
Java基础之自定义类加载器
作者:SmallSweets
应该有很多小伙伴还不了解Java自定义类加载器吧,下文中有对Java自定义类加载器非常详细的描述,还有小伙伴们最喜欢的代码环节,需要的朋友可以参考下
一、类加载器关系
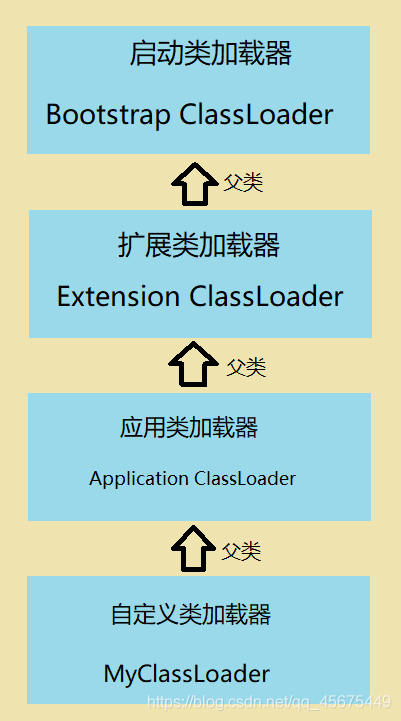
自定义类加载器
创建一个类继承ClassLoader类,同时重写findClass方法,用于判断当前类的class文件是否已被加载
二、基于本地class文件的自定义类加载器
本地class文件路径

自定义类加载器:
//创建自定义加载器类继承ClassLoader类
public class MyClassLoader extends ClassLoader{
// 包路径
private String Path;
// 构造方法,用于初始化Path属性
public MyClassLoader(String path) {
this.Path = path;
}
// 重写findClass方法,参数name表示要加载类的全类名(包名.类名)
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
System.out.println("findclass方法执行");
// 检查该类的class文件是否已被加载,如果已加载则返回class文件(字节码文件)对象,如果没有加载返回null
Class<?> loadedClass = findLoadedClass(name);
// 如果已加载直接返回该类的class文件(字节码文件)对象
if (loadedClass != null){
return loadedClass;
}
// 字节数组,用于存储class文件的字节流
byte[] bytes = null;
try {
// 获取class文件的字节流
bytes = getBytes(name);
} catch (Exception e) {
e.printStackTrace();
}
if (bytes != null){
// 如果字节数组不为空,则将class文件加载到JVM中
System.out.println(bytes.length);
// 将class文件加载到JVM中,返回class文件对象
Class<?> aClass = this.defineClass(name, bytes, 0, bytes.length);
return aClass;
}else {
throw new ClassNotFoundException();
}
}
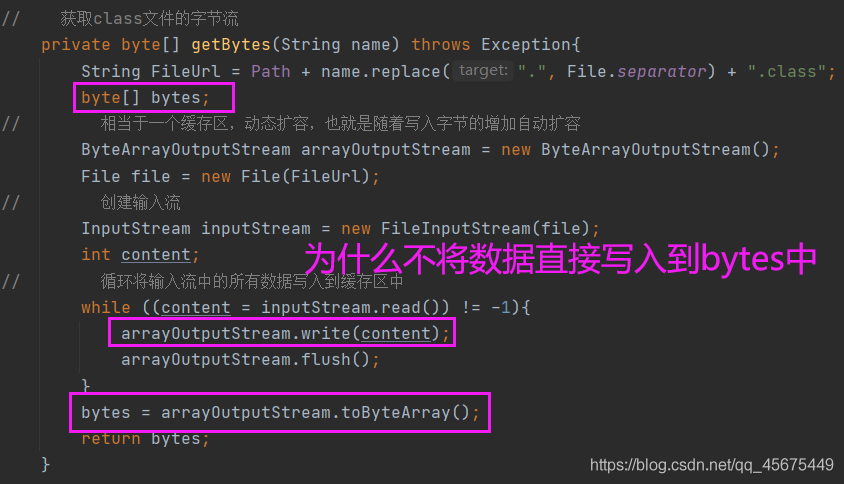
// 获取class文件的字节流
private byte[] getBytes(String name) throws Exception{
// 拼接class文件路径 replace(".",File.separator) 表示将全类名中的"."替换为当前系统的分隔符,File.separator返回当前系统的分隔符
String FileUrl = Path + name.replace(".", File.separator) + ".class";
byte[] bytes;
// 相当于一个缓存区,动态扩容,也就是随着写入字节的增加自动扩容
ByteArrayOutputStream arrayOutputStream = new ByteArrayOutputStream();
File file = new File(FileUrl);
// 创建输入流
InputStream inputStream = new FileInputStream(file);
int content;
// 循环将输入流中的所有数据写入到缓存区中
while ((content = inputStream.read()) != -1){
arrayOutputStream.write(content);
arrayOutputStream.flush();
}
bytes = arrayOutputStream.toByteArray();
return bytes;
}
}
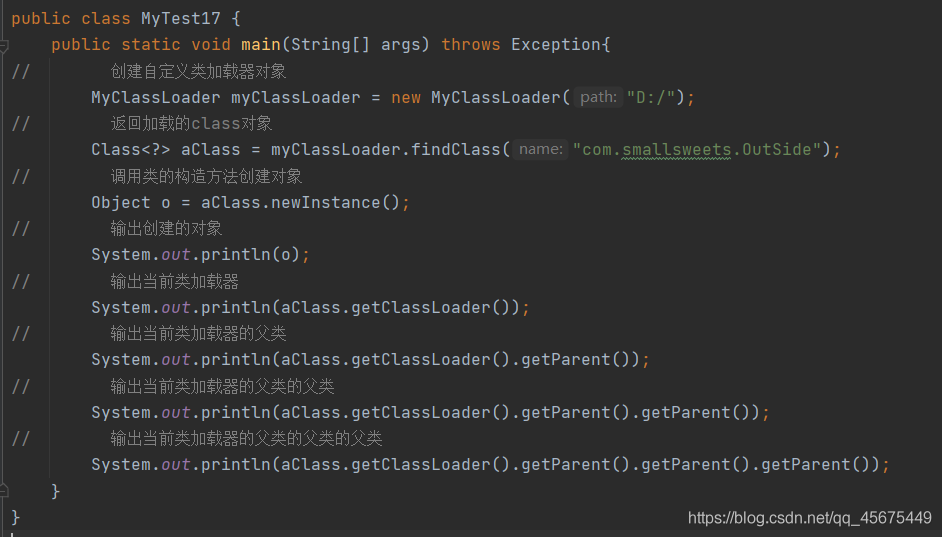
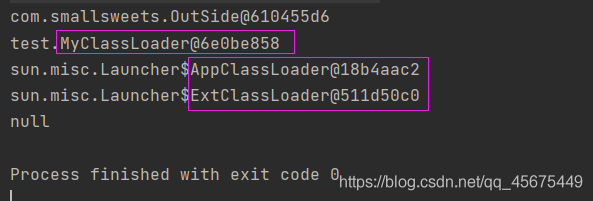
测试类
三、遇到的问题
在获取class文件字节流的getBytes方法中,为什么不将输入流中的所有数据直接写入到bytes中,而是要先写入到ByteArrayOutputStream中?如下:
现在我们尝试将数据直接写入到bytes中,如下:
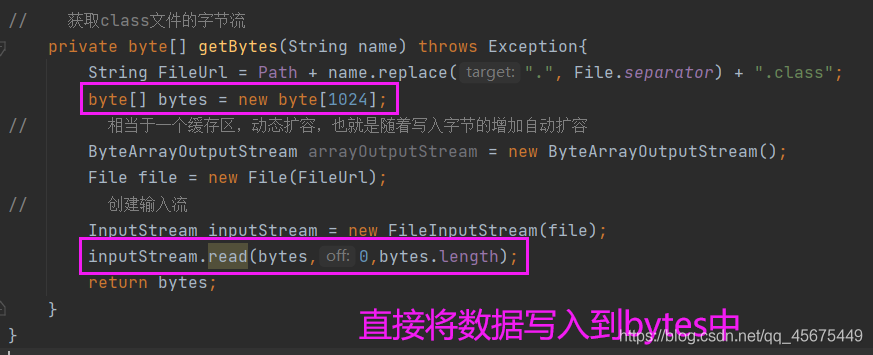
但在运行时报错:
Extra bytes at the end of class file com/smallsweets/OutSide

这是为什么呢?个人理解如下:
看报错提示Extra bytes at the end of:在文件的最后有多余的字节
查看class文件的大小
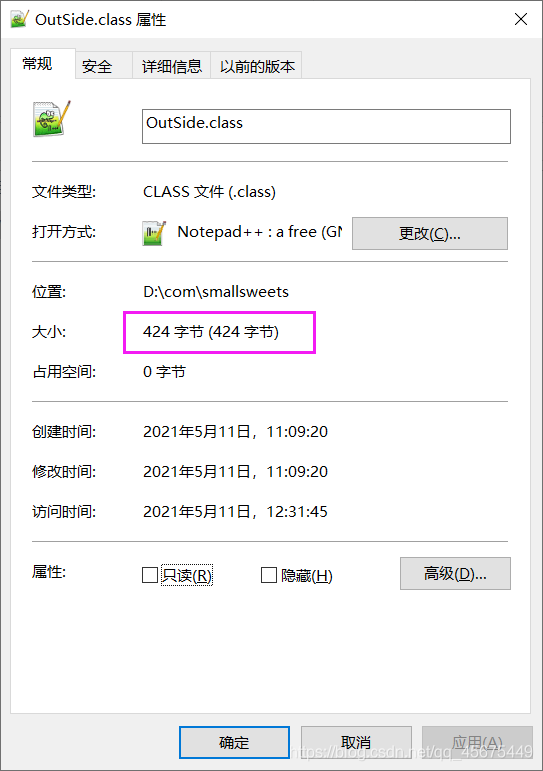
但是字节数组在初始化时指定的大小是1024,多余位置的字节是0,所以就出现了多余字节的情况
解决方法是:我们可以在初始化数组时将数组的大小指定为和class文件相同大小,如下:
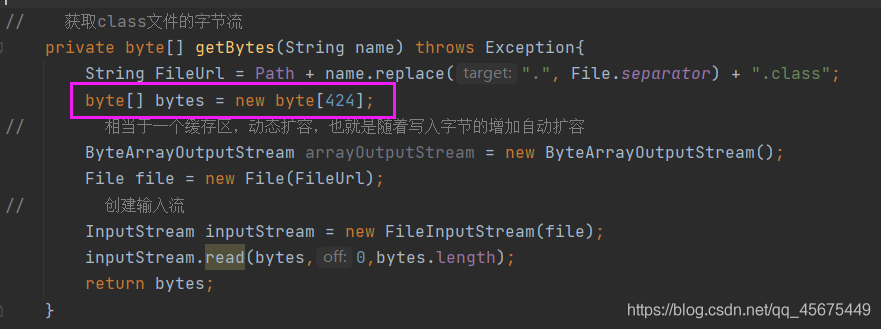
这样就可以解决了,虽然可以解决,但如果每次加载类时都要修改未免有些麻烦,所以这里我们直接使用ByteArrayOutputStream,因为它是动态扩容的,也就是大小是随写入数据的多少而动态变化的不会出现多余字节的情况
四、基于网络(url)class文件的自定义类加载器
class文件路径

自定义类加载器:
public class MyUrlClassLoader extends ClassLoader {
private String Path;
public MyUrlClassLoader(String path) {
this.Path = path;
}
// 参数name表示全类名(包名.类名)
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
// 判断该类的class文件是否已加载,已加载直接返回class文件对象,没有加载返回null
Class<?> loadedClass = this.findLoadedClass(name);
if (loadedClass != null){
return loadedClass;
}
byte[] bytes = null;
try {
// 获取网络class文件的字节数组
bytes = getBytes(Path);
} catch (Exception e) {
e.printStackTrace();
}
// 如果字节数组不为空,将class文件加载到JVM中
if (bytes != null){
// 将class文件加载到JVM中,参数(全类名,字节数组,起始位置,长度)
Class<?> aClass = this.defineClass(name, bytes, 0, bytes.length);
return aClass;
}else {
throw new ClassNotFoundException();
}
}
// 获取网络class文件的字节流,参数为class文件的url
private byte[] getBytes(String fileUrl) throws Exception {
byte[] bytes;
// 创建url对象
URL url = new URL(fileUrl);
HttpURLConnection httpURLConnection = (HttpURLConnection) url.openConnection();
// 连接url
httpURLConnection.connect();
// 创建输入流,获取网络中class文件的字节流
InputStream inputStream = httpURLConnection.getInputStream();
// 相当于缓存区,动态扩容
ByteArrayOutputStream arrayOutputStream = new ByteArrayOutputStream();
int content;
// 循环将输入流中的所有数据写入到缓存区中
while ((content = inputStream.read()) != -1){
arrayOutputStream.write(content);
arrayOutputStream.flush();
}
bytes = arrayOutputStream.toByteArray();
return bytes;
}
}
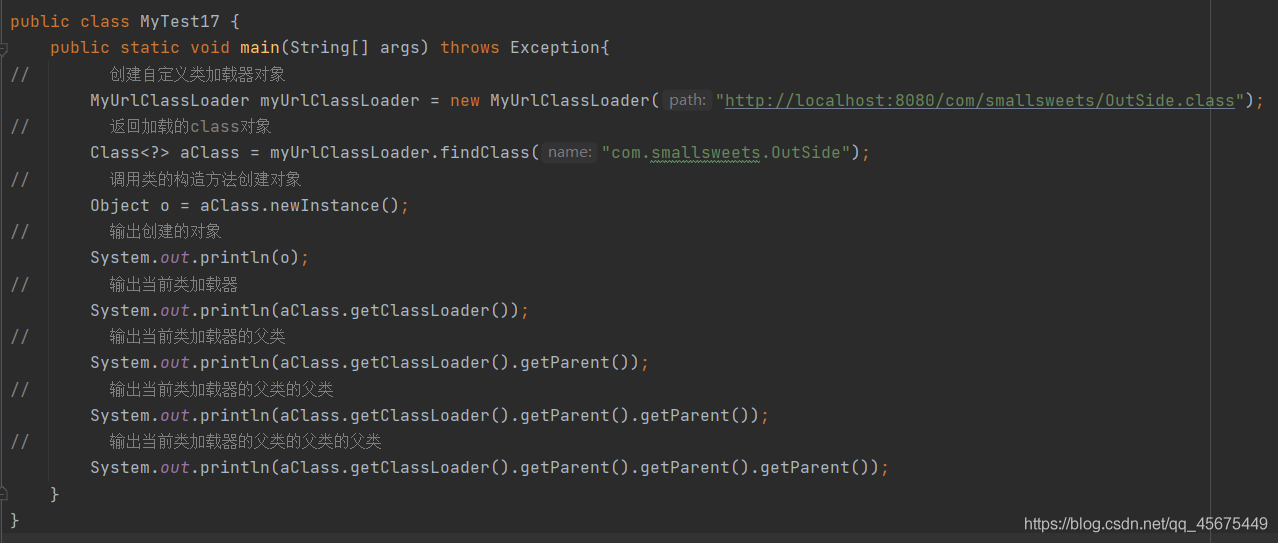
测试类
到此这篇关于Java基础之自定义类加载器的文章就介绍到这了,更多相关Java自定义类加载器内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!