
Python爬虫实战JS逆向AES逆向加密爬取
作者:五包辣条!
一个建筑行业的堂哥为了搞一些商业数据前前后后花了1w,辣条我半个小时就能解决的事情,这就是技术的魅力!声明:爬取是的公开数据
爬取目标
网址:监管平台

工具使用
开发工具:pycharm
开发环境:python3.7, Windows10
使用工具包:requests,AES,json
涉及AES对称加密问题 需要 安装node.js环境
使用npm install 安装 crypto-js
项目思路解析
确定数据 在这个网页可以看到数据是动态返回的 但是 都是加密的 如何确定是我们需要的?

突然想到 如果我分页 是不是会直接加载第二个页面 然后查看相似度 找到第一个页面, 我真是太聪明了

数据找到了 现在开始寻找加密 但是突然发现没有 加密的关键字? 那我们通过url 下手试试 在All里面全局 搜索 query/comp/list(url后面的参数)
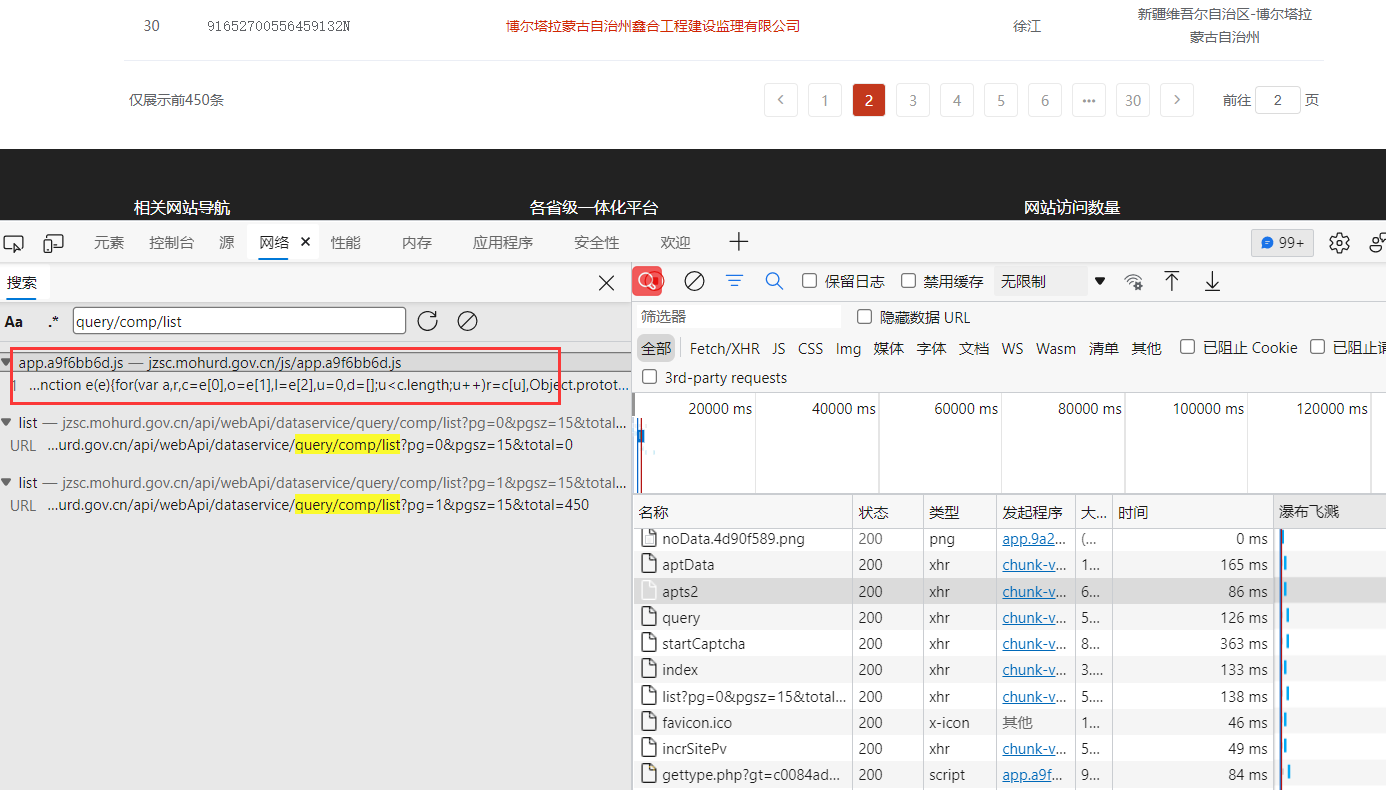
找到这个接口 鼠标右键 可以在源代码查看他


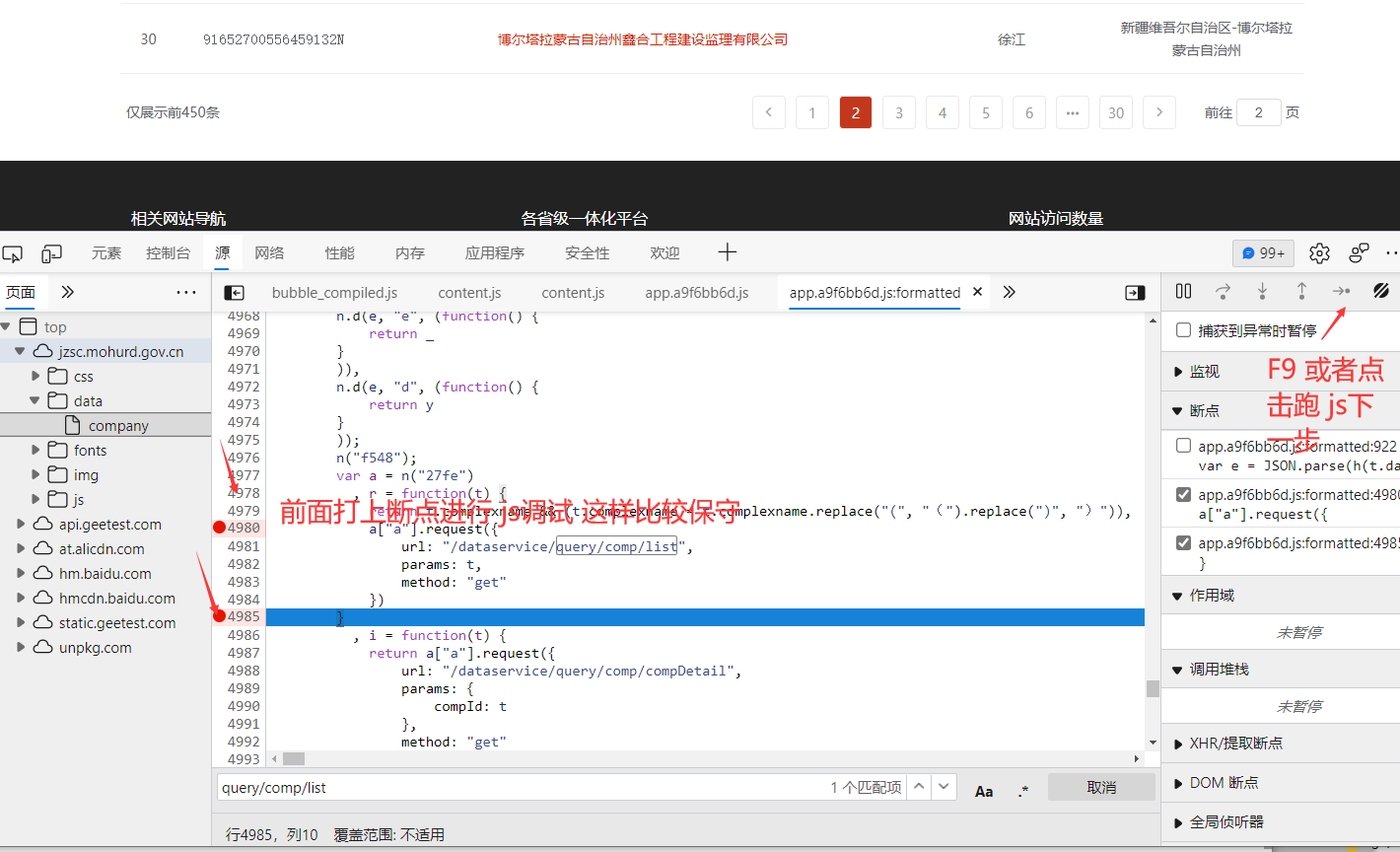
慢慢调试 中间调试太多了 我就不一一截图出来了 跑到这里 发现data 里面的参数 和我们看到的加密一致
h(t.data) 加密位置

进去h里面 (鼠标光标放到 h上面 会显示他的 js地址 如果没有显示 就是证明你还没有执行到这里 需要在前面打上断点 刷新页面调试)

发现这个采用AES加密算法 使用模型CBC模式 采用填充方式为 Pkcs7
AES.decrypt() # 参数说明 秘钥 模式 偏移值
f = 'jo8j9wGw%6HbxfFn' # 秘钥
m = '0123456789ABCDEF' # 偏移值
证明数据推导正确 在 return r.toString() 打上断点

r里面数据正常返回
简易源码分享
import requests
from Crypto.Cipher import AES
import json
url = 'http://jzsc.mohurd.gov.cn/api/webApi/dataservice/query/comp/list?pg=2&pgsz=15&total=0'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.38'
}
response = requests.get(url, headers=headers).text
f = 'jo8j9wGw%6HbxfFn' # 秘钥
m = '0123456789ABCDEF' # 偏移值
# 转码 utf-8? 字节 16进制
m = bytes(m, encoding='utf-8')
f = bytes(f, encoding='utf-8')
# 创建一个AES算法 秘钥 模式 偏移值
cipher = AES.new(f, AES.MODE_CBC, m)
# 解密
decrypt_content = cipher.decrypt(bytes.fromhex(response))
result = str(decrypt_content, encoding='utf-8')
# OKCS7 填充
length = len(result) # 字符串长度
unpadding = ord(result[length - 1]) # 得到最后一个字符串的ASCII
result = result[0:length - unpadding]
result = json.loads(result)['data']['list'] # dupms json.dumps() dict 格式 json的
# {"键":"值"}
for i in result:
print(i)
以上就是Python爬虫实战JS逆向AES逆向加密爬取的详细内容,更多关于Python爬取JS逆向AES逆向加密的资料请关注脚本之家其它相关文章!