
java面试散列表及树所对应容器类及HashMap冲突解决全面分析
作者:小张Python
散列表 Hashmap、hashtable、concurrentHashMap、hashset;
树: treemap、treeset、hashset
treeset 继承自 treemap,hashset 继承自 hashmap ;
性能分析
Map 是 Java 中的接口,Map.Entry 是 Map 的一个内部接口 Map 提供了一些常用方法,例如 keySet()、entrySet() 方法等;
Entry: key 和 value的组合,即为一个映射项<K,V>
Treemap 底层数据结构是红黑树,元素存储是有序的,因此添加元素需要循环查找 Entry 插入位置、取出元素时需要遍历才能找到合适的 Entry ,比较耗性能;treemap、treeset 对比 hashmap、hashset 优势:前者元素都以有序状态排列
HashMap 产生冲突原因及解决方法
调用hashCode() 计算 hashCode ,两个不同对象可能有相同的 hashCode ,导致冲突产生,
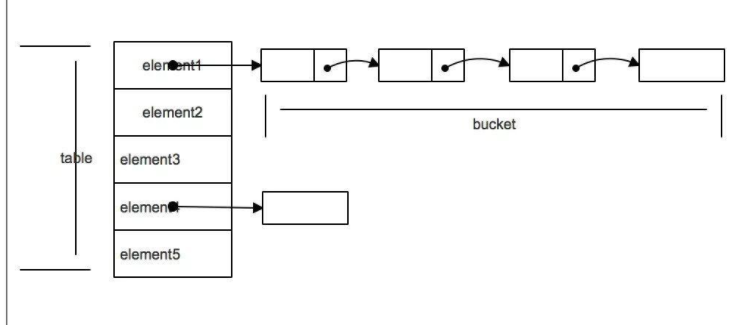
bucket ,哈希表中的数组中可以存储 hashcode 相同对象,每个bucket 都有其指定索引,系统可以根据索引快速访问该 bucket 里存储的元素
HashMap 解决冲突方法
1,开放定址法:通过探测算法,档一个槽位被占用情况下继续查找下一个;
探测算法的三种方式:
- 线性探查
- 二次探查
- 双重散列 采用两个辅助散列函数合成一个:
h1、h2为两个散列函数
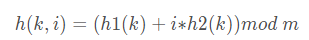
2,链地址法:数组+链表,将hash 值相同对象组织为一个链表放在 hash值对应的 bucket
3,再哈希,准备多个散列函数,当发生冲突时再选择一个散列函数进行散列,原理与双重散列相似
jdk7 与 jdk8 中HashMap的区别
发生冲突
- jdk7 中 hashMap 采用数组+链表。如果过多节点在 hash 时发生碰撞,如果要查找其中一个节点,需要
O(n)的查找时间。 - jdk8 中 hashMap 采用数组+链表/红黑树,出现 hash 冲突时会进行判断,该节点是红黑树还是量表:
如果是链表的话,数据插入链表尾部并判断链表长度是否达到某个阈值(默认阈值为 8 ),如果大于阈值,链表将转化为红黑树,时间复杂度为O(nlogn);
若是红黑树的话, 直接插入红黑树即可;
数据结构红黑树的几个性质,查询效率非常高,10亿数据进行不到30次比较就能查找到目标
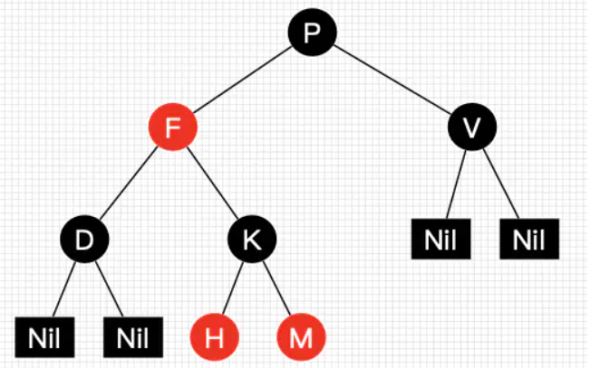
1、每个节点要么是黑色、要么是红色;
2、根节点是黑色;
3、每个叶子节点是黑色;
4、每个红色节点的两个子结点一定都是黑色;
5、任意一结点到每个叶子节点的路径都包含相同数量的黑节点;
扩容
JDK7 扩容时,在 resize() 过程中采用头插法,旧数据转移到新数组中,转移操作=正序遍历俩表,在头部依次插入,即链表逆序;多线程下 resize() 容易出现 死循环,在多线程下并发执行 put() 操作,一旦出现扩容情况,容易出现环形链表,在获取数据、遍历链表时出现死循环,即死锁转发太;
JDK 8 在扩容 resize() 时,数据转移时在新链表尾部依次插入,不会出现逆序、环形链表情况,但 jdk 1.8 仍是线程不安全的
使用建议
1,使用出初始值,避免多次扩容的性能消耗;
2,自定义对象作为 key,时需要重写 hashCode 、equals 方法;
3,多线程下, 使用 CurrentHashMap 代替 HashMap;
Reference
1, https://www.jb51.net/article/224721.htm
2, https://www.jianshu.com/p/e136ec79235c
3, https://zhuanlan.zhihu.com/p/59250175
以上就是java面试之散列表及树所对应容器类及HashMap冲突解决的详细内容,更多关于java散列表树所对应容器类HashMap冲突的资料请关注脚本之家其它相关文章!