
python爬虫之scrapy框架详解
作者:可小v.
这篇文章主要为大家介绍了python爬虫之scrapy框架,具有一定的参考价值,感兴趣的小伙伴们可以参考一下,希望能够给你带来帮助
1.在pycharm下安装scrapy函数库 2.将安装好scrapy函数库下的路径配置到系统path的环境变量中 3.打开cmd终端输入:scrapy.exe检查是否安装成功 4.创建一个项目:scrapy startproject 项目名字 5.cd进入该目录下,创建一个spider:scrapy genspider 项目名字 网址 6.编辑settings.py文件中的USER_AGENT选项为正常的浏览器头部 7.执行这个spider:scrapy crawl 项目名字 8.如果遇到因pip版本太低导致安装不了scarpy函数库,可以先在cmd窗口输入py -m pip install --upgrade pip升级命令(前提是你的python环境下得有pip,可通过输入pip命令查看是否已安装,如未安装得去官网下载并解压至相应路径)
代码示例命令截图:

项目文件截图:
settings.py文件截图:(需要修改爬取网站的USER_AGENT)
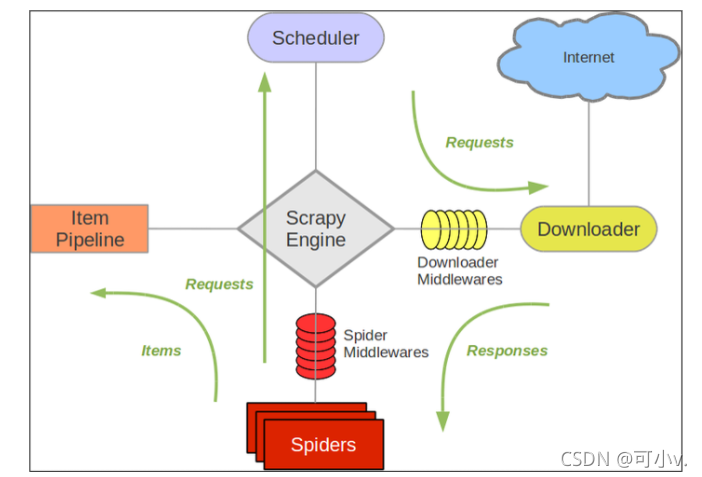
scrapy运行工作流程图:
Spiders(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)
Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理
ItemPipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间
通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注脚本之家的更多内容!