
Spring实现HikariCP连接池的示例代码
作者:程序员阿牛
上两篇文章,我们讲到了Spring中如何配置单数据源和多数据源,配置数据源的时候,连接池有很多选择,在SpringBoot 1.0中使用的是Tomcat的DataSource,在SpringBoot 2.0中,我们使用默认连接池是HikariCP,本文讲一下HikariCP。
为什么SpringBoot 2.0要选择HikariCP来作为默认的连接池呢?
我们先看一下官网的一张对比图。
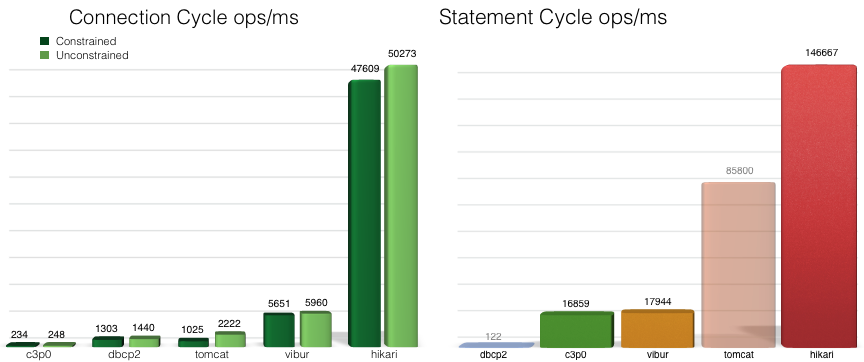
一个连接周期定义为单个DataSource.getConnection()/ Connection.close()。 一个语句周期定义为单个Connection.prepareStatement(), Statement.execute(), Statement.close()
从上图看出,HikariCP和常见的连接池相比,优势非常明显。
为什么HikariCP那么快呢?根据官网概要总结了以下几点字
- 字节码精简 :字节码级别优化(很多⽅法通过 JavaAssist ⽣成),直到编译后的字节码最少,这样,CPU缓存可以加载更多的程序代码;
- 优化代理和拦截器:减少代码,例如HikariCP的Statement proxy只有100行代码,只有BoneCP的十分之一;
- 自定义数组类型:(FastStatementList)代替ArrayList:避免每次get()调用都要进行range check,避免调用remove()时的从头到尾的扫描;
- 自定义集合类型(ConcurrentBag:提高并发读写的效率;
- 代理类的优化(⽐如,⽤ invokestatic 代替了 invokevirtual)
- 其他针对BoneCP缺陷的优化,比如对于耗时超过一个CPU时间片的方法调用的研究(但没说具体怎么优化)。
既然HikariCP那么快,接下来就看一下在Spring中怎么使用HikariCP?
在Spring Boot 2.x中
- 默认使⽤ HikariCP
- 配置 spring.datasource.hikari.* 配置
在Spring Boot 1.x中
- 默认使⽤ Tomcat 连接池,需要移除 tomcat-jdbc 依赖
- 在application.properties文件中加上spring.datasource.type=com.zaxxer.hikari.HikariDataSource
我们来看一下SpringBoot2.0怎么使用配置HikariDataSource的
下面是org.springframework.boot.autoconfigure.jdbc.DataSourceConfiguration中的相关代码
/**
* 下面的三个注解意思是当classpath中有HikariDataSource.class,并且Spring上下文中没有配置DataSource的bean
* 并且spring.datasource.type的值是com.zaxxer.hikari.HikariDataSource的时候,SpringBoot自动帮我们选择默认的连接池是HikariDataSource
*/
@ConditionalOnClass({HikariDataSource.class})
@ConditionalOnMissingBean({DataSource.class})
@ConditionalOnProperty(name = {"spring.datasource.type"},havingValue = "com.zaxxer.hikari.HikariDataSource",matchIfMissing = true)
static class Hikari {
Hikari() {
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.hikari")
HikariDataSource dataSource(DataSourceProperties properties) {
HikariDataSource dataSource = (HikariDataSource)DataSourceConfiguration.createDataSource(properties, HikariDataSource.class);
if (StringUtils.hasText(properties.getName())) {
dataSource.setPoolName(properties.getName());
}
return dataSource;
}
}
最后看看,HikariCp配置的参数有哪些?
# 不同数据源这四个配置都会用到 spring.datasource.url=jdbc:mysql://localhost:3306/test spring.datasource.username=root spring.datasource.password=123456 spring.datasource.driver-class-name=com.mysql.jdbc.Driver #以下的配置项是hikari特有的配置 # 等待连接池分配连接的最大时长(毫秒),超过这个时长还没可用的连接则发生SQLException, 默认:30秒 spring.datasource.hikari.connection-timeout=30000 # 最小连接数 spring.datasource.hikari.minimum-idle=5 # 最大连接数 spring.datasource.hikari.maximum-pool-size=15 # 自动提交 spring.datasource.hikari.auto-commit=true # 一个连接idle状态的最大时长(毫秒),超时则被释放(retired),默认:10分钟 spring.datasource.hikari.idle-timeout=600000 # 连接池名字 spring.datasource.hikari.pool-name=DatebookHikariCP # 一个连接的生命时长(毫秒),超时而且没被使用则被释放(retired),默认:30分钟 1800000ms,建议设置比数据库超时时长少60秒 spring.datasource.hikari.max-lifetime=28740000 spring.datasource.hikari.connection-test-query=SELECT 1 #以下是针对MYSQL驱动的配置参数 # 在每个连接中缓存的语句的数量。默认值为保守值25。建议将其设置为250-500之间 spring.datasource.hikari.prepStmtCacheSize = 300 # 缓存的已准备SQL语句的最大长度,默认值是256,但是往往这个长度不够用 spring.datasource.hikari.prepStmtCacheSqlLimit = 2048 # 缓存开关,如果这里设置为false,上面两个参数都不生效 spring.datasource.hikari.cachePrepStmts = true #较新版本的 MySQL 支持服务器端准备好的语句,这可以提供实质性的性能提升 spring.datasource.hikari.useServerPrepStmts = true
HikariCP官方地址: https://github.com/brettwooldridge/HikariCP/wiki
到此这篇关于Spring多个数据源配置详解的文章就介绍到这了,更多相关Spring多数据源配置内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!