
python字符串常规操作大全
作者:火星来的小怪兽,
拼接字符串
- 使用“+”运算符可完成对多个字符串的拼接,“+”运算符可以连接多个字符串并产生一个字符串对象。
- 字符串不允许直接与其他类型数据拼接。
- 如果要用来和其他类型拼接,先用str()函数转换成字符串类型。
str1 = 'Hello World' str2 = '你好,世界' print(str1+str2) num = 2021 print(str1+str2+str(num))
计算字符串长度
由于不同的字符所占字节数不同,所以要计算字符串长度,需先了解字符所占字节数。在python中,数字、英文、小数点、下划线和空格占一个字节:一个汉字可能占2-4个字节,具体根据采用的编码决定。汉子在GBK/GB2312编码中占2个字节,UTF-8/Unicode编码中一般占用3或4个字节。python默认为UTF-8编码,一般一个汉字占3个字节。
str1 = '人生苦短,我用python!' print(len(str1)) #结果为14
默认情况下,len函数计算字符串长度,不区分英文、数字和汉字,所有字符按一个字符计算。
注:
在实际开发中,有时需要获取字符串实际所占字节数,这时可以使用encode()方法进行编码后获取。
str1 = '人生苦短,我用python!'
print(len(str1.encode())) #UTF-8结果为28
print(len(str1.encode('gbk'))) #gbk结果为21
截取字符串
语法格式:string[start : end : step]
string:表示截取的字符串;
start:表示要截取的第一个索引(包括该字符),没用默认为0;
end:表示要截取的最好一个字符的索引(不包括该字符),没有默认字符串长度;
step:表示切片的步长,如果省略,默认为1;
进行截取时,如果指定索引不存在,则会抛出异常。
programer_1 = '你知道我的生日吗?' # 程序员甲问程序员乙的台词
print('程序员甲说:',programer_1) # 输出程序员甲的台词
programer_2 = '输入你的身份证号码。' # 程序员乙的台词
print('程序员乙说:',programer_2) # 输出程序员乙的台词
idcard = '123456199006277890' # 定义保存身份证号码的字符串
print('程序员甲说:',idcard) # 程序员乙说出身份证号码
birthday = idcard[6:10] + '年' + idcard[10:12] + '月' + idcard[12:14] + '日' # 截取生日
print('程序员乙说:','你是' + birthday + '出生的,所以你的生日是' + birthday[5:]) # 输出程序员乙的生日
分割字符串
语法格式:string.split(sep,maxsplit)
string:指定要分割的字符串;
sep:指定分隔符,可以包含多个字符,默认为None,即空字符(包括空格、换行“\n”,制表符“\t”等);
maxsplit:可选参数,用于指定分割的次数,如果不指定或者为-1,则分割次数没用限制,否则返回结果的元素个数,个数最多为maxsplit+1;
返回值是字符串列表;
str1 = '分割一个字符串 >>> http://www.baidu.com'
print('原字符串:',str1)
list1 = str1.split()
list2 = str1.split('>>>')
list3 = str1.split('.')
list4 = str1.split(' ',4) #用空格进行分割,只分割前4个空格
print(str(list1)+'\n'+str(list2)+'\n'str(list3)+'\n'str(list4))
list5 = str1.split('>')
print(list5)
合并字符串
语法格式:strnew = string.join(iterable)
strnew:表示合并生成的新字符串;
string:字符串类型,用于指定合并时的分隔符;
iterable: 可迭代对象,比如列表,字符串,元组等。
list_friend = ['扎克伯格','俞敏洪','马云','马化腾'] # 好友列表
str_friend = ' @'.join(list_friend) # 用空格+@符号进行连接
at = '@'+str_friend # 由于使用join()方法合并时,第一个元素前不加分隔符,所以需要在前面加上@符号
print('您要@的好友:',at)
检索字符串
语法格式:str.count(sub[,start[,end]])
用于检索指定字符串在另一个字符串中出现的次数
str:表示原字符串;
sub:表示要检索的子字符串;
start:可选参数,表示检索范围的起始位置的索引,如果不指定,则从头开始检索;
end:可选参数,表示检索范围的结束位置的索引,如果不指定,则一直检索打末尾。
find()方法
语法格式:str.find(sub[,start[,end]])
用于检索是否包含指定的子字符串。
str:表示原字符串;
sub:表示要检索的子字符串;
start:可选参数,表示检索范围的起始位置的索引,如果不指定,则从头开始检索;
end:可选参数,表示检索范围的结束位置的索引,如果不指定,则一直检索打末尾。
补充:
如果只需要判断存在可以不用find用in,如果没找到则会返回-1,如果想从右边往左边找,可以用rfind()方法。
index()方法
语法格式:str.index(sub[,start[,end]])
index()方法和find()方法类似,用于检索是否包含指定的子字符串,区别是如果不存在会抛出
str:表示原字符串;
sub:表示要检索的子字符串;
start:可选参数,表示检索范围的起始位置的索引,如果不指定,则从头开始检索;
end:可选参数,表示检索范围的结束位置的索引,如果不指定,则一直检索打末尾。
startswith()方法
语法格式:str.startswith(sub[,start[,end]])
用于检索字符串是否是以指定子字符串开头,是返回True,不是返回False
str:表示原字符串;
sub:表示要检索的子字符串;
start:可选参数,表示检索范围的起始位置的索引,如果不指定,则从头开始检索;
end:可选参数,表示检索范围的结束位置的索引,如果不指定,则一直检索打末尾索打末尾。
endswith()方法
语法格式:str.endswith(sub[,start[,end]])
用于检索字符串是否是以指定子字符串结尾,是返回True,不是返回False
str:表示原字符串;
sub:表示要检索的子字符串;
start:可选参数,表示检索范围的起始位置的索引,如果不指定,则从头开始检索;
end:可选参数,表示检索范围的结束位置的索引,如果不指定,则一直检索打末尾。
去除字符串中空格和特殊字符
strip()方法
用于去除字符串两侧的空格和特殊字符。
lstrip()方法
用于去除字符串左侧的空格和特殊字符。
rstrip()方法
用于去除字符串右侧的空格和特殊字符。
特殊字符指:
制表符\t,回车符 \r 、 换行符\n等。
格式化字符串格式一
格式化字符串是指先指定一个模板,在这个模板中预留几个空位,然后根据需要填上相应的内容。这些空位需要通过指定的符号标记(也称为站位符),而这些符号还不会显示出来。
使用“%”操作符
语法格式:'%[-][+][0][m][.n]格式化字符'%exp (注意别漏了单引号)
-:可选参数,用于指定左对齐,正数前方无符号,负数前面加负号;
+:可选参数,用于指定右对齐,正数前方加正号,负数前面加负号;
0:可选参数,表示右对齐,正数前方无符号,负数前方加负号,用0填充空白处(一般与m参数一起使用);
m:可选参数,表示占有宽度;
n:可选参数,表示小数点后保留的位数;
格式化字符:用于指定类型;
exp:要转换的项,如果要指定多个,需要通过元组,但不能用列表。
常用格式化字符串
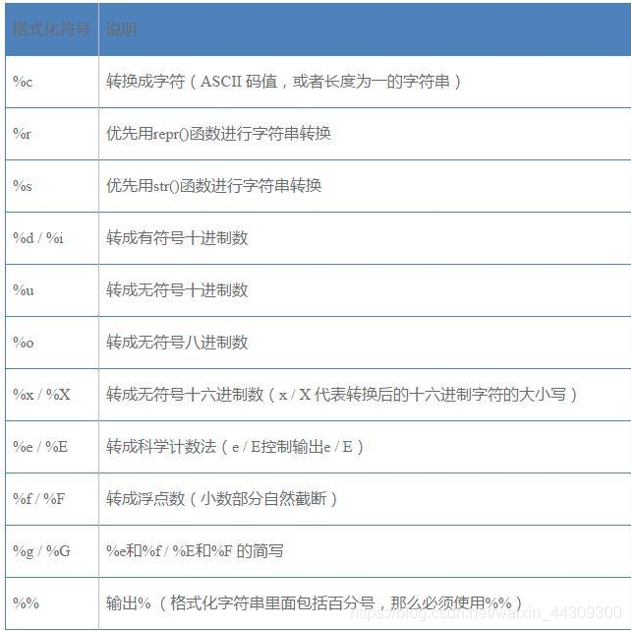
实例
template = '编号:%09d\t公司名称: %s\t官网:http://www.%s.com' context1 = (7,'百度','baidu') context2 = (8,'新浪','sina') print(template%context1) print(template%context2)
格式化字符串格式二(常用)
现在大部分不怎么使用%方法,而是使用第二种format对象来实现格式化。
使用字符串对象的format()方法
语法格式:template.format(args)
template:用于指定字符串的显示样式(即模板)的字符串
args:用于指定要转换的项,如果有多项,则用逗号进行分割。
创建模板时,需要使用“{}”和“:”指定占位符
语法格式:{[index][:[[fill]align][sign][#][width][.precision][type]]}
index:可选参数,用于指定要设置格式对象在参数列表中的索引位置
fill:可选参数,指定空白处填充的字符
align:可选参数,用于指定对齐方式(“<”:左对齐,“>”:右对齐,“=”:右对齐,只对数字有效,“^”:表示居中和
width一起使用。)
sign:可选参数,用于指定有无符号数(正数,负数)
#:可选参数,对二进制数,八进制数,和十六进制数,加上#会显示0b/0o/0x前缀
width:可选参数,用于指定宽度
.precision可选参数,用于指定保留的小数位数
type:可选参数,用于指定类型
实例
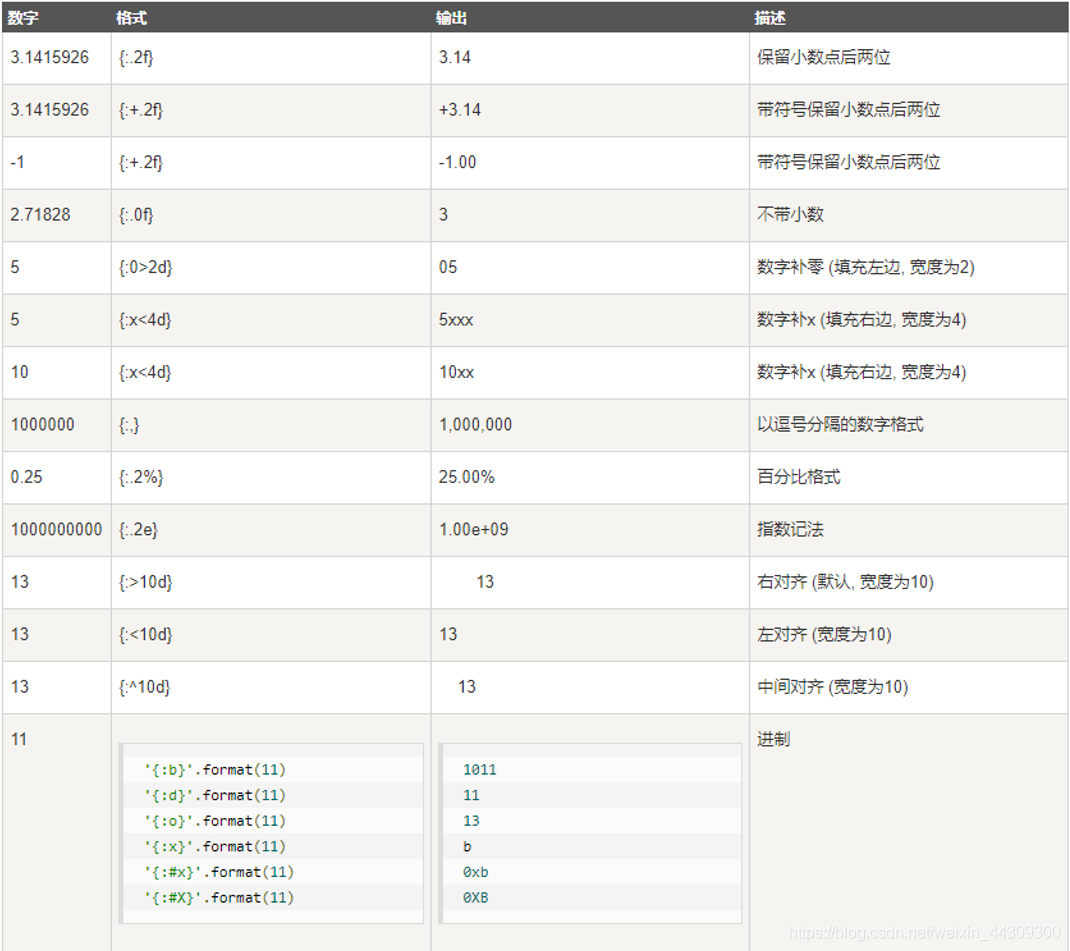
import math # 导入Python的数学模块
print('1251+3950的结果是(以货币形式显示):¥{:,.2f}元'.format(1251+3950)) # 以货币形式显示
print('{0:.1f}用科学计数法表示:{0:E}'.format(120000.1)) # 用科学计数法表示
print('π取5位小数:{:.5f}'.format(math.pi)) # 输出小数点后五位
print('{0:d}的16进制结果是:{0:#x}'.format(100)) # 输出十六进制数
print('天才是由 {:.0%} 的灵感,加上 {:.0%} 的汗水 。'.format(0.01,0.99)) # 输出百分比,并且不带小数
字符串编码转换
最早的字符串编码时美国标准信息交换吗,即ASCII码。它仅有10个数字,26个大小写字母,26个小写英文字母及一些其他符号进行编码。ASCII码最多只能表示256个符号,每个字符占一个字节。GBK和GB2312是我国制定的中文编码规则,使用一个字节表示英文字母,2个字节表示中文。UTF-8是国际通用编码,对全世界所有国家需要用到的字符都进行了编码。UTF-8采用一个字节表示英文,3个字节表示中文。
在python中,有两种常用的字符串类型,分别问str和bytes。其中str表示Unicode字符即ASCII;bytes表示二进制数据。这两种类型的字符串不能拼接在一起使用。通常情况下,str在内存中以Unicode表示,一个字符对应若干个字节。但是如果在网络传输,或者保存到硬盘,就需要str转换成字节类型即bytes。
bytes类型的数据是带有b前缀的字符串(用单引号或双引号)
例如:b'\xd2\xb0 和b'mr'都是bytes类型
str类型和bytes类型可以用encode()和decode()方法相互转换
使用encode()方法编码
encode()方法为str对象的方法,用于将字符串转换为二进制数据(即bytes),也称为“编码”。
语法格式:str.encode([encoding= “utf-8”][,errors= “strict”]
- str:表示要进行转换的字符串;
- encoding = “utf-8”:可选参数,用于指定进行转码时采用的字符编码,默认为UTF-8,如果想使用简体中文,也可以设置为gb2312。当只有这一个参数时,也可以省略前面的“encoding=”,直接写编码;
- errors = “strict”:可选参数,用于指定错误处理方式,其可选择值可以是strict(遇到非法字符就抛出异常)、ignore(忽略非法字符)、replace(用“?”替换非法字符)或xmlcharrefreplace(使用xml的字符引用)等,默认值为strict。
实例
verse = '野渡无人舟自横'
byte = verse.encode('GBK') # 采用GBK编码转换为二进制,不处理异常
print('原字符串:',verse) # 输出原字符串(没有改变)
print('转换后:',byte) # 输出转换后的二进制数据,如果用UTF-8来转换呢?
使用decode()方法解码
decode()方法为bytes对象的方法用于将二进制数据转换为字符串,即将使用encode()方法转换的结果在转换为字符串,也称为“解码”
语法格式:bytes.decode([encoding= “utf-8”][,errors= “strict”]
- bytes:表示要进行转换的二进制数据,通常是encode()方法转换的结果
- encoding = “utf-8”:可选参数,用于指定进行转码时采用的字符编码,默认为UTF-8,如果想使用简体中文,也可以设置为gb2312。当只有这一个参数时,也可以省略前面的“encoding=”,直接写编码。
- errors = “strict”:可选参数,用于指定错误处理方式,其可选择值可以是strict(遇到非法字符就抛出异常)、ignore(忽略非法字符)、replace(用“?”替换非法字符)或xmlcharrefreplace(使用xml的字符引用)等,默认值为strict。
实例
verse = '野渡无人舟自横'
byte = verse.encode('GBK') # 采用GBK编码转换为二进制,不处理异常
print('原字符串:',verse) # 输出原字符串(没有改变)
print('转换后:',byte) # 输出转换后的二进制数据,如果用UTF-8来转换呢?
print('解码后:',byte.decode('GBK')) # 对二进制数据进行解码
总结
到此这篇关于python字符串常规操作大全的文章就介绍到这了,更多相关python字符串操作内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!