
用基于python的appium爬取b站直播消费记录
作者:mister1
因工作需要,需要爬取相关数据,之前是爬取网页数据,可以用python的requests和Selenium进行爬取。但b站的直播消费数据网页版不能显示,只能在手机上看到,所以就有了这篇文章。需要的朋友可以参考下
基于python的Appium进行b站直播消费记录爬取
之前看文章说fiddler也可以进行爬取,但尝试了一下没成功,这次选择appium进行爬取。类似的,可以运用爬取微信朋友圈和抖音等手机app相关数据
正文
#环境配置参考
前期工作准备,需要安装python、jdk、PyCharm、Appium-windows-x.x、Appium_Python_Client、Android SDK,pycharm可以用anaconda的jupyter来替代
具体可以参考这篇博客,讲的算是很清楚啦
前期准备工作配置需要不停的安装和配置环境变量,也是个相对枯燥的过程
完成以后就可以真正爬取啦
导入模块
from appium import webdriver import numpy as np import pandas as pd import time
通过程序打开手机b站app
desired_caps = {
'platformName': 'Android', # 被测手机是安卓
'platformVersion': '10', # 手机安卓版本
'deviceName': 'xxx', # 设备名,安卓手机可以随意填写
'appPackage': 'tv.danmaku.bili', # 启动APP Package名称
'appActivity': '.ui.splash.SplashActivity', # 启动Activity名称
'unicodeKeyboard': True, # 使用自带输入法,输入中文时填True
'resetKeyboard': True, # 执行完程序恢复原来输入法
'noReset': True, # 不要重置App,如果为False的话,执行完脚本后,app的数据会清空,比如你原本登录了,执行完脚本后就退出登录了
'newCommandTimeout': 6000,
'automationName': 'UiAutomator2'
}
打开b站
# 连接Appium Server,初始化自动化环境
driver = webdriver.Remote('http://localhost:4723/wd/hub', desired_caps)
# 设置等待时间,如果不给时间的话可能会找不到元素
driver.implicitly_wait(4)
打开之后呈现如下页面
在手机上点击我的——我的直播——消费记录,查看个人消费记录,
当然也可以写两行代码来实现这个过程(这里选择跳过),如下图所示
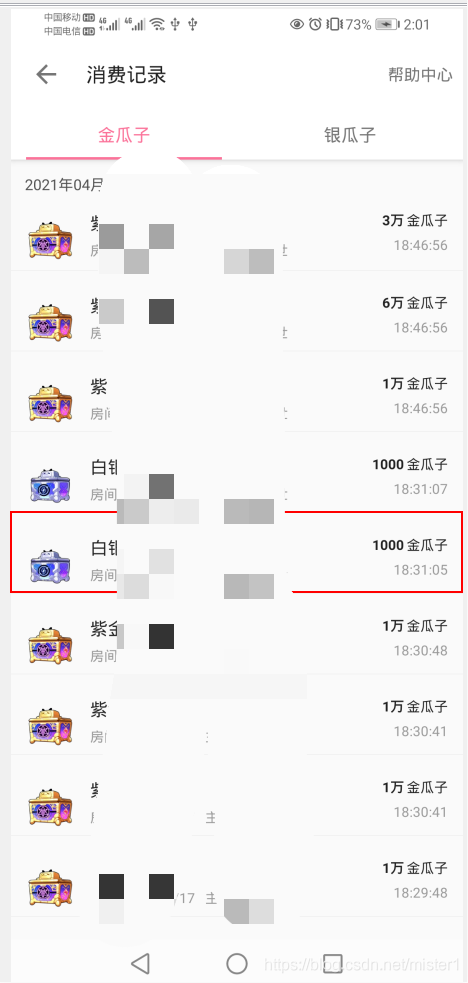
因为这个消费记录很多,一个页面只能显示10条,要想爬取所有的可以设置滑动,边向上滑动边爬取就能获取所有的数据。
具体参数设置的flick_distance=1050可以不重不漏的爬取,如下所示:
设置滑动
flick_start_x=540
flick_start_y=192
flick_distance=1050
while True:
driver.swipe(flick_start_x,flick_start_y+flick_distance,flick_start_x,flick_start_y)
爬取
pay_name_list=[]
present_price_list=[]
pay_room_list=[]
pay_ru_name_list=[]
pay_time_list=[]
flick_start_x=540
flick_start_y=192
flick_distance=1050
while True:
pay_name=driver.find_elements_by_id('pay_name')
for i in range(len(pay_name)):
pay_name_list.append(pay_name[i].text)
present_price=driver.find_elements_by_id('present_price')
for i in range(len(present_price)):
present_price_list.append(present_price[i].text)
pay_room=driver.find_elements_by_id('pay_room')
for i in range(len(pay_room)):
pay_room_list.append(pay_room[i].text)
pay_ru_name=driver.find_elements_by_id('pay_ru_name')
for i in range(len(pay_ru_name)):
pay_ru_name_list.append(pay_ru_name[i].text)
pay_time=driver.find_elements_by_id('pay_time')
for i in range(len(pay_time)):
pay_time_list.append(pay_time[i].text)
driver.swipe(flick_start_x,flick_start_y+flick_distance,flick_start_x,flick_start_y)
time.sleep(2)

转换成dataframe
a=pd.DataFrame([pay_name_list,present_price_list,pay_room_list,pay_ru_name_list,pay_time_list],index=['pay_name_list','present_price_list','pay_room_list','pay_ru_name_list','pay_time_list']) pd.DataFrame(a.T).head(50)
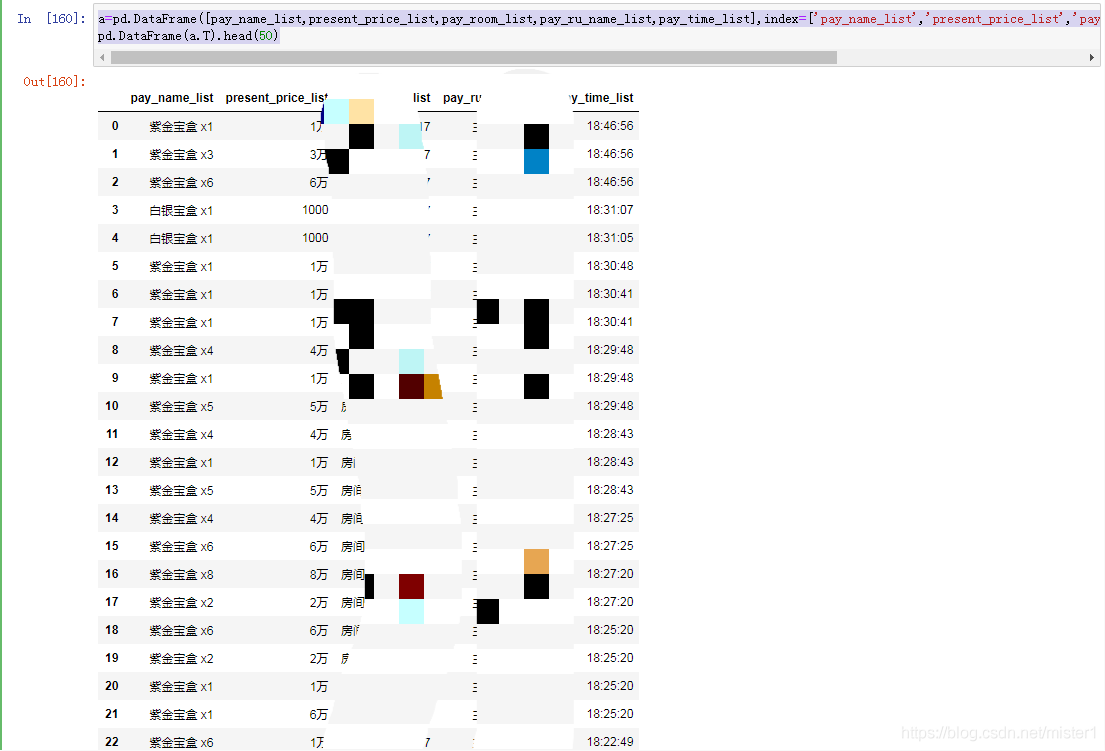
ok,这样工作就都完成啦,继续快乐的搬砖…
到此这篇用基于python的appium爬取b站直播消费记录的文章就介绍到这了,更多相关python,appium的内容请搜索脚本之家以前的文章或继续浏览下面的相关文章,希望大家以后多多支持脚本之家!