
什么是推荐系统以及其基本原理使用案例
作者:开开_王子
基于内容的推荐系统
根据每部电影的内容以及用户已经评过分的电影来判断每个用户对每部电影的喜好程度,从而预测每个用户对没有看过的电影的评分。
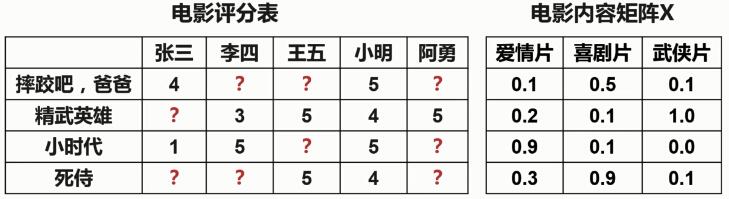
电影内容矩阵X * 用户喜好矩阵θ = 电影评分表
那么,用户喜好矩阵θ(用户对于每种不同类型电影的喜好程度)如何求解呢?
用户喜好矩阵θ的代价函数:
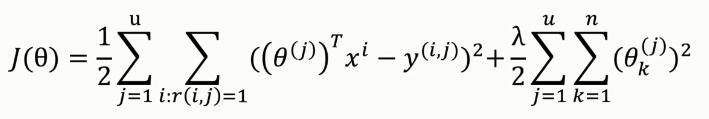
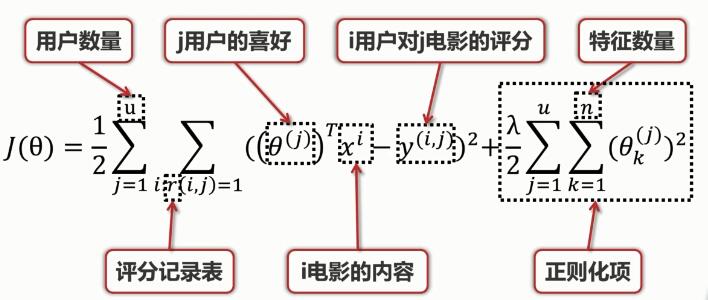
其中,正则化项为防止过拟合。
- 优点:
(1)不存在商品冷启动问题
(2)可以明确告诉用户推荐的商品包含哪些属性
- 缺点:
(1)需要对内容进行透彻的分析
(2)很少能给用户带来惊喜
(3)存在用户冷启动的问题
基于协同过滤的推荐系统
根据电影评分表和用户喜好矩阵θ,来求得电影内容矩阵X。然后,将电影内容矩阵X与用户喜好矩阵θ相乘,这样就得到了一个完整的电影评分表。
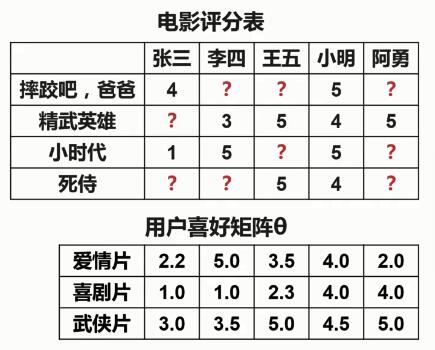
所以,基于协同过滤的电影推荐就是根据每个用户对于每种电影类型的喜好程度以及用户已经评过分的电影来推断每部电影的内容,从而预测每个用户对没有看过的电影的评分。
那么,如何求解电影内容矩阵X呢?
电影内容矩阵X的代价函数:
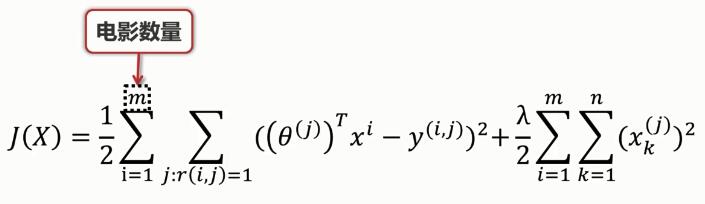
用户喜好矩阵X的获取:
(1)通过在线问卷调查来获取用户对电影的评价,但并不是所有的用户都会填写,就算填写了,也不一定全部是正确信息;
(2)通过一种更高效的方式来同时求解电影内容矩阵X和用户喜好矩阵θ.
通过前面,可以看到电影内容矩阵X和用户喜好矩阵θ,它们的第一项是相同的,因此,我们可以将这两个公式合并为一个公式来同时求解X与θ,这种方法的好处就是只用搜集用户对电影的评分。

目标是最小化这个代价函数,随机初始化X和θ,通过梯度下降法或其他优化算法求解。
(1)基于item的协同过滤
先计算商品之间的相似度,然后根据商品之间的相似度来向用户进行推荐,如:用户购买了硬盘,则很有可能向用户推荐u盘,因为硬盘和u盘具有相似性。
在基于item的协同过滤中,只需要用户对商品的评分,首先需要计算商品之间的相似度。
如何度量商品之间的相似度?
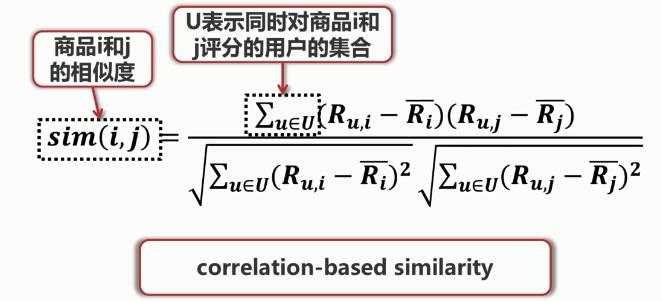
计算出商品之间的相似度之后, 我们就能够预测用户对商品的评分。

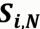 :商品i 与其他商品的相似度
:商品i 与其他商品的相似度
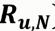 :用户u对其他商品的评分
:用户u对其他商品的评分
分母:与商品 i 相似的商品的相似度的总和
表达的是:根据用户u对其他和商品 i 相似的商品的评分来推断用户对商品 i 的评分。 当求出用户u对所有商品的预测评分后,将其进行排序,选择得分最高的商品推荐给用户。
(2)基于用户的协同过滤
基本思想:假设我们要对用户A进行推荐,首先要找到与用户相似的其他用户,看其他用户都购买过其他商品,把其他用户购买的商品推荐给用户A。
这时就需要度量用户之间的相似度,与基于item的协同过滤类似:
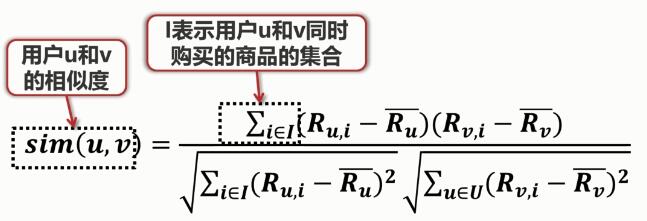
 :用户u对商品 i 的评分
:用户u对商品 i 的评分
 :用户u对这些商品评分的平均值
:用户u对这些商品评分的平均值
计算了用户之间的相似度之后就可以预测用户对商品的评分。
商品评分公式:

公式表示:根据与用户u相似的其他用户对商品i 的评分来推断用户u对商品i 的评分。 当求出用户u对所有商品的预测评分后,将其进行排序,选择得分最高的几个商品推荐给用户。
- 基于协同过滤推荐系统的优点:
(1)能够根据各个用户的历史信息推断出商品的质量
(2)不需要对商品有任何专业领域的知识
- 缺点:
(1)冷启动问题
(2)gray sheep
(3)协同过滤的复杂度会随着商品数量和用户数量的增加而增加
(4)同义词的影响
(5)shilling attack:对竞争对手的商品专门打低分,对自己的商品打高分
日常生活中,我们每个人其实都直接或者间接接触过推荐系统,也都享受过推荐系统带来的生活上便利。关于推荐系统的介绍就到这里,希望大家以后多多支持脚本之家!