
Zabbix 动态执行监控采集脚本的实现原理
作者:寰宇001
这篇文章主要介绍了Zabbix 动态执行监控采集脚本的实现原理,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下
在使用Zabbix自定义脚本采集监控数据的时候,通常会遇到以下一些问题:
- 服务器扩容之后,监控脚本如何部署到新的服务器上?
- 监控脚本需要修改时,如何自动修改所有相同的监控脚本?
- 如何备份监控采集脚本避免因服务器异常后丢失?
- 新部署自定义监控,如何避免系统管理员过多操作?
- 如何避免大量研发就能解决上述的问题?
实现原理:使用文件服务器统一存放和管理监控脚本,在zabbix agent预埋通用脚本,根据zabbix server传输的Key和参数,从文件服务器拉取脚本执行后返回数据。
架构设计:
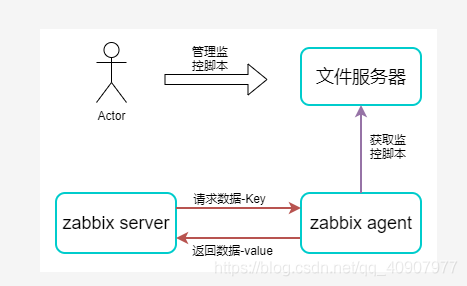
具体实现:
1.搭建文件服务器,以nginx作为文件服务器为例
修改nginx的配置并重启
erver {
listen 8080;
server_name zabbix;
root /usr/local/static/;
location / {
autoindex on;
autoindex_exact_size on;
autoindex_localtime on;
charset utf-8;
}
}
2.编写文件拉取和执行的脚本
url="http://192.168.24.108:8080/" #定义文件服务器的URL parentDir="/usr/local/zabbix/bin/zabbix_script" file_directory=$parentDir/$1 #定义本地存放执行脚本的目录 file_name=$2 #脚本名称 file_path=$1/$2 #拼接文件服务器的脚本路径 if [ ! -d $file_directory ];then #判断文件目录是否存在 mkdir -p $file_directory fi if [ ! -f $parentDir/$file_path ];then #判断脚本是否已经存在 wget -P $file_directory $url$file_path 2>>log fi timestamp=$(date +%s) filetimestamp=$(stat -c %Y $parentDir/$file_path) if [ $[$timestamp - $filetimestamp] -gt 3600 ];then #判断当前时间与脚本修改时间的大小,3600秒更新一次 wget $url$file_path -O $parentDir/$file_path 2>>log #覆盖脚本 touch -c $parentDir/$file_path #修改脚本的修改时间 fi python $parentDir/$file_path $3 #执行脚本
3.增加zabbix的配置文件
UserParameter=requests_file[*],sh /usr/local/zabbix/bin/zabbix_script/requests_file.sh $1 $2 $3
4.重启zabbix agent
5.编写测试脚本,并上传到文件服务器指定目录
#监控服务器连接数 #!/usr/bin/python import pwd import os,sys import re import glob state = sys.argv[1] cmd = "netstat -an | grep " + state + " | wc -l" os.system(cmd)
6.配置zabbix页面的监控项:
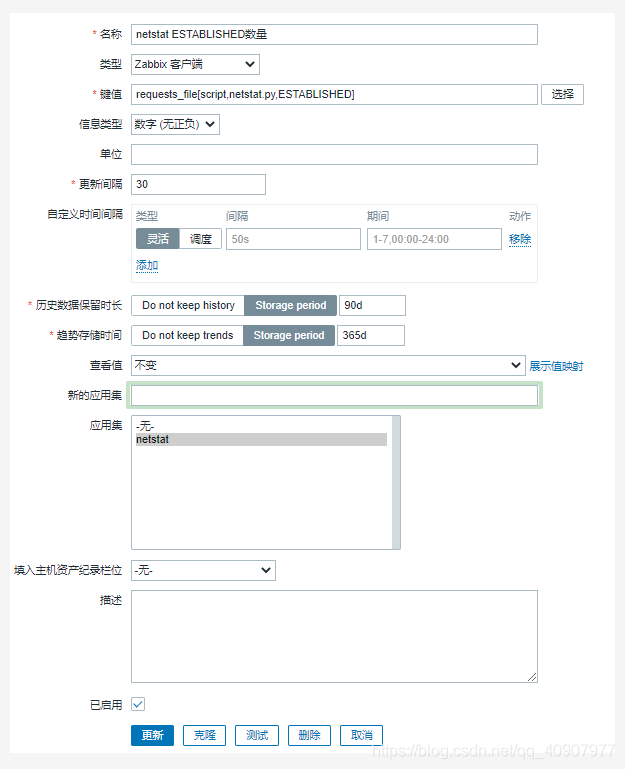
7.观察数据是否正常 :

8.新的监控脚本放在文件服务器之后,可直接配置页面的监控项进行数据采集

本文着重提供了一个zabbix自定义监控脚本集中管理的解决思路,可根据这个思路自由拓展更简洁、高效的zabbix使用方法,进一步让运维变得简单。
参考链接 :
Zabbix 如何动态执行监控采集脚本 : https://mp.weixin.qq.com/s/ikuCSYhlFdtiAmt7epskWw
到此这篇关于Zabbix 动态执行监控采集脚本的实现原理的文章就介绍到这了,更多相关Zabbix 动态执行监控采集脚本内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!