
pytorch自定义不可导激活函数的操作
作者:Luna_Lovegood_001
这篇文章主要介绍了pytorch自定义不可导激活函数的操作,具有很好的参考价值,希望大家有所帮助。如有错误或未考虑完全的地方,望不吝赐教
pytorch自定义不可导激活函数
今天自定义不可导函数的时候遇到了一个大坑。
首先我需要自定义一个函数:sign_f
import torch
from torch.autograd import Function
import torch.nn as nn
class sign_f(Function):
@staticmethod
def forward(ctx, inputs):
output = inputs.new(inputs.size())
output[inputs >= 0.] = 1
output[inputs < 0.] = -1
ctx.save_for_backward(inputs)
return output
@staticmethod
def backward(ctx, grad_output):
input_, = ctx.saved_tensors
grad_output[input_>1.] = 0
grad_output[input_<-1.] = 0
return grad_output
然后我需要把它封装为一个module 类型,就像 nn.Conv2d 模块 封装 f.conv2d 一样,于是
import torch
from torch.autograd import Function
import torch.nn as nn
class sign_(nn.Module):
# 我需要的module
def __init__(self, *kargs, **kwargs):
super(sign_, self).__init__(*kargs, **kwargs)
def forward(self, inputs):
# 使用自定义函数
outs = sign_f(inputs)
return outs
class sign_f(Function):
@staticmethod
def forward(ctx, inputs):
output = inputs.new(inputs.size())
output[inputs >= 0.] = 1
output[inputs < 0.] = -1
ctx.save_for_backward(inputs)
return output
@staticmethod
def backward(ctx, grad_output):
input_, = ctx.saved_tensors
grad_output[input_>1.] = 0
grad_output[input_<-1.] = 0
return grad_output
结果报错
TypeError: backward() missing 2 required positional arguments: 'ctx' and 'grad_output'
我试了半天,发现自定义函数后面要加 apply ,详细见下面
import torch
from torch.autograd import Function
import torch.nn as nn
class sign_(nn.Module):
def __init__(self, *kargs, **kwargs):
super(sign_, self).__init__(*kargs, **kwargs)
self.r = sign_f.apply ### <-----注意此处
def forward(self, inputs):
outs = self.r(inputs)
return outs
class sign_f(Function):
@staticmethod
def forward(ctx, inputs):
output = inputs.new(inputs.size())
output[inputs >= 0.] = 1
output[inputs < 0.] = -1
ctx.save_for_backward(inputs)
return output
@staticmethod
def backward(ctx, grad_output):
input_, = ctx.saved_tensors
grad_output[input_>1.] = 0
grad_output[input_<-1.] = 0
return grad_output
问题解决了!
PyTorch自定义带学习参数的激活函数(如sigmoid)
有的时候我们需要给损失函数设一个超参数但是又不想设固定阈值想和网络一起自动学习,例如给Sigmoid一个参数alpha进行调节
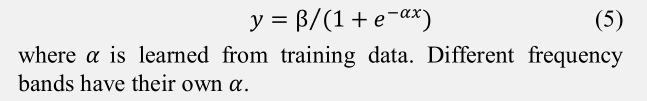
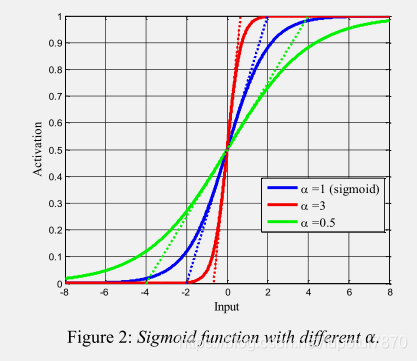
函数如下:
import torch.nn as nn
import torch
class LearnableSigmoid(nn.Module):
def __init__(self, ):
super(LearnableSigmoid, self).__init__()
self.weight = torch.nn.Parameter(torch.FloatTensor(1), requires_grad=True)
self.reset_parameters()
def reset_parameters(self):
self.weight.data.fill_(1.0)
def forward(self, input):
return 1/(1 + torch.exp(-self.weight*input))
验证和Sigmoid的一致性
class LearnableSigmoid(nn.Module):
def __init__(self, ):
super(LearnableSigmoid, self).__init__()
self.weight = torch.nn.Parameter(torch.FloatTensor(1), requires_grad=True)
self.reset_parameters()
def reset_parameters(self):
self.weight.data.fill_(1.0)
def forward(self, input):
return 1/(1 + torch.exp(-self.weight*input))
Sigmoid = nn.Sigmoid()
LearnSigmoid = LearnableSigmoid()
input = torch.tensor([[0.5289, 0.1338, 0.3513],
[0.4379, 0.1828, 0.4629],
[0.4302, 0.1358, 0.4180]])
print(Sigmoid(input))
print(LearnSigmoid(input))
输出结果
tensor([[0.6292, 0.5334, 0.5869],
[0.6078, 0.5456, 0.6137],
[0.6059, 0.5339, 0.6030]])
tensor([[0.6292, 0.5334, 0.5869],
[0.6078, 0.5456, 0.6137],
[0.6059, 0.5339, 0.6030]], grad_fn=<MulBackward0>)
验证权重是不是会更新
import torch.nn as nn
import torch
import torch.optim as optim
class LearnableSigmoid(nn.Module):
def __init__(self, ):
super(LearnableSigmoid, self).__init__()
self.weight = torch.nn.Parameter(torch.FloatTensor(1), requires_grad=True)
self.reset_parameters()
def reset_parameters(self):
self.weight.data.fill_(1.0)
def forward(self, input):
return 1/(1 + torch.exp(-self.weight*input))
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.LSigmoid = LearnableSigmoid()
def forward(self, x):
x = self.LSigmoid(x)
return x
net = Net()
print(list(net.parameters()))
optimizer = optim.SGD(net.parameters(), lr=0.01)
learning_rate=0.001
input_data=torch.randn(10,2)
target=torch.FloatTensor(10, 2).random_(8)
criterion = torch.nn.MSELoss(reduce=True, size_average=True)
for i in range(2):
optimizer.zero_grad()
output = net(input_data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
print(list(net.parameters()))
输出结果
tensor([1.], requires_grad=True)]
[Parameter containing:
tensor([0.9979], requires_grad=True)]
[Parameter containing:
tensor([0.9958], requires_grad=True)]
会更新~
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。