
golang在GRPC中设置client的超时时间
作者:hzzyu
超时
建立连接
主要就2函数Dail和DialContext。
// Dial creates a client connection to the given target.
func Dial(target string, opts ...DialOption) (*ClientConn, error) {
return DialContext(context.Background(), target, opts...)
}
func DialContext(ctx context.Context, target string, opts ...DialOption) (conn *ClientConn, err error){...}
DialContext 太长了不帖了.看Dial实际上也是调用DialContext来实现的.如果你想在建立连接的时候使用超时控制.就使用
DialContext传入一个Timeout的context,就像下面的例子
ctx1, cel := context.WithTimeout(context.Background(), time.Second*3) defer cel() conn, err := grpc.DialContext(ctx1, address, grpc.WithBlock(), grpc.WithInsecure())
另外调用Dial建立连接默认只是返回一个ClientConn的指针,相当于new了一个ClientConn 把指针返回给你。并不是一定要建立真实的h2连接.至于真实的连接建立实际上是一个异步的过程。
当然了如果你想等真实的链接完全建立再返回ClientConn可以通过WithBlock传入Options来实现,当然了这样的话链接如果建立不成功就会一直阻塞直到Contex超时。
真正的建立链接的代码后面介绍重试的时候会再详细介绍。
调用超时
这个比较简单
ctx, cancel := context.WithTimeout(context.TODO(), time.Second*3)
defer cancel()
r, err := c.SayHello(ctx, &pb.HelloRequest{Name: name})
如上代码传入一个timeout context就可以。
Server
type SearchService struct{}
func (s *SearchService) Search(ctx context.Context, r *pb.SearchRequest) (*pb.SearchResponse, error) {
for i := 0; i < 5; i++ {
if ctx.Err() == context.Canceled {
return nil, status.Errorf(codes.Canceled, "SearchService.Search canceled")
}
time.Sleep(1 * time.Second)
}
return &pb.SearchResponse{Response: r.GetRequest() + " Server"}, nil
}
func main() {
...
}
而在 Server 端,由于 Client 已经设置了截止时间。Server 势必要去检测它
否则如果 Client 已经结束掉了,Server 还傻傻的在那执行,这对资源是一种极大的浪费
因此在这里需要用 ctx.Err() == context.Canceled 进行判断,为了模拟场景我们加了循环和睡眠 ?
验证
重新启动 server.go 和 client.go,得到结果:
$ go run client.go 2018/10/06 17:45:55 client.Search err: deadline exit status 1
总结
本章节比较简单,你需要知道以下知识点:
怎么设置 Deadlines
为什么要设置 Deadlines
你要清楚地明白到,gRPC Deadlines 是很重要的,否则这小小的功能点就会要了你生产的命。
补充:golang使用grpc超时控制和对冲策略
超时控制
grcp超时控制设置在客户端调用服务时,如果设定了超时时间,客户端会立即返回超时。超时控制一般有三个因素:链路超时:上有调用端通过协议字段把自己允许的超时时间传给当前服务,表示在该时间内返回数据,超时返回已无意义。流程如下图A调用B的总超时情况。
消息超时:服务端收到请求消息到返回响应数据的最长消息处理时间。下图的B内部的当前请求整体超时时间。调用超时:当前服务调用下游服务设置的每一个rpc请求的超时时间。如下图B调用C的单个超时时间。通常一次请求会连续调用多次rpc,这个调用超时控制的是每个rpc的独立超时时间。
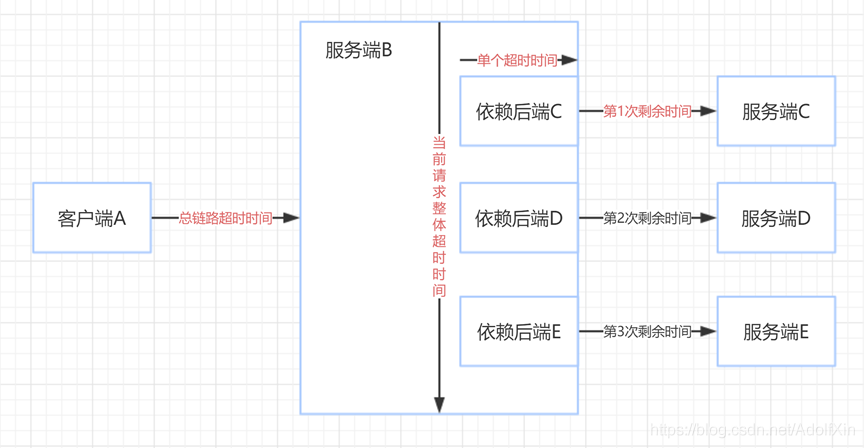
发起rpc调用请求时,需要计算此次rpc调用的超时时间。真正生效的超时时间是通过以上三个因素实时计算的最小值,计算过程
如下:
1、首先计算链路超时和消息超时的最小值,如链路超时2s,消息超时1s,则当前消息的最长处理时间为1s。
2、发起rpc调用时,再次计算当前消息最长处理时间和单个超时时间的最小值,比如:上图的B->C设置的单个超时时间为5s,则实际上B调用C的真实超时仍然是1s,其实只要超时时间大于当前最长处理时间都是无效的,都会取最小值。再比如B->C单个超时时间为500ms,这种情况B调用C的真实超时即为500ms,此时500ms这个值也会通过协议字段传给C,在服务端C的视角来看就是他的链路超时时间。链路超时时间会在整个rpc调用链上一直传递下去,并逐渐减少,直至为0,这样避免出现死循环调用的问题。
3、因为每一次rpc调用都会实际消耗一部分时间,所以当前消息最长处理时间需要实时计算剩余时间,比如上面B调用C真实耗时200ms,此时最长处理时间就只剩下800ms了。此时发起第二次rpc调用时,则需要计算此时剩余的消息超时时间和单个调用时间的最小值。如上图的B->D设置的单个超时时间为1s,则实际生效的超时时间仍然为800ms。链路超时设置:golang的context.Context根据协议里面的timeout字段和框架配置的timeout字段。设置好当前请求的最长处理时间,然后交给用户使用,并在处理函数结束时会立马cancel掉当前context。所以在创建新的goroutine时,需要重新设定新的context。
对冲策略
对冲策略不是被动的等待上一次请求超时或者失败,在对冲延时时间内(或小于超时时间)如果没有收到回复的包就会再触发一个请求。
与重试策略不同的是同一时间内in-fliaght可能有多个,当接收到第一回复时,其他的回复会被忽略。
一、重试策略:
对失败的请求,进行重新请求。
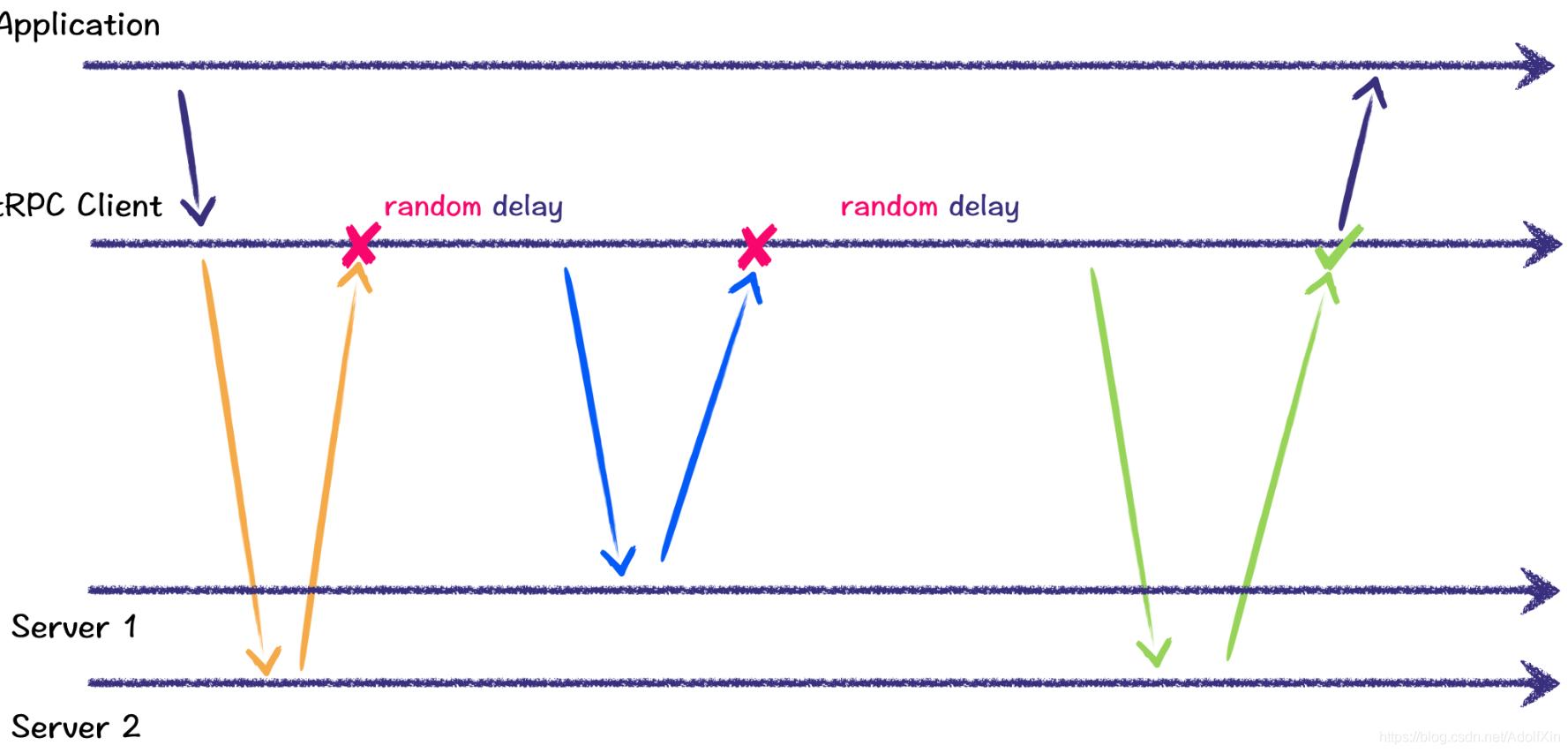
由图中可以看出,client一共进行了三次请求,前两次均失败,并且在重新请求时都会随机避段时间,防止请求毛刺,第三次请求成功,返回给应用层。对于每次尝试,我们都会尽可能地将请求发往不同的节点。
通常重试策略有三种配置:
1、失败重新请求的最大次数,达到最大次数仍然失败,不再进行重试;
2、退避时间:退避时间取的是 random(0, delay);
3、可重试错误码:设置可错误码,对于不可重试的,立即停止重试并将错误返回应用层。
二、对冲策略
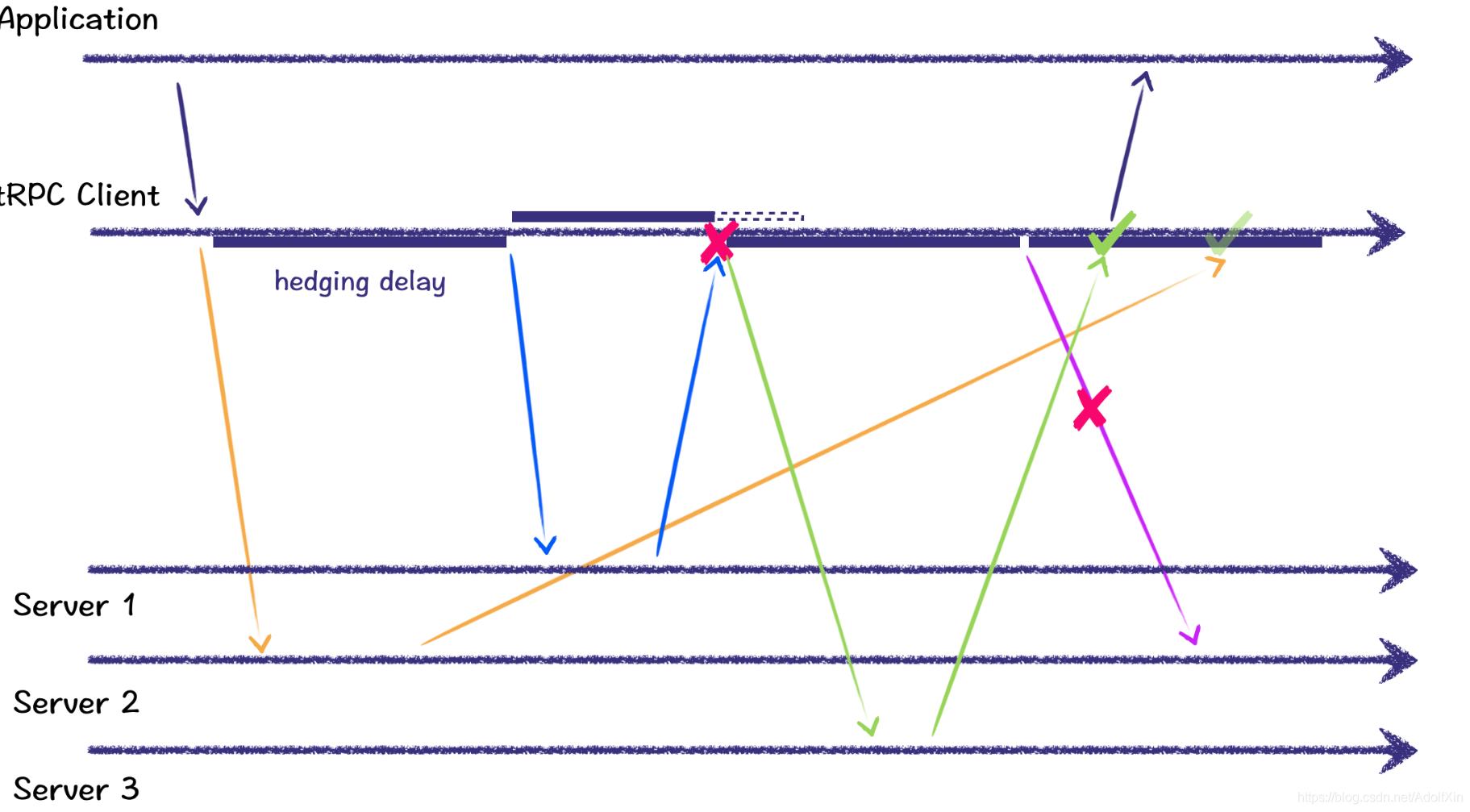
上图中client一共进行了4次,橙、蓝、绿、紫
橙色是第一次尝试。在由 client 发起后,server2 很快便收到了。但是 server2 的因为网络等问题,直到绿色请求成功,并返回给应用层后,它的正确回包才姗姗来迟。尽管它成功了,但我们必须丢弃它,因为我们已经将另一个成功的回包返回给应用层了。
蓝色是第二次尝试。因为橙色请求在对冲时延(hedging delay)后还没有回包,因此我们发起了一次新的尝试。这次尝试选择了 server1(我们会尽可能地为每次尝试选择不同的节点)。蓝色尝试的回包比较快,在对冲时延之前便返回了。但是却失败了。我们立刻发起了新一次尝试。
绿色是第三次尝试。尽管它的回包可能有点慢(超过了对冲时延,因此又触发了一次新的尝试),但是它成功了!一旦我们收到第一个成功的回包,便立刻将它返回给了应用层。
紫色是第四次尝试。刚发起后,我们便收到了绿色成功的回包。对紫色来说,它可能处于很多状态:请求还在 client gRPC 内,这时,我们有机会取消它;请求已经进入了 client 的内核或者已经由网卡发出,无论如何,我们已经没有机会取消它了。紫色请求上的 ✘ 表示我们会尽可能地取消紫色请求。注意,即使紫色请求最终成功地到达了 server2,它的回包也会像橙色一样被丢弃。
由以上可知对冲策略更像是添加了等待时间的重试,但是他没有退避机制,一旦收到错误的包,立刻发起重试。这种对于需要解决长尾问题时推荐使用,一般情况建议使用重试策略。
对冲策略一般有三种配置
1、对冲延时:在对对冲时延内没有收到回包时便会立刻发起新的尝试;
2、最大请求次数:一旦耗尽,便等待并返回最后一个回包,无论它是否成功或失败;
3、非致命错误:返回致命错误会立刻中止对冲,等待并返回最后一个回包,无论它是否成功或失败。返回非致命错误会立刻触发一次新的尝试(对冲时延计时器会被重置)。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。