
Pytorch 使用tensor特定条件判断索引
作者:judgechen1997
这篇文章主要介绍了Pytorch 使用tensor特定条件判断索引的操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
torch.where() 用于将两个broadcastable的tensor组合成新的tensor,类似于c++中的三元操作符“?:”
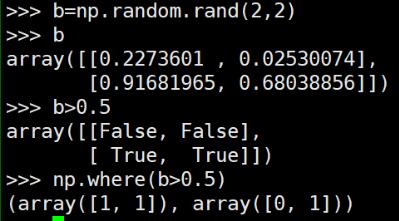
区别于python numpy中的where()直接可以找到特定条件元素的index
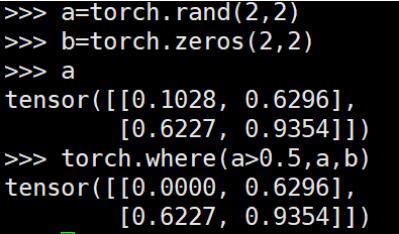
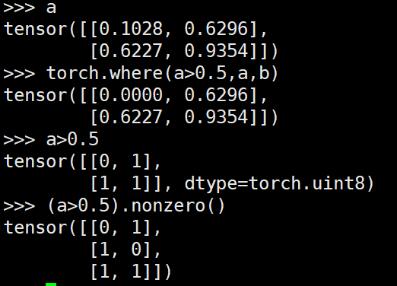
想要实现numpy中where()的功能,可以借助nonzero()
对应numpy中的where()操作效果:
补充:Pytorch torch.Tensor.detach()方法的用法及修改指定模块权重的方法
detach
detach的中文意思是分离,官方解释是返回一个新的Tensor,从当前的计算图中分离出来

需要注意的是,返回的Tensor和原Tensor共享相同的存储空间,但是返回的 Tensor 永远不会需要梯度
import torch as t a = t.ones(10,) b = a.detach() print(b) tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
那么这个函数有什么作用?
–假如A网络输出了一个Tensor类型的变量a, a要作为输入传入到B网络中,如果我想通过损失函数反向传播修改B网络的参数,但是不想修改A网络的参数,这个时候就可以使用detcah()方法
a = A(input) a = detach() b = B(a) loss = criterion(b, target) loss.backward()
来看一个实际的例子:
import torch as t x = t.ones(1, requires_grad=True) x.requires_grad #True y = t.ones(1, requires_grad=True) y.requires_grad #True x = x.detach() #分离之后 x.requires_grad #False y = x+y #tensor([2.]) y.requires_grad #我还是True y.retain_grad() #y不是叶子张量,要加上这一行 z = t.pow(y, 2) z.backward() #反向传播 y.grad #tensor([4.]) x.grad #None
以上代码就说明了反向传播到y就结束了,没有到达x,所以x的grad属性为None
既然谈到了修改模型的权重问题,那么还有一种情况是:
–假如A网络输出了一个Tensor类型的变量a, a要作为输入传入到B网络中,如果我想通过损失函数反向传播修改A网络的参数,但是不想修改B网络的参数,这个时候又应该怎么办了?
这时可以使用Tensor.requires_grad属性,只需要将requires_grad修改为False即可.
for param in B.parameters(): param.requires_grad = False a = A(input) b = B(a) loss = criterion(b, target) loss.backward()
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。