
Mybatis-Plus和Mybatis的区别详解
作者:杭州java开发郭靖
原文:https://blog.csdn.net/qq_34508530/article/details/88943858
 .
.
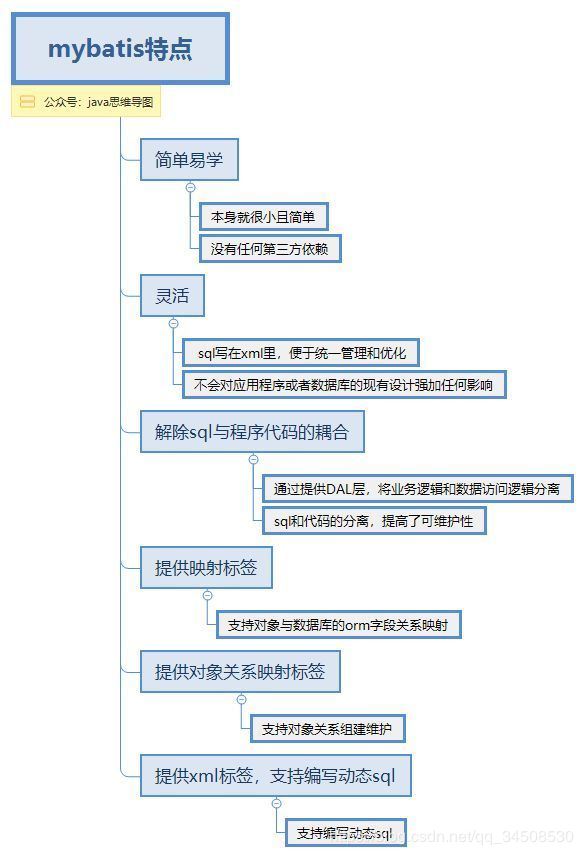
区别一
如果Mybatis Plus是扳手,那Mybatis Generator就是生产扳手的工厂。
通俗来讲——
MyBatis:一种操作数据库的框架,提供一种Mapper类,支持让你用java代码进行增删改查的数据库操作,省去了每次都要手写sql语句的麻烦。但是!有一个前提,你得先在xml中写好sql语句,是不是很麻烦?于是有下面的↓
Mybatis Generator:自动为Mybatis生成简单的增删改查sql语句的工具,省去一大票时间,两者配合使用,开发速度快到飞起。至于标题说的↓
Mybatis Plus:国人团队苞米豆在Mybatis的基础上开发的框架,在Mybatis基础上扩展了许多功能,荣获了2018最受欢迎国产开源软件第5名,当然也有配套的↓
Mybatis Plus Generator:同样为苞米豆开发,比Mybatis Generator更加强大,支持功能更多,自动生成Entity、Mapper、Service、Controller等
总结:
数据库框架:Mybatis Plus > Mybatis
代码生成器:Mybatis Plus Generator > Mybatis Generator
区别二
Mybatis-Plus是一个Mybatis的增强工具,它在Mybatis的基础上做了增强,却不做改变。我们在使用Mybatis-Plus之后既可以使用Mybatis-Plus的特有功能,又能够正常使用Mybatis的原生功能。Mybatis-Plus(以下简称MP)是为简化开发、提高开发效率而生,但它也提供了一些很有意思的插件,比如SQL性能监控、乐观锁、执行分析等。
Mybatis虽然已经给我们提供了很大的方便,但它还是有不足之处,实际上没有什么东西是完美的,MP的存在就是为了稍稍弥补Mybatis的不足。在我们使用Mybatis时会发现,每当要写一个业务逻辑的时候都要在DAO层写一个方法,再对应一个SQL,即使是简单的条件查询、即使仅仅改变了一个条件都要在DAO层新增一个方法,针对这个问题,MP就提供了一个很好的解决方案,之后我会进行介绍。另外,MP的代码生成器也是一个很有意思的东西,它可以让我们避免许多重复性的工作,下面我将介绍如何在你的项目中集成MP。
一、 集成步骤↓:(首先,你要有个spring项目)
集成依赖,pom中加入依赖即可,不多说:
Java代码
<!-- mybatis mybatis-plus mybatis-spring mvc -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.0</version>
</dependency>
说明:笔者使用的版本为:mybatis-plus.version=2.1-gamma,上边的代码中有两个依赖,第一个是mybatis-plus核心依赖,第二个是使用代码生成器时需要的模板引擎依赖,若果你不打算使用代码生成器,此处可不引入。
注意:mybatis-plus的核心jar包中已集成了mybatis和mybatis-spring,所以为避免冲突,请勿再次引用这两个jar包。
二、 在spring中配置MP:
<bean id="sqlSessionFactory"
class="com.baomidou.mybatisplus.spring.MybatisSqlSessionFactoryBean">
<!-- 配置数据源 -->
<property name="dataSource" ref="dataSource" />
<!-- 自动扫描 Xml 文件位置 -->
<property name="mapperLocations" value="classpath*:com/ds/orm/mapper/**/*.xml" />
<!-- 配置 Mybatis 配置文件(可无) -->
<property name="configLocation" value="classpath:mybatis-config.xml" />
<!-- 配置包别名,支持通配符 * 或者 ; 分割 -->
<property name="typeAliasesPackage" value="com.ds.orm.model" />
<!-- 枚举属性配置扫描,支持通配符 * 或者 ; 分割 -->
<!-- <property name="typeEnumsPackage" value="com.baomidou.springmvc.entity.*.enums"
/> -->
<!-- 以上配置和传统 Mybatis 一致 -->
<!-- MP 全局配置注入 -->
<property name="globalConfig" ref="globalConfig" />
</bean>
<bean id="globalConfig" class="com.baomidou.mybatisplus.entity.GlobalConfiguration">
<!-- 主键策略配置 -->
<!-- 可选参数 AUTO->`0`("数据库ID自增") INPUT->`1`(用户输入ID") ID_WORKER->`2`("全局唯一ID")
UUID->`3`("全局唯一ID") -->
<property name="idType" value="2" />
<!-- 数据库类型配置 -->
<!-- 可选参数(默认mysql) MYSQL->`mysql` ORACLE->`oracle` DB2->`db2` H2->`h2`
HSQL->`hsql` SQLITE->`sqlite` POSTGRE->`postgresql` SQLSERVER2005->`sqlserver2005`
SQLSERVER->`sqlserver` -->
<property name="dbType" value="mysql" />
<!-- 全局表为下划线命名设置 true -->
<property name="dbColumnUnderline" value="true" />
<property name="sqlInjector">
<bean class="com.baomidou.mybatisplus.mapper.AutoSqlInjector" />
</property>
</bean>
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<description>DAO接口所在包名,Spring会自动查找其下的类</description>
<property name="basePackage" value="com.ds.orm.mapper" />
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory" />
</bean>
<!-- 乐观锁插件 -->
<bean class="com.baomidou.mybatisplus.plugins.OptimisticLockerInterceptor" />
<!-- xml mapper热加载 sqlSessionFactory:session工厂 mapperLocations:mapper匹配路径
enabled:是否开启动态加载 默认:false delaySeconds:项目启动延迟加载时间 单位:秒 默认:10s sleepSeconds:刷新时间间隔
单位:秒 默认:20s -->
<bean class="com.baomidou.mybatisplus.spring.MybatisMapperRefresh">
<constructor-arg name="sqlSessionFactory" ref="sqlSessionFactory" />
<constructor-arg name="mapperLocations"
value="classpath*:com/ds/orm/mapper/*/*.xml" />
<constructor-arg name="delaySeconds" value="10" />
<constructor-arg name="sleepSeconds" value="20" />
<constructor-arg name="enabled" value="true" />
</bean>
<!-- 事务 -->
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<tx:annotation-driven transaction-manager="transactionManager"
proxy-target-class="true" />
注意:只要做如上配置就可以正常使用mybatis了,不要重复配置。MP的配置和mybatis一样,都是配置一个sqlSessionFactory,只是现在所配置的类在原本的SqlSessionFactoryBean基础上做了增强。插件等配置请按需取舍。
插件配置,按需求配置就可以,此处把可以配置的插件都列了出来,具体的请看代码注释:
Java代码 收藏代码
<configuration>
<settings>
<setting name="logImpl" value="SLF4J" />
<!-- 字段为空时仍调用model的set方法或map的put方法 -->
<setting name="callSettersOnNulls" value="true" />
</settings>
<plugins>
<!-- | 分页插件配置 | 插件提供二种方言选择:1、默认方言 2、自定义方言实现类,两者均未配置则抛出异常! | overflowCurrent
溢出总页数,设置第一页 默认false | optimizeType Count优化方式 ( 版本 2.0.9 改为使用 jsqlparser 不需要配置
) | -->
<!-- 注意!! 如果要支持二级缓存分页使用类 CachePaginationInterceptor 默认、建议如下!! -->
<plugin interceptor="com.baomidou.mybatisplus.plugins.PaginationInterceptor">
<property name="dialectType" value="mysql" />
<!--<property name="sqlParser" ref="自定义解析类、可以没有" />
<property name="localPage" value="默认 false 改为 true 开启了 pageHeper 支持、可以没有" />
<property name="dialectClazz" value="自定义方言类、可以没有" /> -->
</plugin>
<!-- SQL 执行性能分析,开发环境使用,线上不推荐。 maxTime 指的是 sql 最大执行时长 -->
<plugin interceptor="com.baomidou.mybatisplus.plugins.PerformanceInterceptor">
<property name="maxTime" value="2000" />
<!--SQL是否格式化 默认false -->
<property name="format" value="true" />
</plugin>
<!-- SQL 执行分析拦截器 stopProceed 发现全表执行 delete update 是否停止运行 该插件只用于开发环境,不建议生产环境使用。。。 -->
<plugin interceptor="com.baomidou.mybatisplus.plugins.SqlExplainInterceptor">
<property name="stopProceed" value="false" />
</plugin>
</plugins>
</configuration>
注意:执行分析拦截器和性能分析推荐只在开发时调试程序使用,为保证程序性能和稳定性,建议在生产环境中注释掉这两个插件。
数据源:(此处使用druid)
<!-- 配置数据源 -->
<bean name="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<!-- <property name="driverClassName" value="${jdbc.driverClassName}" /> -->
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
<property name="initialSize" value="${jdbc.initialSize}" />
<property name="minIdle" value="${jdbc.minIdle}" />
<property name="maxActive" value="${jdbc.maxActive}" />
<property name="maxWait" value="${jdbc.maxWait}" />
<property name="timeBetweenEvictionRunsMillis" value="${jdbc.timeBetweenEvictionRunsMillis}" />
<property name="minEvictableIdleTimeMillis" value="${jdbc.minEvictableIdleTimeMillis}" />
<property name="validationQuery" value="${jdbc.validationQuery}" />
<property name="testWhileIdle" value="${jdbc.testWhileIdle}" />
<property name="testOnBorrow" value="${jdbc.testOnBorrow}" />
<property name="testOnReturn" value="${jdbc.testOnReturn}" />
<property name="removeAbandoned" value="${jdbc.removeAbandoned}" />
<property name="removeAbandonedTimeout" value="${jdbc.removeAbandonedTimeout}" />
<!-- <property name="logAbandoned" value="${jdbc.logAbandoned}" /> -->
<property name="filters" value="${jdbc.filters}" />
<!-- 关闭abanded连接时输出错误日志 -->
<property name="logAbandoned" value="true" />
<property name="proxyFilters">
<list>
<ref bean="log-filter"/>
</list>
</property>
<!-- 监控数据库 -->
<!-- <property name="filters" value="stat" /> -->
<!-- <property name="filters" value="mergeStat" />-->
</bean>
到此,MP已经集成进我们的项目中了,下面将介绍它是如何简化我们的开发的。
**
三、 简单的CURD操作↓:
**
假设我们有一张user表,且已经建立好了一个与此表对应的实体类User,我们来介绍对user的简单增删改查操作。
建立DAO层接口。我们在使用普通的mybatis时会建立一个DAO层接口,并对应一个xml用来写SQL。在这里我们同样要建立一个DAO层接口,但是若无必要,我们甚至不需要建立xml,就可以进行资源的CURD操作了,我们只需要让我们建立的DAO继承MP提供的BaseMapper<?>即可:
public interface UserMapper extends BaseMapper
{
}
然后在我们需要做数据CURD时,像下边这样就好了:
Java代码
// 初始化 影响行数 int result = 0; // 初始化 User 对象 User user = new User(); // 插入 User (插入成功会自动回写主键到实体类) user.setName(“Tom”); result = userMapper.insert(user); // 更新 User user.setAge(18); result = userMapper.updateById(user);//user要设置id哦,具体的在下边我会详细介绍 // 查询 User User exampleUser = userMapper.selectById(user.getId()); // 查询姓名为‘张三'的所有用户记录 List userList = userMapper.selectList( new EntityWrapper().eq(“name”, “张三”) ); // 删除 User result = userMapper.deleteById(user.getId());
方便吧?如果只使用mybatis可是要写4个SQL和4个方法喔,当然了,仅仅上边这几个方法还远远满足不了我们的需求,请往下看:
**
多条件分页查询:
**
Java代码
// 分页查询 10 条姓名为‘张三'、性别为男,且年龄在18至50之间的用户记录
List<User> userList = userMapper.selectPage(
new Page<User>(1, 10),
new EntityWrapper<User>().eq("name", "张三")
.eq("sex", 0)
.between("age", "18", "50")
);
/**等价于SELECT * *FROM sys_user *WHERE (name=‘张三' AND sex=0 AND age BETWEEN ‘18' AND ‘50') *LIMIT 0,10 */
下边这个,多条件构造器。其实对于条件过于复杂的查询,笔者还是建议使用原生mybatis的方式实现,易于维护且逻辑清晰,如果所有的数据操作都强行使用MP,就失去了MP简化开发的意义了。所以在使用时请按实际情况取舍,在这里还是先介绍一下。
public Page<T> selectPage(Page<T> page, EntityWrapper<T> entityWrapper) {
if (null != entityWrapper) {
entityWrapper.orderBy(page.getOrderByField(), page.isAsc());//排序
}
page.setRecords(baseMapper.selectPage(page, entityWrapper));//将查询结果放入page中
return page;
}
**条件构造一(上边方法的entityWrapper参数):**
public void testTSQL11() {
/*
* 实体带查询使用方法 输出看结果
*/
EntityWrapper<User> ew = new EntityWrapper<User>();
ew.setEntity(new User(1));
ew.where("user_name={0}", "'zhangsan'").and("id=1")
.orNew("user_status={0}", "0").or("status=1")
.notLike("user_nickname", "notvalue")
.andNew("new=xx").like("hhh", "ddd")
.andNew("pwd=11").isNotNull("n1,n2").isNull("n3")
.groupBy("x1").groupBy("x2,x3")
.having("x1=11").having("x3=433")
.orderBy("dd").orderBy("d1,d2");
System.out.println(ew.getSqlSegment());
}
**条件构造二(同上):**
int buyCount = selectCount(Condition.create()
.setSqlSelect(“sum(quantity)”)
.isNull(“order_id”)
.eq(“user_id”, 1)
.eq(“type”, 1)
.in(“status”, new Integer[]{0, 1})
.eq(“product_id”, 1)
.between(“created_time”, startDate, currentDate)
.eq(“weal”, 1));
自定义条件使用entityWrapper:
List selectMyPage(RowBounds rowBounds, @Param(“ew”) Wrapper wrapper);
SELECT * FROM user ${ew.sqlSegment} *注意:此处不用担心SQL注入,MP已对ew做了字符串转义处理。其实在使用MP做数据CURD时,还有另外一个方法,AR(ActiveRecord ),很简单,让我们的实体类继承MP提供Model<?>就好了,这和我们常用的方法可能会有些不同,下边简单说一下吧:*
//实体类
@TableName(“sys_user”) // 注解指定表名
public class User extends Model {
… // fields
… // getter and setter
/** 指定主键 */
@Override
protected Serializable pkVal() { //一定要指定主键哦
return this.id;
}
}
下边就是CURD操作了:
// 初始化 成功标识 boolean result = false; // 初始化 User User user = new User(); // 保存 User user.setName(“Tom”); result = user.insert(); // 更新 User user.setAge(18); result = user.updateById(); // 查询 User User exampleUser = t1.selectById(); // 查询姓名为‘张三'的所有用户记录 List userList1 = user.selectList( new EntityWrapper().eq(“name”, “张三”) ); // 删除 User result = t2.deleteById(); // 分页查询 10 条姓名为‘张三'、性别为男,且年龄在18至50之间的用户记录 List userList = user.selectPage( new Page(1, 10), new EntityWrapper().eq(“name”, “张三”) .eq(“sex”, 0) .between(“age”, “18”, “50”) ).getRecords();
就是这样了,可能你会说MP封装的有些过分了,这样做会分散数据逻辑到不同的层面中,难以管理,使代码难以理解。其实确实是这样,这就需要你在使用的时候注意一下了,在简化开发的同时也要保证你的代码层次清晰,做一个战略上的设计或者做一个取舍与平衡。
**
其实上边介绍的功能也不是MP的全部啦,下边介绍一下MP最有意思的模块——代码生成器。
**
步骤↓:
如上边所说,使用代码生成器一定要引入velocity-engine-core(模板引擎)这个依赖。
准备工作:
选择主键策略,就是在上边最开始时候我介绍MP配置时其中的这项配置,如果你不记得了,请上翻!MP提供了如下几个主键策略: 值 描述
IdType.AUTO数据库ID自增
IdType.INPUT用户输入ID
IdType.ID_WORKER全局唯一ID,内容为空自动填充(默认配置)
IdType.UUID全局唯一ID,内容为空自动填充
MP默认使用的是ID_WORKER,这是MP在Sequence的基础上进行部分优化,用于产生全局唯一ID。
表及字段命名策略选择,同上,还是在那个配置中。下边这段复制至MP官方文档:
在MP中,我们建议数据库表名采用下划线命名方式,而表字段名采用驼峰命名方式。
这么做的原因是为了避免在对应实体类时产生的性能损耗,这样字段不用做映射就能直接和实体类对应。当然如果项目里不用考虑这点性能损耗,那么你采用下滑线也是没问题的,只需要在生成代码时配置dbColumnUnderline属性就可以。
建表(命名规则依照刚才你所配置的,这会影响生成的代码的类名、字段名是否正确)。
执行下边的main方法,生成代码:
import java.util.HashMap;
import java.util.Map;
import com.baomidou.mybatisplus.generator.AutoGenerator;
import com.baomidou.mybatisplus.generator.InjectionConfig;
import com.baomidou.mybatisplus.generator.config.DataSourceConfig;
import com.baomidou.mybatisplus.generator.config.GlobalConfig;
import com.baomidou.mybatisplus.generator.config.PackageConfig;
import com.baomidou.mybatisplus.generator.config.StrategyConfig;
import com.baomidou.mybatisplus.generator.config.rules.DbType;
import com.baomidou.mybatisplus.generator.config.rules.NamingStrategy;
/**
* <p>
* 代码生成器演示
* </p>
*/
public class MpGenerator {
/**
* <p>
* MySQL 生成演示
* </p>
*/
public static void main(String[] args) {
AutoGenerator mpg = new AutoGenerator();
// 全局配置
GlobalConfig gc = new GlobalConfig();
gc.setOutputDir("D://");
gc.setFileOverride(true);
gc.setActiveRecord(true);// 不需要ActiveRecord特性的请改为false
gc.setEnableCache(false);// XML 二级缓存
gc.setBaseResultMap(true);// XML ResultMap
gc.setBaseColumnList(false);// XML columList
// .setKotlin(true) 是否生成 kotlin 代码
gc.setAuthor("Yanghu");
// 自定义文件命名,注意 %s 会自动填充表实体属性!
// gc.setMapperName("%sDao");
// gc.setXmlName("%sDao");
// gc.setServiceName("MP%sService");
// gc.setServiceImplName("%sServiceDiy");
// gc.setControllerName("%sAction");
mpg.setGlobalConfig(gc);
// 数据源配置
DataSourceConfig dsc = new DataSourceConfig();
dsc.setDbType(DbType.MYSQL);
dsc.setTypeConvert(new MySqlTypeConvert(){
// 自定义数据库表字段类型转换【可选】
@Override
public DbColumnType processTypeConvert(String fieldType) {
System.out.println("转换类型:" + fieldType);
// 注意!!processTypeConvert 存在默认类型转换,如果不是你要的效果请自定义返回、非如下直接返回。
return super.processTypeConvert(fieldType);
}
});
dsc.setDriverName("com.mysql.jdbc.Driver");
dsc.setUsername("root");
dsc.setPassword("521");
dsc.setUrl("jdbc:mysql://127.0.0.1:3306/mybatis-plus?characterEncoding=utf8");
mpg.setDataSource(dsc);
// 策略配置
StrategyConfig strategy = new StrategyConfig();
// strategy.setCapitalMode(true);// 全局大写命名 ORACLE 注意
strategy.setTablePrefix(new String[] { "tlog_", "tsys_" });// 此处可以修改为您的表前缀
strategy.setNaming(NamingStrategy.underline_to_camel);// 表名生成策略
// strategy.setInclude(new String[] { "user" }); // 需要生成的表
// strategy.setExclude(new String[]{"test"}); // 排除生成的表
// 自定义实体父类
// strategy.setSuperEntityClass("com.baomidou.demo.TestEntity");
// 自定义实体,公共字段
// strategy.setSuperEntityColumns(new String[] { "test_id", "age" });
// 自定义 mapper 父类
// strategy.setSuperMapperClass("com.baomidou.demo.TestMapper");
// 自定义 service 父类
// strategy.setSuperServiceClass("com.baomidou.demo.TestService");
// 自定义 service 实现类父类
// strategy.setSuperServiceImplClass("com.baomidou.demo.TestServiceImpl");
// 自定义 controller 父类
// strategy.setSuperControllerClass("com.baomidou.demo.TestController");
// 【实体】是否生成字段常量(默认 false)
// public static final String ID = "test_id";
// strategy.setEntityColumnConstant(true);
// 【实体】是否为构建者模型(默认 false)
// public User setName(String name) {this.name = name; return this;}
// strategy.setEntityBuilderModel(true);
mpg.setStrategy(strategy);
// 包配置
PackageConfig pc = new PackageConfig();
pc.setParent("com.baomidou");
pc.setModuleName("test");
mpg.setPackageInfo(pc);
// 注入自定义配置,可以在 VM 中使用 cfg.abc 【可无】
InjectionConfig cfg = new InjectionConfig() {
@Override
public void initMap() {
Map<String, Object> map = new HashMap<String, Object>();
map.put("abc", this.getConfig().getGlobalConfig().getAuthor() + "-mp");
this.setMap(map);
}
};
// 自定义 xxList.jsp 生成
List<FileOutConfig> focList = new ArrayList<FileOutConfig>();
focList.add(new FileOutConfig("/template/list.jsp.vm") {
@Override
public String outputFile(TableInfo tableInfo) {
// 自定义输入文件名称
return "D://my_" + tableInfo.getEntityName() + ".jsp";
}
});
cfg.setFileOutConfigList(focList);
mpg.setCfg(cfg);
// 调整 xml 生成目录演示
focList.add(new FileOutConfig("/templates/mapper.xml.vm") {
@Override
public String outputFile(TableInfo tableInfo) {
return "/develop/code/xml/" + tableInfo.getEntityName() + ".xml";
}
});
cfg.setFileOutConfigList(focList);
mpg.setCfg(cfg);
// 关闭默认 xml 生成,调整生成 至 根目录
TemplateConfig tc = new TemplateConfig();
tc.setXml(null);
mpg.setTemplate(tc);
// 自定义模板配置,可以 copy 源码 mybatis-plus/src/main/resources/templates 下面内容修改,
// 放置自己项目的 src/main/resources/templates 目录下, 默认名称一下可以不配置,也可以自定义模板名称
// TemplateConfig tc = new TemplateConfig();
// tc.setController("...");
// tc.setEntity("...");
// tc.setMapper("...");
// tc.setXml("...");
// tc.setService("...");
// tc.setServiceImpl("...");
// 如上任何一个模块如果设置 空 OR Null 将不生成该模块。
// mpg.setTemplate(tc);
// 执行生成
mpg.execute();
// 打印注入设置【可无】
System.err.println(mpg.getCfg().getMap().get("abc"));
}
}
说明:中间的内容请自行修改,注释很清晰。
成功生成代码,将生成的代码拷贝到你的项目中就可以了,这个东西节省了我们大量的时间和精力!
以下是注解说明,摘自官方文档: 注解说明**
表名注解 @TableName
com.baomidou.mybatisplus.annotations.TableName
值 描述
value表名( 默认空 )
resultMapxml 字段映射 resultMap ID
主键注解 @TableId
com.baomidou.mybatisplus.annotations.TableId
值 描述
value字段值(驼峰命名方式,该值可无)
type主键 ID 策略类型( 默认 INPUT ,全局开启的是 ID_WORKER )
暂不支持组合主键
字段注解 @TableField
com.baomidou.mybatisplus.annotations.TableField
值 描述
value字段值(驼峰命名方式,该值可无)
el详看注释说明
exist是否为数据库表字段( 默认 true 存在,false 不存在 )
strategy字段验证 ( 默认 非 null 判断,查看 com.baomidou.mybatisplus.enums.FieldStrategy )
fill字段填充标记 ( FieldFill, 配合自动填充使用 )
字段填充策略 FieldFill
值 描述
DEFAULT默认不处理
INSERT插入填充字段
UPDATE更新填充字段
INSERT_UPDATE插入和更新填充字段
序列主键策略 注解 @KeySequence
com.baomidou.mybatisplus.annotations.KeySequence
值 描述
value序列名
clazzid的类型
乐观锁标记注解 @Version
com.baomidou.mybatisplus.annotations.Version
排除非表字段、查看文档常见问题部分!
总结:MP的宗旨是简化开发,但是它在提供方便的同时却容易造成代码层次混乱,我们可能会把大量数据逻辑写到service层甚至contoller层中,使代码难以阅读。凡事过犹不及,在使用MP时一定要做分析,不要将所有数据操作都交给MP去实现。毕竟MP只是mybatis的增强工具,它并没有侵入mybatis的原生功能,在使用MP的增强功能的同时,原生mybatis的功能依然是可以正常使用的
到此这篇关于Mybatis-Plus和Mybatis的区别详解的文章就介绍到这了,更多相关Mybatis-Plus和Mybatis的区别内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!