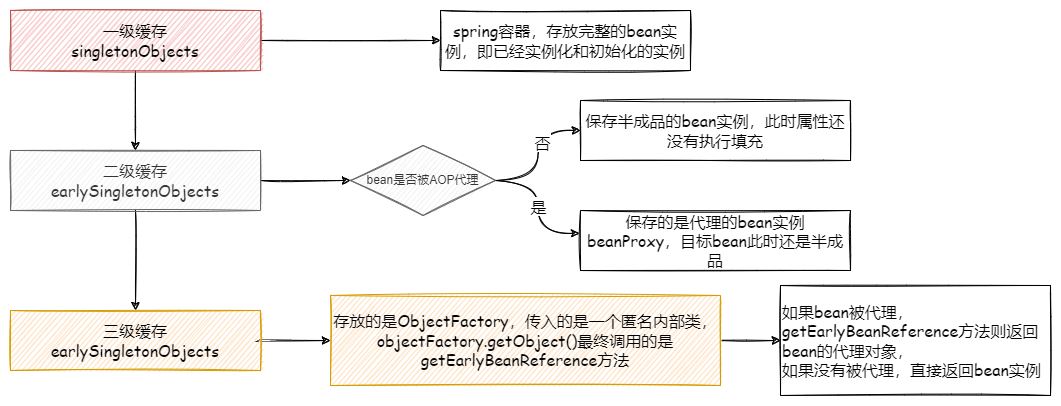
三级缓存机制
- 定义 一级缓存用于存放已经实例化、初始化完成的Bean,
单例池-singletonObjects - 二级缓存用于存放已经实例化,但
未初始化的Bean.保证一个类多次循环依赖时仅构建一次保证单例提前曝光早产bean池-earlySingletonObjects - 三级缓存用于存放该Bean的BeanFactory,当加载一个Bean会先将该Bean包装为BeanFactory放入三级缓存
早期单例bean工厂池-singletonFactories
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry {
/** Cache of singleton objects: bean name --> bean instance */
//用于存放完全初始化好的 bean从该缓存中取出的 bean可以直接使用
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name --> ObjectFactory */
//存放 bean工厂对象解决循环依赖
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
//存放原始的bean对象用于解决循环依赖,注意:存到里面的对象还没有被填充属性
/** Cache of early singleton objects: bean name --> bean instance */
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
}
整体分析
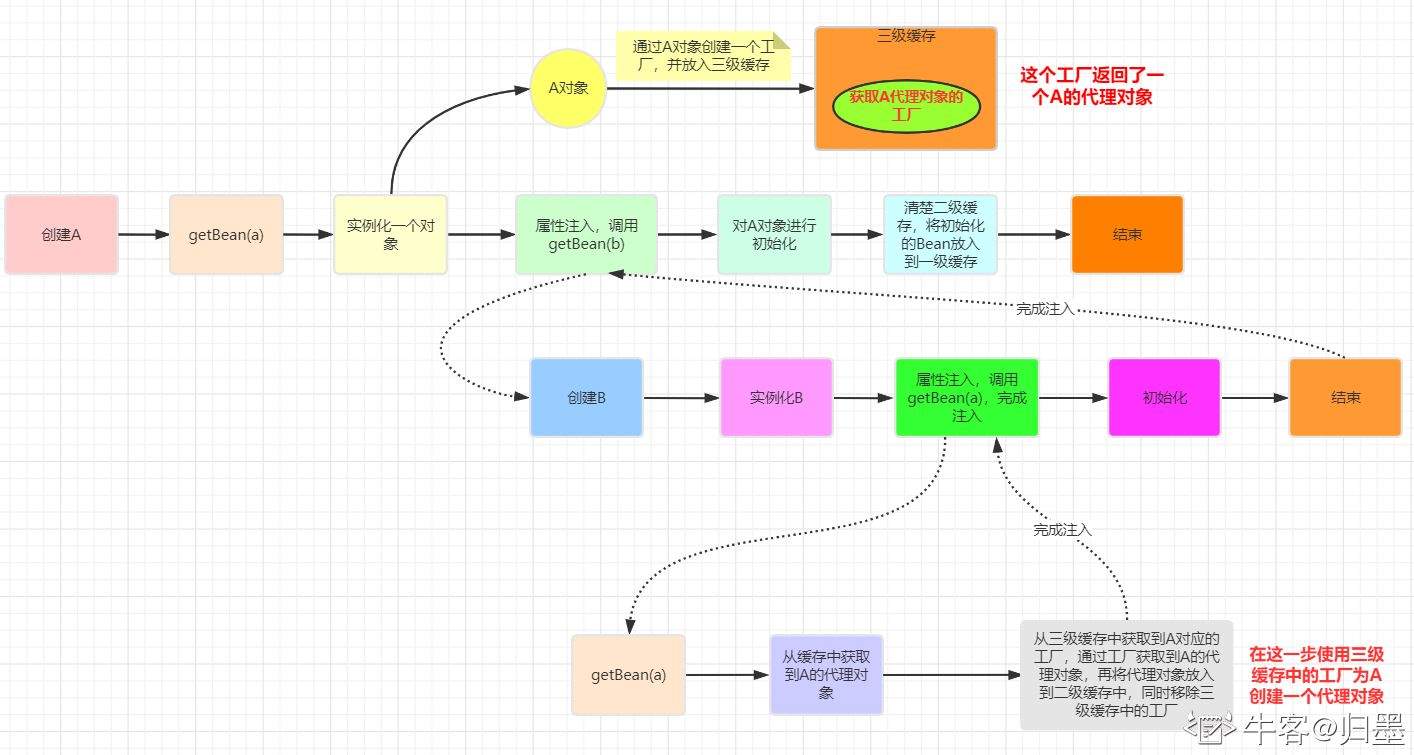
创建Bean会先将该Bean的BeanFactory放到三级缓存中,以用来防止循环依赖问题.当存在有A,B两个Bean循环依赖时,创建流程如下
1.先创建BeanA,先实例化BeanA并包装为BeanFactory并放入三级缓存中.
2.给BeanA进行属性填充时检查依赖,发现BeanB未加载过,则先去加载BeanB
3.BeanB创建过程首先也要包装成BeanFactory放到三级缓存,填充属性时则是从三级缓存获取Bean将BeanA填充进去
4.。BeanB填充BeanA从三级缓存中的BeanAFacotry获取BeanA
5.获取主要通过ObjectFactory.getObject方法,该方法调用getEarlyBeanReference方法,他会创建Bean/Bean的代理并删除BeanA的三级缓存,加入二级缓存
6.BeanB初始化完毕加入一级缓存,BeanA继续执行初始化,初始化完毕比较BeanA二级缓存和一级缓存是否一致,一致则加入一级缓存删除二级缓存
源码分析
此处以A、B类的互相依赖注入为例,在这里表达出关键代码的走势:
1.入口处即是实例化、初始化A这个单例Bean。AbstractBeanFactory.doGetBean("a")
protected <T> T doGetBean(...){
...
// 标记beanName a是已经创建过至少一次的~~~ 它会一直存留在缓存里不会被移除(除非抛出了异常)
// 参见缓存Set<String> alreadyCreated = Collections.newSetFromMap(new ConcurrentHashMap<>(256))
if (!typeCheckOnly) {
markBeanAsCreated(beanName);
}
// 此时a不存在任何一级缓存中,且不是在创建中 所以此处返回null
// 此处若不为null,然后从缓存里拿就可以了(主要处理FactoryBean和BeanFactory情况吧)
Object beanInstance = getSingleton(beanName, false);
...
// 这个getSingleton方法非常关键。
//1、标注a正在创建中~
//2、调用singletonObject = singletonFactory.getObject();(实际上调用的是createBean()方法) 因此这一步最为关键
//3、此时实例已经创建完成 会把a移除整整创建的缓存中
//4、执行addSingleton()添加进去。(备注:注册bean的接口方法为registerSingleton,它依赖于addSingleton方法)
sharedInstance = getSingleton(beanName, () -> { ... return createBean(beanName, mbd, args); });
}
下面进入到最为复杂的AbstractAutowireCapableBeanFactory.createBean/doCreateBean()环节,创建A的实例
protected Object doCreateBean(){
...
// 使用构造器/工厂方法 instanceWrapper是一个BeanWrapper
instanceWrapper = createBeanInstance(beanName, mbd, args);
// 此处bean为"原始Bean" 也就是这里的A实例对象:A@1234
final Object bean = instanceWrapper.getWrappedInstance();
...
// 是否要提前暴露(允许循环依赖) 现在此处A是被允许的
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences && isSingletonCurrentlyInCreation(beanName));
// 允许暴露,就把A绑定在ObjectFactory上,注册到三级缓存`singletonFactories`里面去保存着
// Tips:这里后置处理器的getEarlyBeanReference方法会被促发,自动代理创建器在此处创建代理对象(注意执行时机 为执行三级缓存的时候)
if (earlySingletonExposure) {
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
...
// exposedObject 为最终返回的对象,此处为原始对象bean也就是A@1234,下面会有用处
Object exposedObject = bean;
// 给A@1234属性完成赋值,@Autowired在此处起作用~
// 因此此处会调用getBean("b"),so 会重复上面步骤创建B类的实例
// 此处我们假设B已经创建好了 为B@5678
// 需要注意的是在populateBean("b")的时候依赖有beanA,所以此时候调用getBean("a")最终会调用getSingleton("a"),
//此时候上面说到的getEarlyBeanReference方法就会被执行。这也解释为何我们@Autowired是个代理对象,而不是普通对象的根本原因
populateBean(beanName, mbd, instanceWrapper);
// 实例化。这里会执行后置处理器BeanPostProcessor的两个方法
// 此处注意:postProcessAfterInitialization()是有可能返回一个代理对象的,这样exposedObject 就不再是原始对象了
exposedObject = initializeBean(beanName, exposedObject, mbd);
... // 至此,相当于A@1234已经实例化完成、初始化完成(属性也全部赋值了~)
// 这一步我把它理解为校验:校验:校验是否有循环引用问题~~~~~
if (earlySingletonExposure) {
// 注意此处第二个参数传的false,表示不去三级缓存里singletonFactories再去调用一次getObject()方法了~~~
// 上面建讲到了由于B在初始化的时候,会触发A的ObjectFactory.getObject() 所以a此处已经在二级缓存earlySingletonObjects里了
// 因此此处返回A的实例:A@1234
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
// 这个等式表示,exposedObject若没有再被代理过,这里就是相等的
// 显然此处我们的a对象的exposedObject它是没有被代理过的 所以if会进去~
// 这种情况至此,就全部结束了~~~
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
// 继续以A为例,比如方法标注了@Aysnc注解,exposedObject此时候就是一个代理对象,因此就会进到这里来
//hasDependentBean(beanName)是肯定为true,因为getDependentBeans(beanName)得到的是["b"]这个依赖
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length);
// A@1234依赖的是["b"],所以此处去检查b
// 如果最终存在实际依赖的bean:actualDependentBeans不为空 那就抛出异常 证明循环引用了~
for (String dependentBean : dependentBeans) {
// 这个判断原则是:如果此时候b并还没有创建好,this.alreadyCreated.contains(beanName)=true表示此bean已经被创建过,就返回false
// 若该bean没有在alreadyCreated缓存里,就是说没被创建过(其实只有CreatedForTypeCheckOnly才会是此仓库)
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesOfType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
}
}
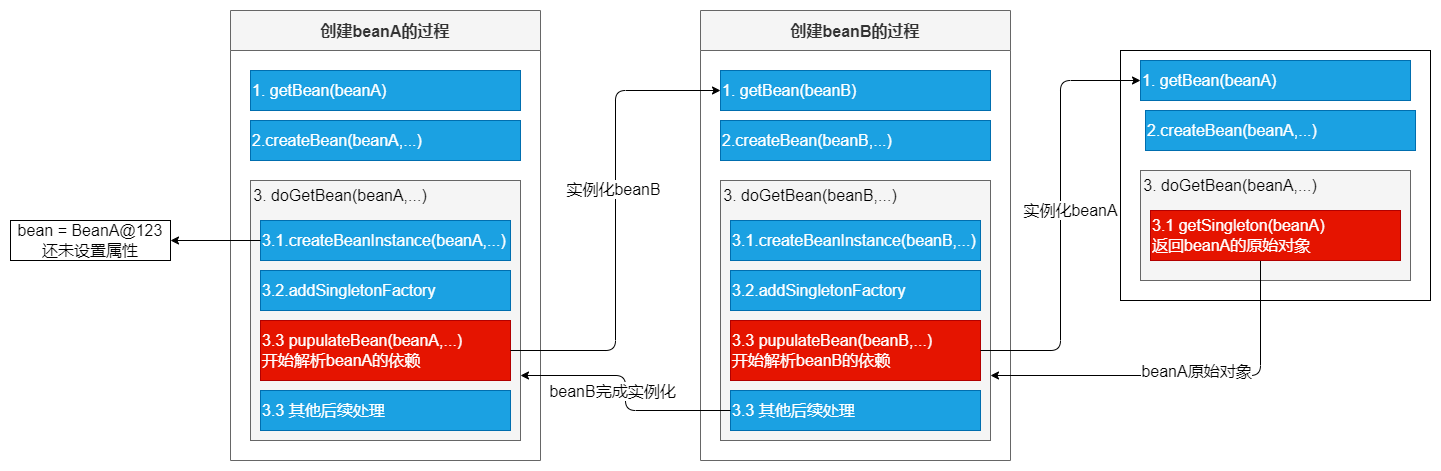
依旧以上面A、B类使用属性field注入循环依赖的例子为例,对整个流程做文字步骤总结如下:
1.使用context.getBean(A.class),旨在获取容器内的单例A(若A不存在,就会走A这个Bean的创建流程),显然初次获取A是不存在的,因此走A的创建之路~
2.实例化A(注意此处仅仅是实例化),并将它放进缓存(此时A已经实例化完成,已经可以被引用了)
3.初始化A:@Autowired依赖注入B(此时需要去容器内获取B)
4.为了完成依赖注入B,会通过getBean(B)去容器内找B。但此时B在容器内不存在,就走向B的创建之路~
5.实例化B,并将其放入缓存。(此时B也能够被引用了)
6.初始化B,@Autowired依赖注入A(此时需要去容器内获取A)
7.此处重要:初始化B时会调用getBean(A)去容器内找到A,上面我们已经说过了此时候因为A已经实例化完成了并且放进了缓存里,所以这个时候去看缓存里是已经存在A的引用了的,所以getBean(A)能够正常返回
8.B初始化成功(此时已经注入A成功了,已成功持有A的引用了),return(注意此处return相当于是返回最上面的getBean(B)这句代码,回到了初始化A的流程中~)。
9.因为B实例已经成功返回了,因此最终A也初始化成功
10.到此,B持有的已经是初始化完成的A,A持有的也是初始化完成的B
面试题
Spring为什么定三级缓存(二级缓存也可以解决循环依赖的问题)
首先当Bean未有循环依赖三级缓存是没有什么意义的,当有循环依赖但Bean并没有AOP代理,则会直接返回原对象,也没有什么意义。主要在当Bean存在循环依赖并且还有AOP代理时,三级缓存才有效果,三级缓存主要预防Bean有依赖时还可以完成代理增强
而本身Spring设计Bean的代理增强是在Bean初始化完成后的AnnotationAwareAspectJ***Creator后置处理器中完成的。提前执行则和设计思路相违背。所以三级缓存主要起预防循环依赖作用,可能是一个补丁机制
参考链接:
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注脚本之家的更多内容!