
教你怎么用Python处理excel实现自动化办公
作者:涛涛真酷
这篇文章主要介绍了教你怎么用Python处理excel实现自动化办公,文中有非常详细的代码示例,对正在学习python的小伙伴们有非常好的帮助,需要的朋友可以参考下
一、介绍
实现的是把某个文件夹下的所有文件名提取出来,放入一个列表,在与excel中的某列进行对比,如果一致的话,对另一列进行操作,比如我们在统计人员活动情况的时候,对参加的人需要进行记录。
二、步骤
代统计名单
比如下面这个目录是参与活动的人员名单,每个文件夹为每个人参与活动的相关资料,有些目录是很多人一起参与一个活动,这个时候我要把文件遍历,把名字输入到一个列表中。
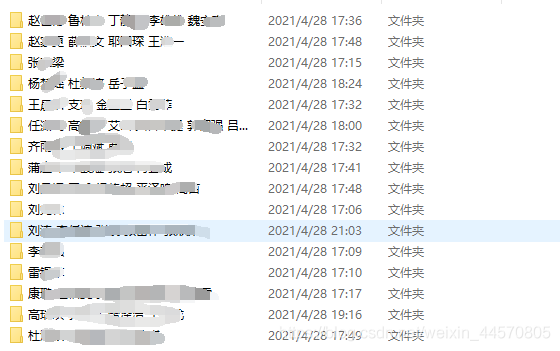
相关代码如下
# 保存指定目录下文件名到列表
def Save_name(dirPath):
filePath = dirPath
names = os.listdir(filePath)
return names
# 处理文件名
def progress_name(name):
result = []
for str in name:
str_list = str.split()
for i in str_list:
result.append(i)
return result
代处理的excel如下
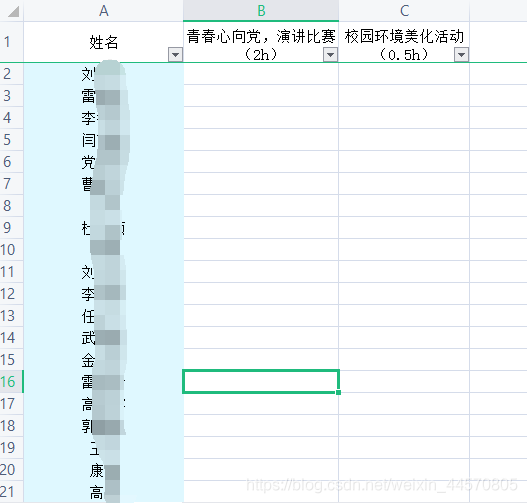
处理excel我用到的是pandas库,相关代码如下:
# 处理excel表
def progress_excel(name, filepath, col):
data1 = pd.DataFrame(pd.read_excel(filepath)) # 这个会直接默认读取到这个Excel的第一个表单
data = data1.head(70) # 默认读取前5行的数据
num = data.index
for i in name:
for j in num:
if data['姓名'].loc[j] == i:
data[col].loc[j] = 0.5
print(data)
DataFrame(data).to_excel('活动记录.xlsx', sheet_name='Sheet1', index=False, header=True)
代码运行后如下
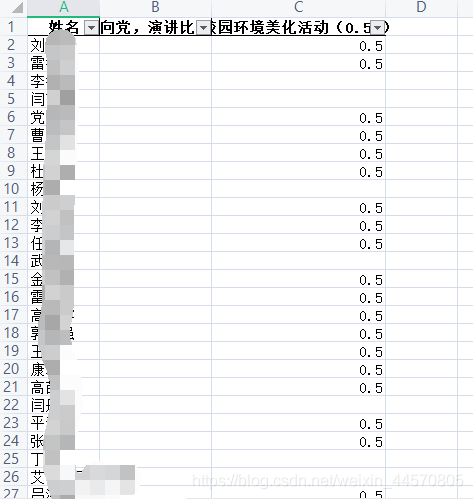
可以看到,成功处理了我需要他处理的列,并进行时长的统计
三、完整代码
import os
import pandas as pd
from pandas import DataFrame
# 保存指定目录下文件名到列表
def Save_name(dirPath):
filePath = dirPath
names = os.listdir(filePath)
return names
# 处理文件名
def progress_name(name):
result = []
for str in name:
str_list = str.split()
for i in str_list:
result.append(i)
return result
# 处理excel表
def progress_excel(name, filepath, col):
data1 = pd.DataFrame(pd.read_excel(filepath)) # 这个会直接默认读取到这个Excel的第一个表单
data = data1.head(70) # 默认读取前5行的数据
num = data.index
for i in name:
for j in num:
if data['姓名'].loc[j] == i:
data[col].loc[j] = 0.5
print(data)
DataFrame(data).to_excel('活动记录.xlsx', sheet_name='Sheet1', index=False, header=True)
if __name__ == '__main__':
path = 'F:\\党支部\\环境美化活动' # 要提取文件夹名的路径
names = Save_name(path)
filenames = progress_name(names)
# print(filenames)
# print(len(filenames))
excelname = 'F:\\党支部\\活动记录.xlsx' # 要处理的表
col = '校园环境美化活动(0.5h)' # 要处理的列
progress_excel(filenames, excelname, col)
到此这篇关于教你怎么用Python处理excel实现自动化办公的文章就介绍到这了,更多相关用Python处理excel实现自动化办公内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!