
Pytorch GPU内存占用很高,但是利用率很低如何解决
作者:Golden-sun
1.GPU 占用率,利用率
输入nvidia-smi来观察显卡的GPU内存占用率(Memory-Usage),显卡的GPU利用率(GPU-util)
GPU内存占用率(Memory-Usage) 往往是由于模型的大小以及batch size的大小,来影响这个指标 显卡的GPU利用率(GPU-util) 往往跟代码有关,有更多的io运算,cpu运算就会导致利用率变低。
比如打印loss, 输出图像,等等
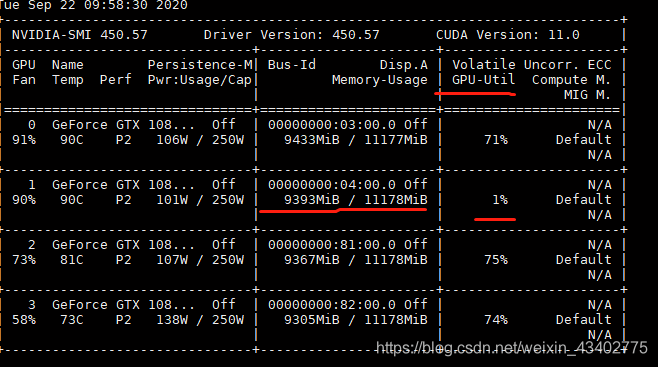
这个时候发现,有一块卡的利用率经常跳到1%,而其他三块卡经常维持在70%以上
2.原因分析
当没有设置好CPU的线程数时,Volatile GPU-Util参数是在反复的跳动的,0%,20%,70%,95%,0%。
这样停息1-2 秒然后又重复起来。其实是GPU在等待数据从CPU传输过来,当从总线传输到GPU之后,GPU逐渐起计算来,利用率会突然升高,但是GPU的算力很强大,0.5秒就基本能处理完数据,所以利用率接下来又会降下去,等待下一个batch的传入。
因此,这个GPU利用率瓶颈在内存带宽和内存介质上以及CPU的性能上面。
最好当然就是换更好的四代或者更强大的内存条,配合更好的CPU。
3.解决方法:
(1)为了提高利用率,首先要将num_workers(线程数)设置得体,4,8,16是几个常选的几个参数。本人测试过,将num_workers设置的非常大,例如,24,32,等,其效率反而降低,因为模型需要将数据平均分配到几个子线程去进行预处理,分发等数据操作,设高了反而影响效率。当然,线程数设置为1,是单个CPU来进行数据的预处理和传输给GPU,效率也会低。其次,当你的服务器或者电脑的内存较大,性能较好的时候,建议打开pin_memory打开,就省掉了将数据从CPU传入到缓存RAM里面,再给传输到GPU上;为True时是直接映射到GPU的相关内存块上,省掉了一点数据传输时间。
(2) 另外的一个方法是,在PyTorch这个框架里面,数据加载Dataloader上做更改和优化,包括num_workers(线程数),pin_memory,会提升速度。解决好数据传输的带宽瓶颈和GPU的运算效率低的问题。在TensorFlow下面,也有这个加载数据的设置。
(3) 修改代码(我遇到的问题)
每个iteration 都写文件了,这个就会导致cpu 一直运算,GPU 等待

造成GPU利用率低还有其他原因
1. CPU数据读取更不上:读到内存+多线程+二进制文件(比如tf record)
2. GPU温度过高,使用功率太大:每次少用几个GPU,降低功耗(但是多卡的作用何在?)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。