
Python垃圾邮件的逻辑回归分类示例详解
作者:K_C_of
这篇文章主要给大家介绍了关于Python垃圾邮件的逻辑回归分类的相关资料,作为初学者实践文本分类是一个不错的开始,文中通过实例代码介绍的非常详细,需要的朋友可以参考下
加载垃圾邮件数据集spambase.csv(数据集基本信息:样本数: 4601,特征数量: 57, 类别:
1 为垃圾邮件,0 为非垃圾邮件),阅读并理解数据。
按以下要求处理数据集
(1)分离出仅含特征列的部分作为 X 和仅含目标列的部分作为 Y。
(2)将数据集拆分成训练集和测试集(70%和 30%)。
建立逻辑回归模型
分别用 LogisticRegression 建模。
结果比对
(1)输出测试集前 5 个样本的预测结果。
(2)计算模型在测试集上的分类准确率(=正确分类样本数/测试集总样本数)
(3)从测试集中找出模型不能正确预测的样本。
(4)对参数 penalty 分别取‘l1', ‘l2', ‘elasticnet', ‘none',对比它们在测试集上的预测性能(计算 score)。
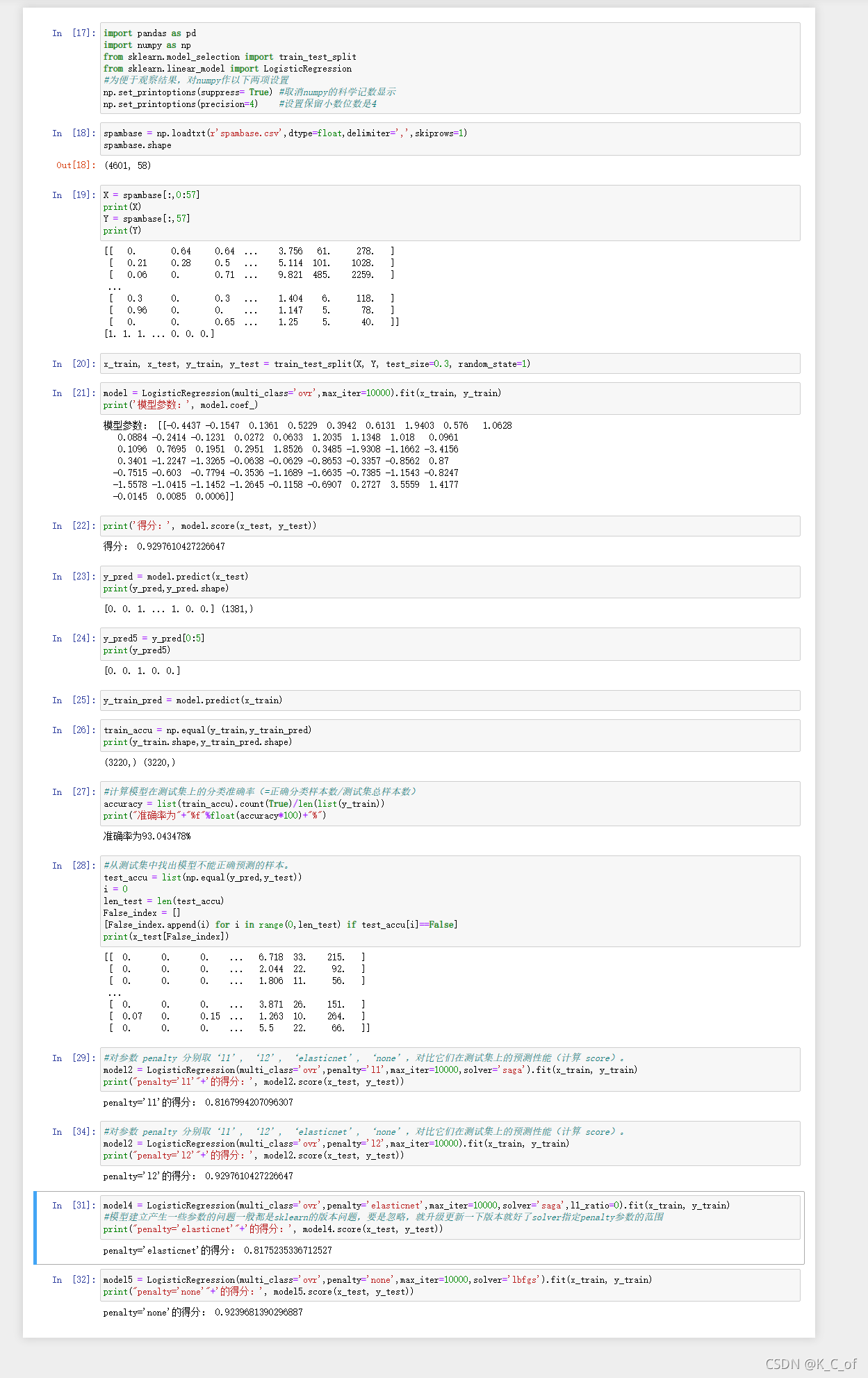
拆分特征值和目标数据前面已经可知,预测和模型得分结果也是直接使用模型的方法,下面主要是要测试准确率和找出不能正确预测的样本,以及不同的惩罚下的模型得分,主要运用到Numpy模块和列表list的函数,代码如下:
y_train_pred = model.predict(x_train)
# In[26]:
train_accu = np.equal(y_train,y_train_pred)
print(y_train.shape,y_train_pred.shape)
# In[27]:
#计算模型在测试集上的分类准确率(=正确分类样本数/测试集总样本数)
accuracy = list(train_accu).count(True)/len(list(y_train))
print("准确率为"+"%f"%float(accuracy*100)+"%")
# In[28]:
#从测试集中找出模型不能正确预测的样本。
test_accu = list(np.equal(y_pred,y_test))
i = 0
len_test = len(test_accu)
False_index = []
[False_index.append(i) for i in range(0,len_test) if test_accu[i]==False]
print(x_test[False_index])
# In[29]:
#对参数 penalty 分别取‘l1', ‘l2', ‘elasticnet', ‘none',对比它们在测试集上的预测性能(计算 score)。
model2 = LogisticRegression(multi_class='ovr',penalty='l1',max_iter=10000,solver='saga').fit(x_train, y_train)
print("penalty='l1'"+'的得分:', model2.score(x_test, y_test))
# In[33]:
#对参数 penalty 分别取‘l1', ‘l2', ‘elasticnet', ‘none',对比它们在测试集上的预测性能(计算 score)。
model2 = LogisticRegression(multi_class='ovr',penalty='l2',max_iter=10000).fit(x_train, y_train)
print("penalty='l2'"+'的得分:', model2.score(x_test, y_test))
# In[31]:
model4 = LogisticRegression(multi_class='ovr',penalty='elasticnet',max_iter=10000,solver='saga',l1_ratio=0).fit(x_train, y_train)
#模型建立产生一些参数的问题一般都是sklearn的版本问题,要是忽略,就升级更新一下版本就好了solver指定penalty参数的范围
print("penalty='elasticnet'"+'的得分:', model4.score(x_test, y_test))
# In[32]:
model5 = LogisticRegression(multi_class='ovr',penalty='none',max_iter=10000,solver='lbfgs').fit(x_train, y_train)
print("penalty='none'"+'的得分:', model5.score(x_test, y_test))
总结
到此这篇关于Python垃圾邮件的逻辑回归分类的文章就介绍到这了,更多相关Python垃圾邮件分类内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!