
java数据结构基础:算法
作者:鱼小洲
数据结构和算法关系
虽然这个标题起的叫数据结构,但是我却总结算法。。。我不是没事找抽,只是呢,在学数据结构的时候,算法是你肯定离不开的东西。
你平时在网上看到的那些文章,在你不经意间搜的时候,是不是都是搜的数据结构与算法这七个字。这说明啥,这说明他们俩是离不开的。
给你打个比方,你想看德云社相声(我也想看),有一天你最想看小岳岳专场,想看小白专场。但是呢,走到园子里之后发现,他们今天生病了,换成了另一批人,你开心吗,不开心对不对。
所以,数据结构和算法也是这样的。没有其中的任何一个都不行。
但是,根据大学里边的概念性的东西来说,类似于我们学校,算法是单独开设课程,并不是和数据结构一起。所以,这一章还是理论。
高斯求和
想必看到这儿的人肯定对这个人早有耳闻。
如果让你来做累加求和,你肯定会写这样的代码:
int sum=0;
int n=100;
for(int i=0;i<=n;i++){
sum+=i;
}
这样做确实没错,但是问题来了,你这和循环了多少次?如果没写错的话,是101次吧。为什么呢,因为你在每次累加的时候都会去走一遍for循环,这样就会平平增加不必要的时间去运算,你有这时间,你根本就抢不到亚索。
我们直接来看这个天才当时是怎么做的。
因为sum=1+2+3+…+100。
但是呢,sum=100+99+98+…+1
如果把他们两个加起来,那就是2sum=101+101+101+…+101
一共多少个101,100个吧,那如果去除2呢,结果不就是5050了。用代码怎么写?
int i=0; int sum=0 int n=100; sum=(1+n)*n/2
这就是神童,这就是大佬,思考问题的方面都和我们不一样。
也就是说,用这种方式,我们省略掉了那100次多余的运算,只需要一次运算就能得出答案。
如果让你加到一亿呢?你想想哪种效率会更高。
算法定义
算法这个词最早是提出在公元825年的一个叫阿勒·花剌子的一个波斯数学家写的《印度数字算术》里面。
目前来说,普遍的定义就是:
算法是解决特定问题求解步骤的描述,在计算机中表现为指令的有限序列,并且每条指令表示一个或者多个操作
刚才的问题我们也看了,对于一个问题可以有多个方法解除答案。那么问题来了,有木有通用的算法?
这个答案其实就和你去医院买药一样,请问有没有能治所有病的药答案一样。
算法的特性
算法具有五个特性:输入、输出、有限、确定、可行
输入输出
这个比较好理解。算法具有零个或者多个输入。
有穷性
指的是算法在执行有限的步骤之后,自动结束而不会出现无限循环,并且每一个步骤在可接受的时间内完成。
当然,这里的有穷指的是在实际意义中合理的。
可行性
算法的每一步都是必须可行的,也就是说,每一步都能通过执行有限次数完成。
算法设计的要求
刚才我们说过,算法并不是唯一的。那我们在处理一个问题的时候,就必须要事先设计好算法才去解决问题。
正确性
算法的正确性是指算法至少应该具有输入和输出和加工厂处理无歧义性、能正确反映问题的需求、能狗得到问题得正确答案。
可读性
算法设计的另一目的就是为了方便阅读,理解和交流
你说你写一个很牛逼的代码,别人看不懂,,,怎么去承认你牛逼呢是不是
健壮性
当输入数据不合法时,算法也能做出相应的处理,而不是产生异常或者莫名奇妙的结果
时间效率高和存储量低
算法设计应该尽量满足时间效率高和存储量低的特点
这一点我迟迟没有达到。。。。
算法效率的度量方法
算法的效率指的就是算法的执行时间。那我们怎么去算一个他的执行时间呢?
最简单的方法其实就是用计算机的计时功能来计算不同算法的效率是高是低。
事后统计法
通过设计好的测试程序和数据,利用计算机计时器对不同算法编制的程序的运行时间进行比较,从而确定算法效率的高低
但是这种方法有很大的缺陷。
事前分析估算方法
在计算机程序编制前,依据统计方法对算法进行估算
经过分析发现,一个用高级程序语言编写的程序在计算机上运行时所消耗的时间取决于这些:
- 算法采用的策略、方法
- 编译产生的代码质量
- 问题的输入规模
- 机器执行指令的速度
其实你想想,这上面四条哪一条最重要?无非就是问题的输入规模。
所谓的输入规模就是输入量的大小;
我们再分析一下刚才的高斯求和;
第一种:
int sum=0; // 执行了1次
int n=100; // 执行了一次
for(int i=0;i<=n;i++){ // 执行了n+1次
sum+=i; // 执行了n次
}
第二种:
int sum=0; // 执行了一次 int n=100; // 执行了1次 sum=(1+n)*n/2; // 执行了1次
孰优孰劣,这下看得出来吧;
我们再看一个衍生算法:
int i;
int j;
int x=0;
int sum=0;
int n=100;
for(i=1;i<=n;i++){
for(j=1;j<=n;j++){
x++;
sum+=x;
}
}
这个例子很好理解,其实也就是多循环了一百次而已,那么最后算出的次数是多少呢?n²,没错吧
我们不关心程序用的什么语言,在什么机器上执行,只关心算法。最终在分析程序的运行时间时,最重要的是把程序堪称是独立于程序设计的算法或一系列步骤。
可以从问题中得到启示,同样的规模,都是输入n,求和算法的不同,使得这个运行效率也是不同;
第一种总结出来就是f(n)=n;
第二种简单了,就是f(n)=1;第三种呢?f(n)=n²
用一张图展示一下?(来源于网络)
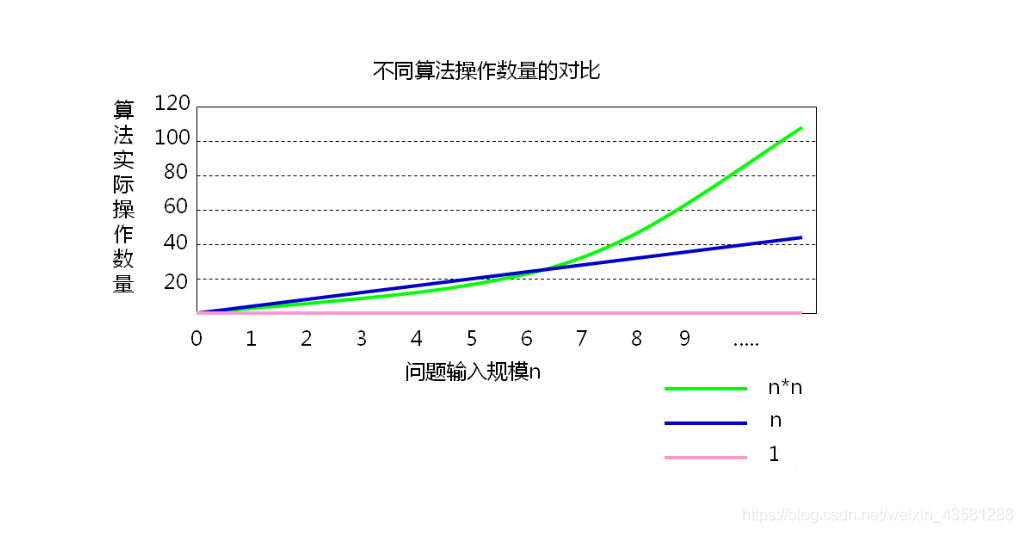
函数的渐进增长
我们现在来举个例子,两个算法a和b哪个更好。假设两个算法的输入规模都是n,算法a要做2n+3次操作(两次n循环,3次运算),算法b做3n+1次操作。
用一张表来演示一下:
| 次数 | 算法a(2n+3) | 算法a'(2n) | 算法b(3n+1) | 算法b'(3n) |
|---|---|---|---|---|
| n=1 | 5 | 2 | 4 | 3 |
| n=2 | 7 | 4 | 7 | 6 |
| n=3 | 9 | 6 | 10 | 9 |
| n=10 | 23 | 20 | 31 | 30 |
| n=100 | 203 | 200 | 301 | 300 |
看这张表,最后我们总结出算法a总体来说优于算法b
输入规模n在没有限制的情况下,只要超过一个数n,这个函数就总是大于另一个函数,我们称为是渐进增长
函数的渐进增长:给定两个函数f(n)和g(n),如果存在一个整数N使得队医所有的n>N,f(n)总是比g(n)大,那么我们说f(n)的渐进增长快于g(n)
从中我们发现,随着n的增大,后面的+3还是+1其实不怎么影响最终的结果,所以我们可以去忽略这些常数。我们再看看第二个例子:
| 次数 | 算法c(4n+8) | 算法c'(n) | 算法d(2n²+1) | 算法d'(n²) |
|---|---|---|---|---|
| n=1 | 12 | 1 | 3 | 1 |
| n=2 | 16 | 2 | 9 | 4 |
| n=3 | 20 | 3 | 19 | 9 |
| n=10 | 48 | 10 | 201 | 100 |
| n=100 | 408 | 100 | 20 001 | 10 000 |
当n<=3的时候,算法c要差于算法d,但是当n>3之后,优势就开始出来了。
所以最后总结出,与最高次项的常数并不重要。
其实根据这两个表,大致都能分析出来,某个算法,随着n的增大,他会越来越优于另一种算法,或者越来越差于另一种算法
这其实就是事前估算方法的理论依据,通过算法时间复杂度来估算时间效率
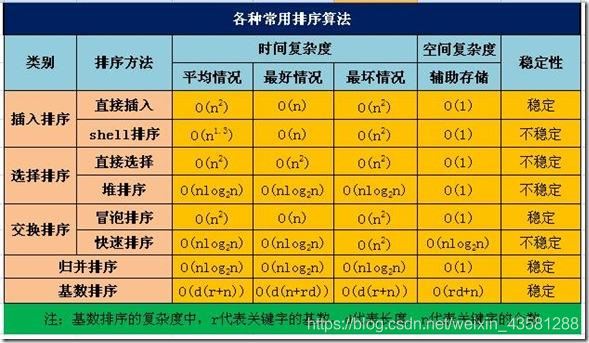
算法时间复杂度
定义:在进行算法分析时,语句的执行次数T(n)是关于问题规模n的函数,进而分析T(n)随n的变化情况而确定T(n)的数量级。算法的时间复杂度,也就是算法的时间量度,记作:T(n)=O(f(n))。他表示随着问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同,称作算法的渐进时间复杂度,简称为时间复杂度。其中f(n)是问题规模n的某个函数;
总结
本篇文章就到这里了,希望能给你带来帮助,也希望您能够多多关注脚本之家的更多内容!