
R语言-t分布正态分布分位数图的实例
作者:陆嵩
这篇文章主要介绍了R语言-t分布正态分布分位数图的实例,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
R是用于统计分析、绘图的语言和操作环境。
R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
它是一套由数据操作、计算和图形展示功能整合而成的套件。
包括:有效的数据存储和处理功能,一套完整的数组(特别是矩阵)计算操作符,拥有完整体系的数据分析工具,为数据分析和显示提供的强大图形功能,一套(源自S语言)完善、简单、有效的编程语言(包括条件、循环、自定义函数、输入输出功能)。
如何用RStudio做分位数图呢?
#分位数图,画t分布密度带p值
x=seq(-6,6,length=1000);
y=dt(x,19)
r1=-6;
r2=-2.89;
x2=c(r1,r1,x[x<r2&x>r1],r2,r2)
y2=c(0,dt(c(r1,x[x<r2&x>r1],r2),19),0)
plot(x,y,type="l",ylab="Density oft(19)",xlim=c(-5,5))
abline(h=0);polygon(x2,y2,col="red")
title("Tail Probability for t(19)")
text(c(-4.1,-2,5),c(0.02,-0.07),c("p-value=0.0047","t=-2.89"))
#对称#
x=seq(-6,6,length=1000);
y=dt(x,19)
r1=6;
r2=2.89;
x2=c(r1,r1,x[x<r2&x>r1],r2,r2)
y2=c(0,dt(c(r1,x[x<r2&x>r1],r2),19),0)
plot(x,y,type="l",ylab="Density oft(19)",xlim=c(-5,5))
abline(h=0);polygon(x2,y2,col="red")
title("Tail Probability for t(19)")
text(c(-4.1,-2,5),c(0.02,-0.07),c("p-value=0.0047","t=-2.89"))
#两边#
x=seq(-6,6,length=1000);
y=dt(x,19)
r1=-6
;r2=-2.89;
r3=2.89;
r4=6;
x2=c(r1,r1,x[x<r2&x>r1],r2,r2)
y2=c(0,dt(c(r1,x[x<r2&x>r1],r2),19),0)
x3=c(r3,r3,x[x<r4&x>r3],r4,r4)
y3=c(0,dt(c(r3,x[x<r4&x>r3],r4),19),0)
plot(x,y,type="l",ylab="Density oft(19)",xlim=c(-5,5))
abline(h=0);polygon(c(x2,x3),c(y2,y3),col="red");
title("Tail Probability for t(19)")
text(c(-4.1,-2.5),c(0.02,-0.007),c("p-value=0.0047",
"t=-2.89"))
text(c(2.5,4.1),c(0.02,-0.007),c("p-value=0.9953",
"t=2.89"))
#正态分布
x=seq(-5,5,0.01) #得到步长0.01的x范围
plot(x,dnorm(x),type="l",xlim=c(-5,5),ylim=c(0,2),
main="The Normal Density Distribution") #画
curve(dnorm(x,1,0.5),add=T,lty=2,col="blue")
lines(x,dnorm(x,0,0.25),col="green")
lines(x,dnorm(x,-2,0.5),col="orange")
legend("topright",legend=paste("m=",c(0,1,0,-2),"sd=", #m:均值 sd:方差
c(1,0.5,0.25,0.5)),lwd=3,
lty=c(1,2,1,1),col=c("black","blue","green","red"))
#分布函数
set.seed(1)
X<-seq(-5,5,length.out=100)
y<-pnorm(x,0,1)
plot(x,y,col="red",xlim=c(-5,5),ylim=c(0,1),type="l",
xaxs="i",yaxs="i",ylab='density',xlab='',
main="The Normal Cumulative Distribution")
lines(x,pnorm(x,0,0.5),col="green")
lines(x,pnorm(x,0,2),col="blue")
lines(x,pnorm(x,-2,1),col="orange")
legend("bottomright",legend=paste("m=",c(0,0,0,-2),"sd=",
c(1,0.5,2,1)),lwd=1,col=c("red","green","blue","orange"))
得到的图形结果如下:

补充:R语言绘制不同自由度下的卡方分布、t分布和F分布
看代码吧~
# === chi-squared distribution ===
chif <- function(x, df) {
dchisq(x, df = df)
}
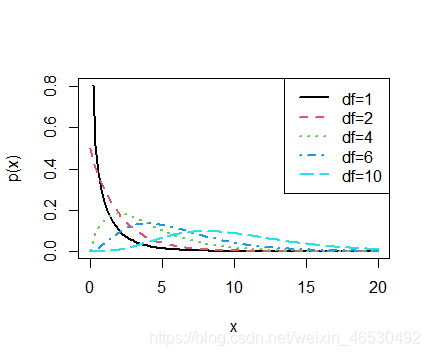
## === chi-squared distribution with df=1,2, 4, 6 and 10 ===
curve(chif(x, df = 1), 0, 20, ylab = "p(x)", lwd = 2)
curve(chif(x, df = 2), 0, 20, col = 2, add = T, lty = 2, lwd = 2)
curve(chif(x, df = 4), 0, 20, col = 3, add = T, lty = 3, lwd = 2)
curve(chif(x, df = 6), 0, 20, col = 4, add = T, lty = 4, lwd = 2)
curve(chif(x, df = 10), 0, 20, col = 5, add = T, lty = 5, lwd = 2)
legend("topright", legend = c("df=1", "df=2", "df=4", "df=6", "df=10"), col = 1:5, lty = 1:5, lwd = 2)
## === chi-squared distribution with df=4,6 and 10 ===
curve(dchisq(x, 4), 0, 20, col = 3, lty = 3, lwd = 2, ylab = "p(x)")
curve(dchisq(x, 6), 0, 20, col = 4, add = T, lty = 4, lwd = 2)
curve(dchisq(x, 10), 0, 20, col = 5, add = T, lty = 5, lwd = 2)
legend("topright", legend = c("df=4", "df=6", "df=10"), col = 3:5, lty = 3:5, lwd = 2)
### quantiles
curve(dchisq(x, 10), 0, 30, col = 1, lty = 1, lwd = 2, ylab = "p(x) of chisq(10)")
lines(c(qchisq(0.95, 10), qchisq(0.95, 10)), c(-0.05, dchisq(qchisq(0.95, 10), 10)), col = 2, lwd = 3,
lty = 2)
qchisq(0.95,10)
## ==== t ===
curve(dt(x, 1), -6, 6, ylab = "p(x)", lwd = 2, ylim = c(0, 0.4))
curve(dt(x, 2), -6, 6, col = 2, add = T, lwd = 2)
curve(dt(x, 5), -6, 6, col = 3, add = T, lwd = 2)
curve(dt(x, 10), -6, 6, col = 4, add = T, lwd = 2)
curve(dnorm(x), col = 6, add = T, lwd = 2, lty = 2)
legend("topright", legend = c("df=1", "df=2", "df=5", "df=10", "df=Inf"), col = c(1:4, 6), lty = c(rep(1,
4), 2), lwd = 2)
curve(dt(x, 4), -6, 6, col = 4, lwd = 2, ylim = c(0, 0.4), ylab = "p(x)")
curve(dnorm(x), col = 6, add = T, lwd = 2, lty = 2)
legend("topright", legend = c("t(4)", "N(0,1)"), col = c(4, 6), lty = c(1, 2), lwd = 2)
qt(0.025,10)
qt(0.975,10)
## === F ==
curve(df(x, 4, 1), 0, 4, ylab = "p(x)", lwd = 2, ylim = c(0, 0.8))
curve(df(x, 4, 4), 0, 4, col = 2, add = T, lwd = 2)
curve(df(x, 4, 10), 0, 4, col = 3, add = T, lwd = 2)
curve(df(x, 4, 4000), 0, 4, col = 4, add = T, lwd = 2)
legend("topright", legend = c("F(4,1)", "F(4,4)", "F(4,10)", "F(4,4000)"), col = 1:4, lwd = 2)
qf(0.95,10,5)
qf(0.05,5,10)
1/qf(0.05,5,10)
卡方分布


t分布


F分布

#卡方分布 > qchisq(0.95,5) [1] 11.0705 > qchisq(0.95,10) [1] 18.30704 > qchisq(0.95,15) [1] 24.99579 > qchisq(0.95,20) [1] 31.41043 > qchisq(0.95,25) [1] 37.65248 > qchisq(0.95,30) [1] 43.77297
#t分布 > qt(0.95,5) [1] 2.015048 > qt(0.95,10) [1] 1.812461 > qt(0.95,15) [1] 1.75305 > qt(0.95,20) [1] 1.724718 > qt(0.95,25) [1] 1.708141 > qt(0.95,30) [1] 1.697261
> qf(0.95,10,5) [1] 4.735063 > qf(0.95,5,10) [1] 3.325835 > qf(0.95,5,5) [1] 5.050329 > qf(0.95,10,10) [1] 2.978237
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。