
浅谈如何使用python抓取网页中的动态数据实现
作者:saintlas
我们经常会发现网页中的许多数据并不是写死在HTML中的,而是通过js动态载入的。所以也就引出了什么是动态数据的概念,动态数据在这里指的是网页中由Javascript动态生成的页面内容,是在页面加载到浏览器后动态生成的,而之前并没有的。
在编写爬虫进行网页数据抓取的时候,经常会遇到这种需要动态加载数据的HTML网页,如果还是直接从网页上抓取那么将无法获得任何数据。
今天,我们就在这里简单聊一聊如何用python来抓取页面中的JS动态加载的数据。
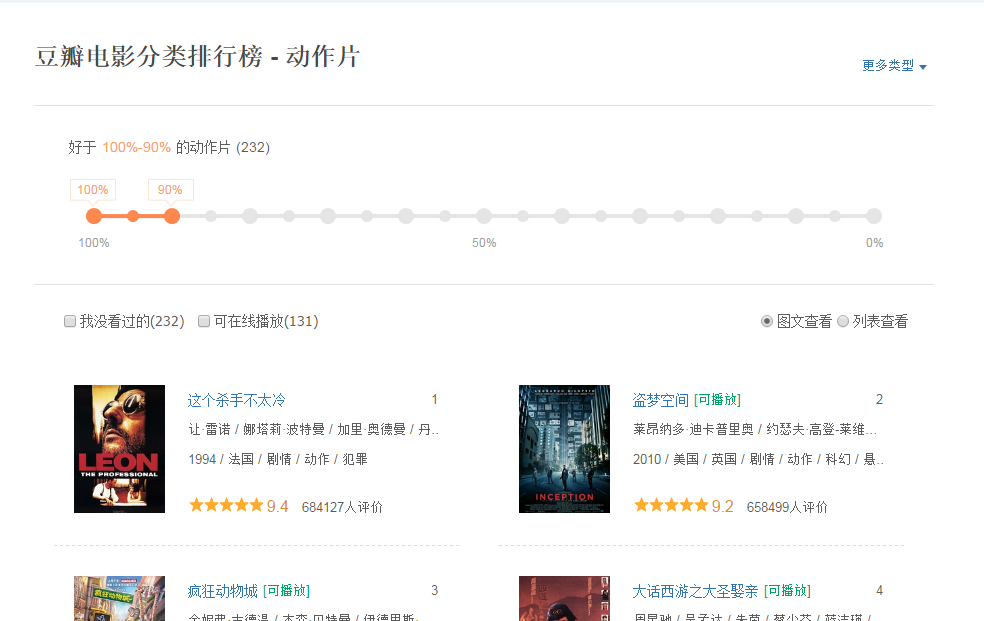
给出一个网页:豆瓣电影排行榜,其中的所有电影信息都是动态加载的。我们无法直接从页面中获得每个电影的信息。
如下图所示,我们无法在HTML中找到对应的电影信息。
在Chrome浏览器中,点击F12,打开Network中的XHR,我们来抓取对应的js文件来进行解析。如下图:

在豆瓣页面向下拖拽,使得页面加载入更多的电影信息,从而我们可以抓取对应的报文。
我们可以看到它采用的是AJAX异步请求。通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。因此就可以在不重新加载整个网页的情况下,对网页的某部分进行更新,从而实现数据的动态载入。

我们可以看到,通过GET,我们得到的response之中包含了所对应的电影相关信息,它们以JSON的格式保存在一起。

查看一下RequestURL信息,我们可以发现在action参数之后又跟了两个参数"start"和"limit",很显然它们的意思是:"从某个位置开始返回的电影的个数"。
如果想快速获取相关的电影信息,就可以直接把这个URL复制进地址栏,修改你所需要的start和limit参数值,将得到对应的结果进行抓取即可。
但是这样显得很不自动化,而且很多其他网站的RequestURL并不给的这么直接,所以我们接下来用python进行进一步的操作来获取这个返回的报文信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90",data =post_param, verify = False)
print return_data.text
因为豆瓣是https的,所以我们在此处需要稍微注意一下,将verify置为False表示不需要验证SSL证书。
我们可以发现打印出的结果中就是对应的JSON文件,下一步的解析和操作在这里就不赘述了。
[{"rating":["9.6","50"],"rank":1,"cover_url":"https://img3.doubanio.com\/view\/movie_poster_cover\/mpst\/public\/p480747492.jpg","is_playable":true,"id":"1292052","types":["犯罪","剧情"],"regions":["美国"],"title":"肖申克的救赎","url":"https:\/\/movie.douban.com\/subject\/1292052\/","release_date":"1994-09-10","actor_count":15,"vote_count":713205,"score":"9.6","actors":["蒂姆·罗宾斯","摩根·弗里曼","鲍勃·冈顿","威廉姆·赛德勒","克兰西·布朗","吉尔·贝罗斯","马克·罗斯顿","詹姆斯·惠特摩","杰弗里·德曼","拉里·布兰登伯格","尼尔·吉恩托利","布赖恩·利比","大卫·普罗瓦尔","约瑟夫·劳格诺","祖德·塞克利拉"],"is_watched":false}]
到此这篇关于浅谈如何使用python抓取网页中的动态数据实现的文章就介绍到这了,更多相关python抓取网页动态数据 内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!