
Python通过朴素贝叶斯和LSTM分别实现新闻文本分类
作者:Alignment⁴°
一、项目背景
本项目来源于天池⼤赛,利⽤机器学习和深度学习等知识,对新闻⽂本进⾏分类。⼀共有14个分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。
最终将测试集的预测结果上传⾄⼤赛官⽹,可查看排名。评价标准为类别f1_score的均值,提交结果与实际测试集的类别进⾏对⽐。(不要求结果领先,但求真才实学)
二、数据处理与分析
本次大赛提供的材料是由csv格式编写,只需调用python中的pandas库读取即可。为了更直观的观察数据,我计算了文档的平均长度,以及每个标签分别对应的文档。(sen字典与tag字典的获取方法会在后文中展示,此步只用来呈现数据分布,运行时可先跳过)
import matplotlib.pyplot as plt
from tqdm import tqdm
import time
from numpy import *
import pandas as pd
print('count: 200000') #词典sen中,每个标签对应其所有句子的二维列表
print('average: '+str(sum([[sum(sen[i][j]) for j in range(len(sen[i]))] for i in sen])/200000))
x = []
y = []
for key,value in tag.items(): #词典tag中,每个标签对应该标签下的句子数目
x.append(key)
y.append(value)
plt.bar(x,y)
plt.show()
最终我们得到了以下结果:
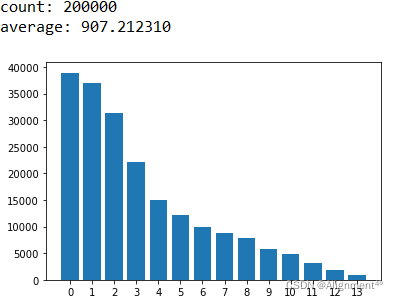
平均文档长约907词,每个标签对应的文档数从标签0至13逐个减少。
三、基于机器学习的文本分类–朴素贝叶斯
1. 模型介绍
朴素贝叶斯分类器的基本思想是利用特征项和类别的联合概率来估计给定文档的类别概率。假设文本是基于词的一元模型,即文本中当前词的出现依赖于文本类别,但不依赖于其他词及文本的长度,也就是说,词与词之间是独立的。根据贝叶斯公式,文档Doc属于Ci类的概率为
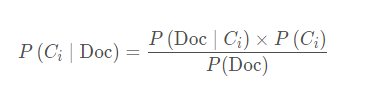
文档Doc采用TF向量表示法,即文档向量V的分量为相应特征在该文档中出现的频度,文档Doc属于Ci类文档的概率为
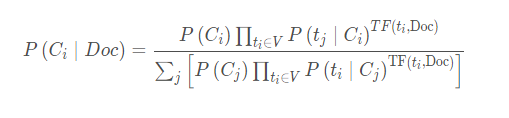
其中,TF(ti,Doc)是文档Doc中特征ti出现的频度,为了防止出现不在词典中的词导致概率为0的情况,我们取P(ti|Ci)是对Ci类文档中特征ti出现的条件概率的拉普拉斯概率估计:
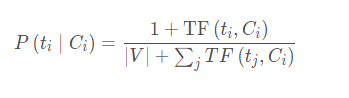
这里,TF(ti,Ci)是Ci类文档中特征ti出现的频度,|V|为特征集的大小,即文档表示中所包含的不同特征的总数目。
2. 代码结构
我直接通过python自带的open()函数读取文件,并建立对应词典,设定停用词,这里的停用词选择了words字典中出现在100000个文档以上的所有词。训练集取前19万个文档,测试集取最后一万个文档。
train_df = open('./data/train_set.csv').readlines()[1:]
train = train_df[0:190000]
test = train_df[190000:200000]
true_test = open('./data/test_a.csv').readlines()[1:]
tag = {str(i):0 for i in range(0,14)}
sen = {str(i):{} for i in range(0,14)}
words={}
stop_words = {'4149': 1, '1519': 1, '2465': 1, '7539': 1, ...... }
接着,我们需要建立标签词典和句子词典,用tqdm函数来显示进度。
for line in tqdm(train_df):
cur_line = line.split('\t')
cur_tag = cur_line[0]
tag[cur_tag] += 1
cur_line = cur_line[1][:-1].split(' ')
for i in cur_line:
if i not in words:
words[i] = 1
else:
words[i] += 1
if i not in sen[cur_tag]:
sen[cur_tag][i] = 1
else:
sen[cur_tag][i] += 1
为了便于计算,我定义了如下函数,其中mul()用来计算列表中所有数的乘积,prob_clas() 用来计算P(Ci|Doc),用probability()来计算P(ti|Ci),在probability() 函数中,我将输出结果中分子+1,分母加上字典长度,实现拉普拉斯平滑处理。
def mul(l):
res = 1
for i in l:
res *= i
return res
def prob_clas(clas):
return tag[clas]/(sum([tag[i] for i in tag]))
def probability(char,clas): #P(特征|类别)
if char not in sen[clas]:
num_char = 0
else:
num_char = sen[clas][char]
return (1+num_char)/(len(sen[clas])+len(words))
在做好所有准备工作,定义好函数后,分别对测试集中的每一句话计算十四个标签对应概率,并将概率最大的标签储存在预测列表中,用tqdm函数来显示进度。
PRED = []
for line in tqdm(true_test):
result = {str(i):0 for i in range(0,14)}
cur_line = line[:-1].split(' ')
clas = cur_tag
for i in result:
prob = []
for j in cur_line:
if j in stop_words:
continue
prob.append(log(probability(j,i)))
result[i] = log(prob_clas(i))+sum(prob)
for key,value in result.items():
if(value == max(result.values())):
pred = int(key)
PRED.append(pred)
最后把结果储存在csv文件中上传网站,提交后查看成绩。(用此方法编写的csv文件需要打开后删去第一列再上传)
res=pd.DataFrame()
res['label']=PRED
res.to_csv('test_TL.csv')
3. 结果分析
在训练前19万个文档,测试后一万个文档的过程中,我不断调整停用词取用列表,分别用TF和TF-IDF向量表示法进行了测试,结果发现使用TF表示法准确性较高,最后取用停用词为出现在十万个文档以上的词。最终得出最高效率为0.622。

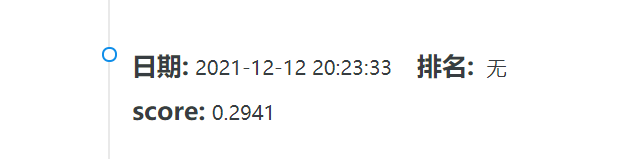
在提交至网站后,对五万个文档进行测试的F1值仅有 0.29左右,效果较差。
四、基于深度学习的文本分类–LSTM
1. 模型介绍
除了传统的机器学习方法,我使用了深度学习中的LSTM(Long Short-Term Memory)长短期记忆网络,来尝试处理新闻文本分类,希望能有更高的准确率。LSTM它是一种时间循环神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。LSTM 已经在科技领域有了多种应用。基于 LSTM 的系统可以学习翻译语言、控制机器人、图像分析、文档摘要、语音识别图像识别、手写识别、控制聊天机器人、预测疾病、点击率和股票、合成音乐等等任务。我采用深度学习库Keras来建立LSTM模型,进行文本分类。
对于卷积神经网络CNN和循环网络RNN而言,随着时间的不断增加,隐藏层一次又一次地乘以权重W。假如某个权重w是一个接近于0或者大于1的数,随着乘法次数的增加,这个权重值会变得很小或者很大,造成反向传播时梯度计算变得很困难,造成梯度爆炸或者梯度消失的情况,模型难以训练。也就是说一般的RNN模型对于长时间距离的信息记忆很差,因此LSTM应运而生。

LSTM长短期记忆网络可以更好地解决这个问题。在LSTM的一个单元中,有四个显示为黄色框的网络层,每个层都有自己的权重,如以 σ 标记的层是 sigmoid 层,tanh是一个激发函数。这些红圈表示逐点或逐元素操作。单元状态在通过 LSTM 单元时几乎没有交互,使得大部分信息得以保留,单元状态仅通过这些控制门(gate)进行修改。第一个控制门是遗忘门,用来决定我们会从单元状态中丢弃什么信息。第二个门是更新门,用以确定什么样的新信息被存放到单元状态中。最后一个门是输出门,我们需要确定输出什么样的值。总结来说 LSTM 单元由单元状态和一堆用于更新信息的控制门组成,让信息部分传递到隐藏层状态。
2. 代码结构
首先是初始数据的设定和包的调用。考虑到平均句长约900,这里取最大读取长度为平均长度的2/3,即max_len为600,之后可通过调整该参数来调整学习效率。
from tqdm import tqdm
import pandas as pd
import time
import matplotlib.pyplot as plt
import seaborn as sns
from numpy import *
from sklearn import metrics
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
from keras.models import Model
from keras.layers import LSTM, Activation, Dense, Dropout, Input, Embedding
from keras.optimizers import rmsprop_v2
from keras.preprocessing import sequence
from keras.callbacks import EarlyStopping
from keras.models import load_model
import os.path
max_words = 7549 #字典最大编号
# 可通过调节max_len调整模型效果和学习速度
max_len = 600 #句子的最大长度
stop_words = {}
接下来,我们定义一个将DataFrame的格式转化为矩阵的函数。该函数输出一个长度为600的二维文档列表和其对应的标签值。
def to_seq(dataframe):
x = []
y = array([[0]*int(i)+[1]+[0]*(13-int(i)) for i in dataframe['label']])
for i in tqdm(dataframe['text']):
cur_sentense = []
for word in i.split(' '):
if word not in stop_words: #最终并未采用停用词列表
cur_sentense.append(word)
x.append(cur_sentense)
return sequence.pad_sequences(x,maxlen=max_len),y
接下来是模型的主体函数。该函数输入测试的文档,测试集的真值,训练集和检验集,输出预测得到的混淆矩阵。具体代码介绍,见下列代码中的注释。
def test_file(text,value,train,val):
## 定义LSTM模型
inputs = Input(name='inputs',shape=[max_len])
## Embedding(词汇表大小,batch大小,每个新闻的词长)
layer = Embedding(max_words+1,128,input_length=max_len)(inputs)
layer = LSTM(128)(layer)
layer = Dense(128,activation="relu",name="FC1")(layer)
layer = Dropout(0.5)(layer)
layer = Dense(14,activation="softmax",name="FC2")(layer)
model = Model(inputs=inputs,outputs=layer)
model.summary()
model.compile(loss="categorical_crossentropy",optimizer=rmsprop_v2.RMSprop(),metrics=["accuracy"])
## 模型建立好之后开始训练,如果已经保存训练文件(.h5格式),则直接调取即可
if os.path.exists('my_model.h5') == True:
model = load_model('my_model.h5')
else:
train_seq_mat,train_y = to_seq(train)
val_seq_mat,val_y = to_seq(val)
model.fit(train_seq_mat,train_y,batch_size=128,epochs=10, #可通过epochs数来调整准确率和运算速度
validation_data=(val_seq_mat,val_y))
model.save('my_model.h5')
## 开始预测
test_pre = model.predict(text)
##计算混淆函数
confm = metrics.confusion_matrix(argmax(test_pre,axis=1),argmax(value,axis=1))
print(metrics.classification_report(argmax(test_pre,axis=1),argmax(value,axis=1)))
return confm
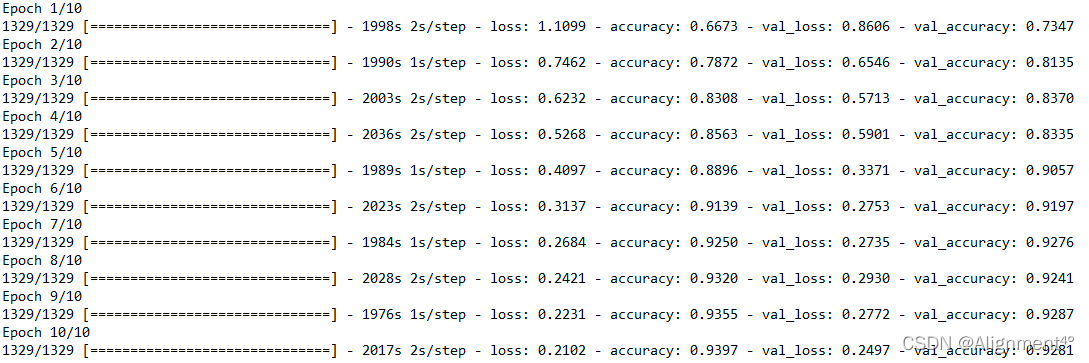
训练过程如下图所示。
为了更直观的表现结果,定义如下函数绘制图像。
def plot_fig(matrix):
Labname = [str(i) for i in range(14)]
plt.figure(figsize=(8,8))
sns.heatmap(matrix.T, square=True, annot=True,
fmt='d', cbar=False,linewidths=.8,
cmap="YlGnBu")
plt.xlabel('True label',size = 14)
plt.ylabel('Predicted label',size = 14)
plt.xticks(arange(14)+0.5,Labname,size = 12)
plt.yticks(arange(14)+0.3,Labname,size = 12)
plt.show()
return
最后,只需要通过pandas读取csv文件,按照比例分为训练集、检验集和测试集(这里选用比例为15:2:3),即可完成全部的预测过程。
def test_main():
train_df = pd.read_csv("./data/train_set.csv",sep='\t',nrows=200000)
train = train_df.iloc[0:150000,:]
test = train_df.iloc[150000:180000,:]
val = train_df.iloc[180000:,:]
test_seq_mat,test_y = to_seq(test)
Confm = test_file(test_seq_mat,test_y,train,val)
plot_fig(Confm)
在获得预测结果最高的一组参数的选取后,我们训练整个train_set文件,训练过程如下,训练之前需删除已有的训练文件(.h5),此函数中的test行可随意选取,只是为了满足test_file()函数的变量足够。此函数只是用于训练出学习效果最好的数据并储存。
def train():
train_df = pd.read_csv("./data/train_set.csv",sep='\t',nrows=200000)
train = train_df.iloc[0:170000,:]
test = train_df.iloc[0:10000,:]
val = train_df.iloc[170000:,:]
test_seq_mat,test_y = to_seq(test)
Confm = test_file(test_seq_mat,test_y,train,val)
plot_fig(Confm)
在获得最优的训练数据后,我们就可以开始预测了。我们将竞赛中提供的测试集带入模型中,加载储存好的训练集进行预测,得到预测矩阵。再将预测矩阵中每一行的最大值转化为对应的标签,储存在输出列表中即可,最后将该列表写入'test_DL.csv'文件中上传即可。(如此生成的csv文件同上一个模型一样,需手动打开删除掉第一列)
def pred_file():
test_df = pd.read_csv('./data/test_a.csv')
test_seq_mat = sequence.pad_sequences([i.split(' ') for i in tqdm(test_df['text'])],maxlen=max_len)
inputs = Input(name='inputs',shape=[max_len])
## Embedding(词汇表大小,batch大小,每个新闻的词长)
layer = Embedding(max_words+1,128,input_length=max_len)(inputs)
layer = LSTM(128)(layer)
layer = Dense(128,activation="relu",name="FC1")(layer)
layer = Dropout(0.5)(layer)
layer = Dense(14,activation="softmax",name="FC2")(layer)
model = Model(inputs=inputs,outputs=layer)
model.summary()
model.compile(loss="categorical_crossentropy",optimizer=rmsprop_v2.RMSprop(),metrics=["accuracy"])
model = load_model('my_model.h5')
test_pre = model.predict(test_seq_mat)
pred_result = [i.tolist().index(max(i.tolist())) for i in test_pre]
res=pd.DataFrame()
res['label']=pred_result
res.to_csv('test_DL.csv')
整理后,我们只需要注释掉对应的指令行即可进行训练或预测。
#如果想要训练,取消下行注释,训练之前需先删除原训练文件(.h5) #train() #如果想要查看模型效果,取消下行注释(训练集:检验集:测试集=15:2:3) # test_main() #如果想预测并生成csv文件,取消下行注释 # pred_file()
3. 结果分析
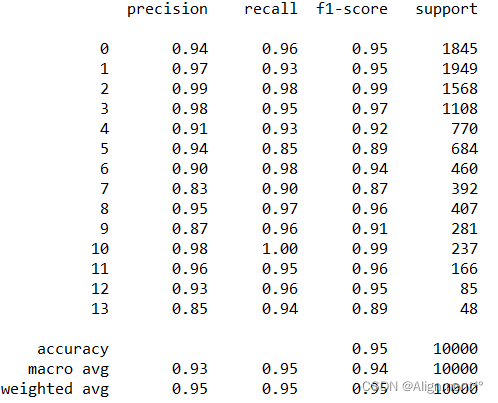
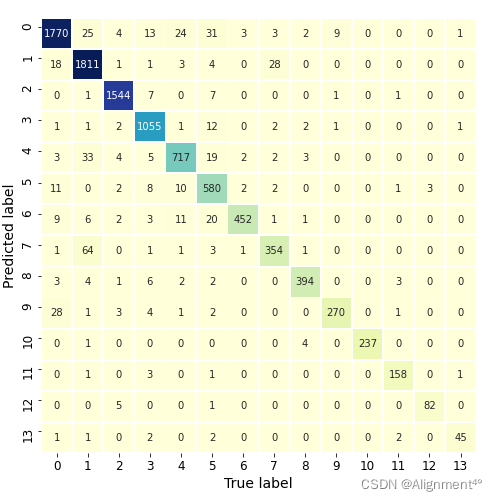
最终获得的混淆矩阵如下图所示,14个标签预测的正确率均达到了80%以上,有11个标签在90%以上,有6个标签在95%以上。
绘制出来的预测结果如下图所示,可见预测效果相当理想,每个标签的正确率都尤为可观,预测错误的文本数相比于总量非常少。
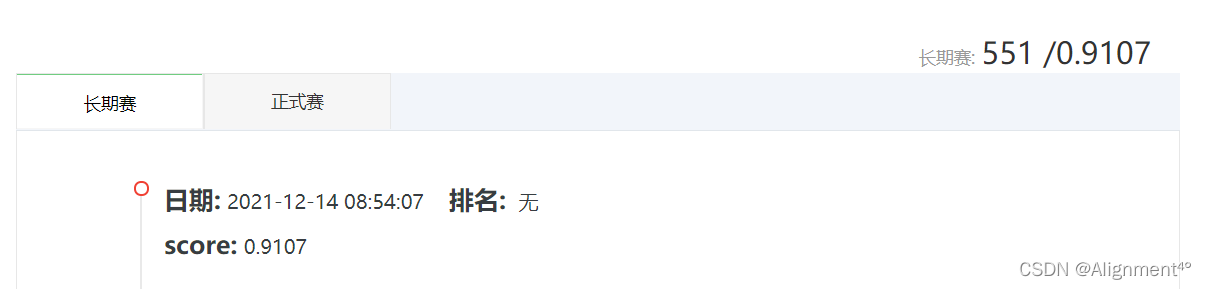
最终上传网站得到结果,F1值达90%以上,效果较好。
五、小结
本实验采用了传统机器学习和基于LSTM的深度学习两种方法对新闻文本进行了分类,在两种方法的对比下,深度学习的效果明显优于传统的机器学习,并在竞赛中取得了较好的成绩(排名551)。但LSTM仍存在问题,一方面是RNN的梯度问题在LSTM及其变种里面得到了一定程度的解决,但还是不够;另一方面,LSTM计算费时,每一个LSTM的cell里面都意味着有4个全连接层(MLP),如果LSTM的时间跨度很大,并且网络又很深,这个计算量会很大,很耗时。
探寻更好的文本分类方法一直以来都是NLP在探索的方向,希望今后可以学习更多的分类方法,更多的机器学习和深度学习模型,提高分类效率。
到此这篇关于Python通过朴素贝叶斯和LSTM分别实现新闻文本分类的文章就介绍到这了,更多相关Python文本分类内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!