
Django-Scrapy生成后端json接口的方法示例
作者:欢迎来到xbhog博客
网上的关于django-scrapy的介绍比较少,该博客只在本人查资料的过程中学习的,如果不对之处,希望指出改正;
以后的博客可能不会再出关于django相关的点;
人心太浮躁,个人深度不够,只学习了一些皮毛,后面博客只求精,不求多;
希望能坚持下来。加油!
学习点:
- 实现效果
- django与scrapy的创建
- setting中对接的位置和代码段
- scrapy_djangoitem使用
- scrapy数据爬取保存部分
- 数据库设计以及问题部分
- django配置
实现效果:
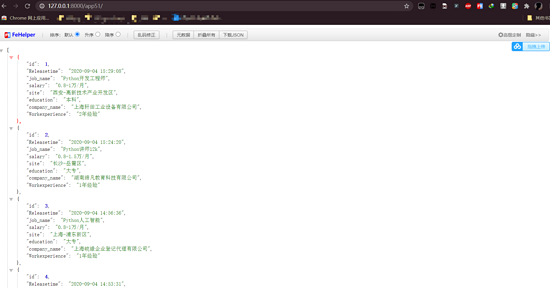
django与scrapy的创建:
django的创建:
django startproject 项目名称
cd 项目名称 python manage.py startapp appname
例如:
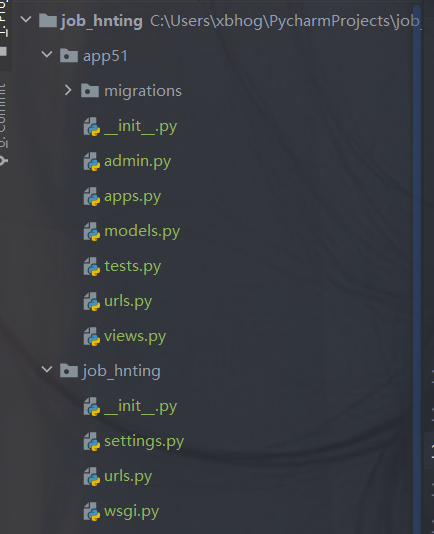
scrapy的创建:
# cd django的根目录下 cd job_hnting scrapy startproject 项目名称 #创建爬虫 scrapy genspider spidername 'www.xxx.com'
例如:
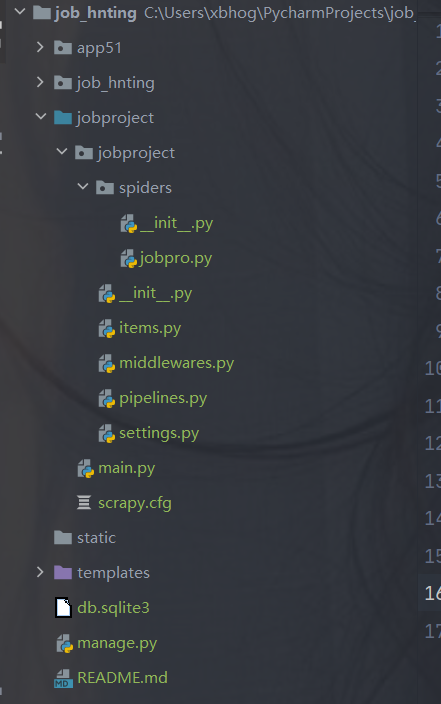
setting的设置:
在scrapy框架中的setting指向django,让django知道有scrapy;
在scrapy中的setting设置;
import os import django #导入 os.environ['DJANGO_SETTINGS_MODULE'] = 'job_hnting.settings' #手动初始化 django.setup()
如:
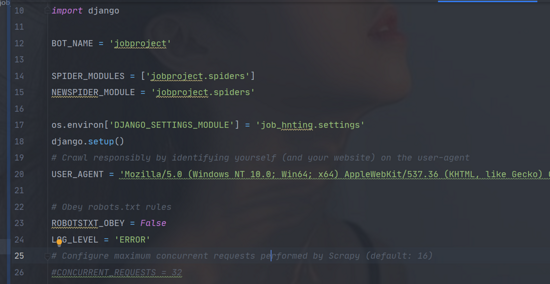
scrapy_djangoitem使用:
pip install scrapy_djangoitem
该库在scrapy项目下的item中编写引入:
import scrapy # 引入django中app中models文件中的类 from app51.models import app51data # scrapy与django对接的库 from scrapy_djangoitem import DjangoItem class JobprojectItem(DjangoItem): #引用django下的model中的类名 django_model = app51data
数据存储部分对接在后面解释,现在大体框架完整;
scrapy爬取保存部分:
首先编写scrapy爬虫部分:
我们选取的是51招聘网站的数据:
爬取分为三个函数:
- 主函数
- 解析函数
- 总页数函数
51job的反爬手段:
将json的数据格式隐藏在网页结构中,网上教程需要别的库解析(自行了解),
我们的方法是使用正则匹配提取定位到数据部分,使用json库解析:
# 定位数据位置,提取json数据
search_pattern = "window.__SEARCH_RESULT__ = (.*?)</script>"
jsonText = re.search(search_pattern, response.text, re.M | re.S).group(1)
获得关键字总页数:
# 解析json数据
jsonObject = json.loads(jsonText)
number = jsonObject['total_page']
在主函数中构造页面url并给到解析函数:
for number in range(1,int(numbers)+1):
next_page_url = self.url.format(self.name,number)
# print(next_page_url)
#构造的Urlcallback到data_parse函数中
yield scrapy.Request(url=next_page_url,callback=self.data_parse)
最后在解析函数中提取需要的数据:
for job_item in jsonObject["engine_search_result"]:
items = JobprojectItem()
items['job_name'] = job_item['job_name']
items['company_name'] = job_item["company_name"]
# 发布时间
items['Releasetime'] = job_item['issuedate']
items['salary'] = job_item['providesalary_text']
items['site'] = job_item['workarea_text']
.......
相关的细节部分需要自己调整,完整代码在 GitHub 中。
数据爬取部分解决后,需要到scrapy项目中的pipline文件保存;
class SeemeispiderPipeline(object):
def process_item(self, item, spider):
item.save()
return item
记得在setting文件中取消掉pipline的注释
设置数据库:
Django配置数据库有两种方法:
方法一:直接在settings.py文件中添加数据库配置信息(个人使用的)
DATABASES = {
# 方法一
'default': {
'ENGINE': 'django.db.backends.mysql', # 数据库引擎
'NAME': 'mysite', # 数据库名称
'USER': 'root', # 数据库登录用户名
'PASSWORD': '123', # 密码
'HOST': '127.0.0.1', # 数据库主机IP,如保持默认,则为127.0.0.1
'PORT': 3306, # 数据库端口号,如保持默认,则为3306
}
}
方法二:将数据库配置信息存到一个文件中,在settings.py文件中将其引入。
新建数据库配置文件my.cnf(名字随意选择)
[client] database = blog user = blog password = blog host =127.0.0.1 port = 3306 default-character-set = utf8
在settings.py文件中引入my.cnf文件
DATABASES = {
# 方法二:
'default': {
'ENGINE': 'django.db.backends.mysql',
'OPTIONS': {
'read_default_file': 'utils/dbs/my.cnf',
},
}
}
启用Django与mysql的连接
在生产环境中安装pymysql 并且需要在settings.py文件所在包中的 __init__.py 中导入pymysql
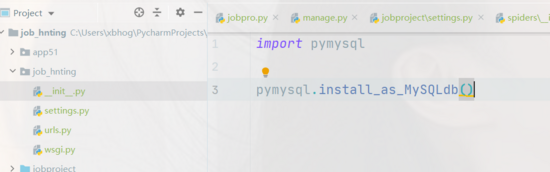
import pymysql pymysql.install_as_MySQLdb()
对应前面的item,在spider中编写时按照model设置的即可;;
from django.db import models
# Create your models here.
#定义app51的数据模型
class app51data(models.Model):
#发布时间,长度20
Releasetime = models.CharField(max_length=20)
#职位名,长度50
job_name =models.CharField(max_length=50)
#薪水
salary = models.CharField(max_length=20)
#工作地点
site = models.CharField(max_length=50)
#学历水平
education = models.CharField(max_length=20)
#公司名称
company_name = models.CharField(max_length=50)
#工作经验
Workexperience = models.CharField(max_length=20)
#指定表名
class Meta:
db_table = 'jobsql51'
def __str__(self):
return self.job_name
当指定完表名后,在DBMS中只需要创建对应的数据库即可,表名自动创建
每次修改数据库都要进行以下命令:
python manage.py makemigrations python manage.py migrate
到此mysql数据库配置完成
配置数据库时遇到的错误:
Django启动报错:AttributeError: 'str' object has no attribute 'decode'
解决方法:
找到Django安装目录
G:\env\django_job\Lib\site-packages\django\db\backends\mysql\operations.py
编辑operations.py;
将146行的decode修改成encode
def last_executed_query(self, cursor, sql, params):
# With MySQLdb, cursor objects have an (undocumented) "_executed"
# attribute where the exact query sent to the database is saved.
# See MySQLdb/cursors.py in the source distribution.
query = getattr(cursor, '_executed', None)
if query is not None:
#query = query.decode(errors='replace')
uery = query.encode(errors='replace')
return query
django配置:
关于django的基础配置,如路由,app的注册等基础用法,暂时不过多说明;
以下主要关于APP中视图的配置,生成json;
from django.shortcuts import render
from django.http import HttpResponse
# Create your views here.
#引入数据
from .models import app51data
import json
def index(request):
# return HttpResponse("hello world")
# return render(request,'index.html')
#获取所有的对象,转换成json格式
data =app51data.objects.all()
list3 = []
i = 1
for var in data:
data = {}
data['id'] = i
data['Releasetime'] = var.Releasetime
data['job_name'] = var.job_name
data['salary'] = var.salary
data['site'] = var.site
data['education'] = var.education
data['company_name'] = var.company_name
data['Workexperience'] = var.Workexperience
list3.append(data)
i += 1
# a = json.dumps(data)
# b = json.dumps(list2)
# 将集合或字典转换成json 对象
c = json.dumps(list3)
return HttpResponse(c)
实现效果:
完整代码在 GitHub 中,希望随手star,感谢!
到此这篇关于Django-Scrapy生成后端json接口的方法示例的文章就介绍到这了,更多相关Django Scrapy生成json接口内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!