
Hadoop运行时遇到java.io.FileNotFoundException错误的解决方法
作者:yoyo929
今天给大家带来的是关于Java的相关知识,文章围绕着Hadoop运行时遇到java.io.FileNotFoundException错误展开,文中有非常详细的解决方法,需要的朋友可以参考下
报错信息:
java.lang.Exception: org.apache.hadoop.mapreduce.task.reduce.Shuffle$ShuffleError: error in shuffle in localfetcher#1
at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:529)
Caused by: org.apache.hadoop.mapreduce.task.reduce.Shuffle$ShuffleError: error in shuffle in localfetcher#1
at org.apache.hadoop.mapreduce.task.reduce.Shuffle.run(Shuffle.java:134)
at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:376)
at org.apache.hadoop.mapred.LocalJobRunner$Job$ReduceTaskRunnable.run(LocalJobRunner.java:319)
at java.util.concurrent.Executors$RunnableAdapter.call(Unknown Source)
at java.util.concurrent.FutureTask.run(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
Caused by: java.io.FileNotFoundException: G:/tmp/hadoop-Ferdinand%20Wang/mapred/local/localRunner/Ferdinand%20Wang/jobcache/job_local938878567_0001/attempt_local938878567_0001_m_000000_0/output/file.out.index
at org.apache.hadoop.fs.RawLocalFileSystem.open(RawLocalFileSystem.java:198)
at org.apache.hadoop.fs.FileSystem.open(FileSystem.java:766)
at org.apache.hadoop.io.SecureIOUtils.openFSDataInputStream(SecureIOUtils.java:156)
at org.apache.hadoop.mapred.SpillRecord.<init>(SpillRecord.java:70)
at org.apache.hadoop.mapred.SpillRecord.<init>(SpillRecord.java:62)
at org.apache.hadoop.mapred.SpillRecord.<init>(SpillRecord.java:57)
at org.apache.hadoop.mapreduce.task.reduce.LocalFetcher.copyMapOutput(LocalFetcher.java:124)
at org.apache.hadoop.mapreduce.task.reduce.LocalFetcher.doCopy(LocalFetcher.java:102)
at org.apache.hadoop.mapreduce.task.reduce.LocalFetcher.run(LocalFetcher.java:85)
大概是说,reduce的过程失败了,错误发生在error in shuffle in localfetcher#1,是因为找不到在tmp/hadoop-username目录下的一个文件导致。
原因:
电脑用户名含有空格
G:/tmp/hadoop-Ferdinand%20Wang/mapred/local/localRunner/Ferdinand%20Wang/jobcache/job_local938878567_0001/attempt_local938878567_0001_m_000000_0/output/file.out.index
到具体目录看果然找不到这个文件,问题就出在这个%20其实是空格,但是这里不允许出现空格。所以我们要修改用户名称才能解决这个问题。
虽然之前在hadoop-env.cmd这个文件中修改了,用双引号的方式可以不出现空格可以让hadoop正常启动,但是治标不治本啊。还是修改一下用户名,改了以后这个就还是用username就可以。
@rem A string representing this instance of hadoop. %USERNAME% by default. set HADOOP_IDENT_STRING=%USERNAME%
修改username的方法:
1、【win】+【R】快捷键调出运行;
2、输入netplwiz,再点击确定;
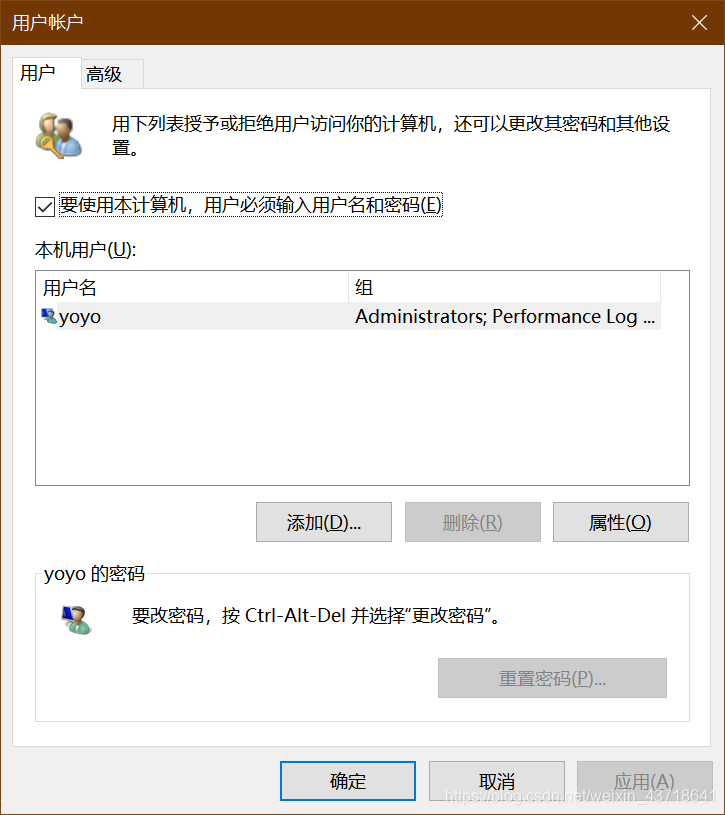
3、打开用户账户,双击;
4、输入您想要改的名字;
5、点击右下角的【确定】按钮之后,弹出警告,点击【是】即可。
6、重启电脑。(一定要重启)
重新启动,发现新上传的这里也改了。
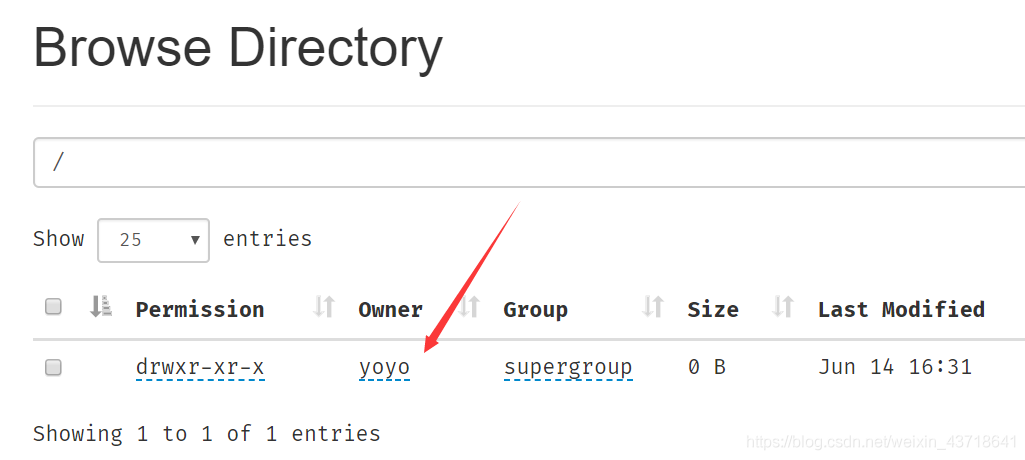
到此这篇关于Hadoop运行时遇到java.io.FileNotFoundException错误的解决方法的文章就介绍到这了,更多相关Hadoop运行错误内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!