
超强变态的正则(\w)((?=\1\1\1)(\1))+讲解
作者:dxy
这个正则出自这个网站 http://www.regexlab.com/zh/regref.htm
正向预搜索:"(?=xxxxx)","(?!xxxxx)"
格式:"(?=xxxxx)",在被匹配的字符串中,它对所处的 "缝隙" 或者 "两头" 附加的条件是:所在缝隙的右侧,必须能够匹配上 xxxxx 这部分的表达式。因为它只是在此作为这个缝隙上附加的条件,所以它并不影响后边的表达式去真正匹配这个缝隙之后的字符。这就类似 "\b",本身不匹配任何字符。"\b" 只是将所在缝隙之前、之后的字符取来进行了一下判断,不会影响后边的表达式来真正的匹配。
点击测试 举例1:表达式 "Windows (?=NT|XP)" 在匹配 "Windows 98, Windows NT, Windows 2000" 时,将只匹配 "Windows NT" 中的 "Windows ",其他的 "Windows " 字样则不被匹配。
点击测试 举例2:表达式 "(\w)((?=\1\1\1)(\1))+" 在匹配字符串 "aaa ffffff 999999999" 时,将可以匹配6个"f"的前4个,可以匹配9个"9"的前7个。这个表达式可以读解成:重复4次以上的字母数字,则匹配其剩下最后2位之前的部分。当然,这个表达式可以不这样写,在此的目的是作为演示之用。
例子:例如 999999999 或 666666
1、(\w)((?=\1\1\1)(\1))+
最后的+号意思是一个或多个 意思就是 666666之匹配前四个6,而999999999只匹配前面7个,后面反正要留两个
因为用了(?=\1\1),每次只匹配两个,但保证右侧有99,每次都取两个,每次都包括之前的一个
(\w)((?=\1\1\1)(\1))+在999999999 中实际上是被匹配了6次。
第一次:(\w)取出第一个9,(?=\1\1\1)限定第2个9到第4个9,(\1)取出第2个9,得到99
第二次:(?=\1\1\1)限定第3个9到第5个9,(\1)取出第3个9,得到999
第三次:(?=\1\1\1)限定第4个9到第6个9,(\1)取出第4个9,得到9999
第四次:(?=\1\1\1)限定第5个9到第7个9,(\1)取出第5个9,得到99999
第五次:(?=\1\1\1)限定第6个9到第8个9,(\1)取出第6个9,得到999999
第六次:(?=\1\1\1)限定第7个9到第9个9,(\1)取出第7个9,得到9999999
2、(\w)((\1)(?=\1\1))+
第一次 \w取出第一个9,\1再取1个9就是 99 后面紧跟两个9才符合条件 所有第一次就是99
第二次 从第3个9到第四个9, 开始就\1 再取一个 999
第三次 匹配从第4-6个9 取一个 9999
第四次 从第5-7个9取一个 取一个99999
第五次 从第6-8个9 取一个 是 999999
第六次 从第7-9个9 后面仍满足取一个是 9999999
第七次 第8个开始右侧已经不够三个9了,所有取消匹配,匹配之前的7个9
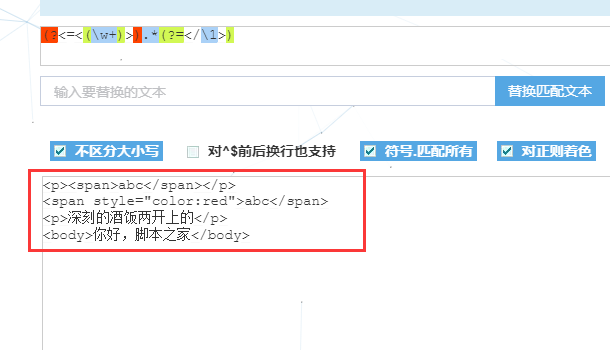
3、 (?<=<(\w+)>).*(?=<\/\1>)
详细解释下:?<=和?=都表示零宽断言,一个匹配后面一个匹配前面,
对应到上面的例子中,亦即.*前面必须要有<(\w+)>,后面必须要有<\/\1>。
零宽断言不体现到最终的匹配结果中。
再细看下,<(\w+)>匹配<tag>类型,\w表示数字、字母、下划线;<\/\1>中\/匹配斜杠/,
\1表示捕获组,亦即从正则表达式左边开始的第一个小括号中的内容,注意这里不包含零宽断言的括号,在上例中表示(\w+)中的部分。
中间的.*表示任意多个非换行符。
总结下:匹配类似<tag>content</tag>格式中的content部分
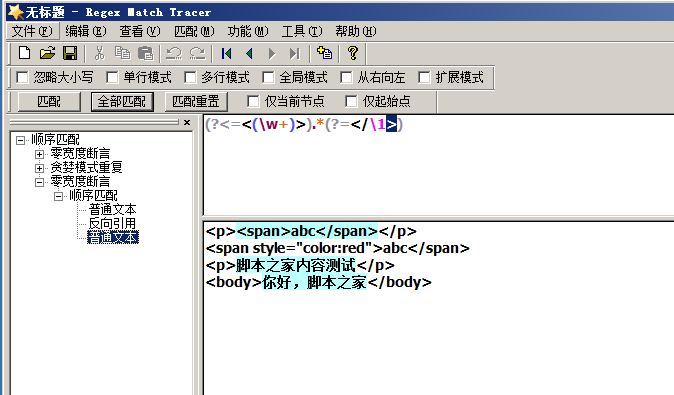
不过经过测试网页版的js匹配不到,还是Regex Match Tracer中比较好用,推荐大家下载学习
网页版看不到效果
用软件就可以
所有大家在使用的时候,要测试你的语言是否支持。
正则表达式看懂的最好方法就是一步步分开解析:
1)以 '.*' 为分界,前面括号中的内容可以划分为 ‘?<=' 和 ‘<(\w+)>',其中‘<(\w+)>'表示匹配尖括号里面是字母、数字或下划线的内容,类似<span>,外面还要加个括号是要实现分组;而‘?<='用到的是零宽断言语法,表示的是断定‘<(\w+)>'后面有或没有内容,而且与内容的间隔宽度为零。
2)再看' .* '后面的部分,括号里面的内容可以分为 ‘?=' 和 ‘<(\/\1>',其中‘?='用零宽断言表示匹配‘<(\/\1>'前面的部分,而对于‘<(\/\1>',‘\/'匹配‘/'符号,类似</span>,这里可能有些同学不太明白‘\1'是什么意思?这里用到的是捕获分组的思想,上述提到的‘<(\w+)>'外面加个小括号就表示一个分组,对于正则表达式的分组结果,索引 0表示匹配的整个内容,而1表示的是第1个子分组,所以这里的'\1'指向的就是前面的第一个分组‘<(\w+)>',\2表示重复第2个子项,\n表示重复第n个子项;
3).* 就比较简单了,表示的是匹配 除了换行符意外的任意字符0次或多次。
综上,改表达式匹配的是类似html标签这种内容的,如<body>你好,正则!</body>
下面是脚本之家小编写的打算将不带style的span替换为空的正则。
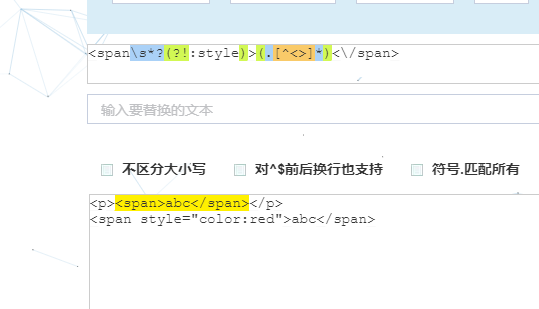
str=str.replace(/<span\s*?(?!:style)>(.[^<>]*)<\/span>/ig,"$1");
不可能用的,要不所有的内容都乱了。
文中相关测试工具
下面接这个为大家分享这几个高级规则
预搜索,不匹配;反向预搜索,不匹配
前面的章节中,我讲到了几个代表抽象意义的特殊符号:"^","$","\b"。它们都有一个共同点,那就是:它们本身不匹配任何字符,只是对 "字符串的两头" 或者 "字符之间的缝隙" 附加了一个条件。理解到这个概念以后,本节将继续介绍另外一种对 "两头" 或者 "缝隙" 附加条件的,更加灵活的表示方法。
正向预搜索:"(?=xxxxx)","(?!xxxxx)"
格式:"(?=xxxxx)",在被匹配的字符串中,它对所处的 "缝隙" 或者 "两头" 附加的条件是:所在缝隙的右侧,必须能够匹配上 xxxxx 这部分的表达式。因为它只是在此作为这个缝隙上附加的条件,所以它并不影响后边的表达式去真正匹配这个缝隙之后的字符。这就类似 "\b",本身不匹配任何字符。"\b" 只是将所在缝隙之前、之后的字符取来进行了一下判断,不会影响后边的表达式来真正的匹配。
点击测试 举例1:表达式 "Windows (?=NT|XP)" 在匹配 "Windows 98, Windows NT, Windows 2000" 时,将只匹配 "Windows NT" 中的 "Windows ",其他的 "Windows " 字样则不被匹配。
点击测试 举例2:表达式 "(\w)((?=\1\1\1)(\1))+" 在匹配字符串 "aaa ffffff 999999999" 时,将可以匹配6个"f"的前4个,可以匹配9个"9"的前7个。这个表达式可以读解成:重复4次以上的字母数字,则匹配其剩下最后2位之前的部分。当然,这个表达式可以不这样写,在此的目的是作为演示之用。
格式:"(?!xxxxx)",所在缝隙的右侧,必须不能匹配 xxxxx 这部分表达式。
点击测试 举例3:表达式 "((?!\bstop\b).)+" 在匹配 "fdjka ljfdl stop fjdsla fdj" 时,将从头一直匹配到 "stop" 之前的位置,如果字符串中没有 "stop",则匹配整个字符串。
点击测试 举例4:表达式 "do(?!\w)" 在匹配字符串 "done, do, dog" 时,只能匹配 "do"。在本条举例中,"do" 后边使用 "(?!\w)" 和使用 "\b" 效果是一样的。
反向预搜索:"(?<=xxxxx)","(?<!xxxxx)"
这两种格式的概念和正向预搜索是类似的,反向预搜索要求的条件是:所在缝隙的 "左侧",两种格式分别要求必须能够匹配和必须不能够匹配指定表达式,而不是去判断右侧。与 "正向预搜索" 一样的是:它们都是对所在缝隙的一种附加条件,本身都不匹配任何字符。
举例5:表达式 "(?<=\d{4})\d+(?=\d{4})" 在匹配 "1234567890123456" 时,将匹配除了前4个数字和后4个数字之外的中间8个数字。由于 JScript.RegExp 不支持反向预搜索,因此,本条举例不能够进行演示。很多其他的引擎可以支持反向预搜索,比如:Java 1.4 以上的 java.util.regex 包,.NET 中System.Text.RegularExpressions 命名空间,以及本站推荐的最简单易用的 DEELX 正则引擎。
到此这篇关于超强变态的正则(\w)((?=\1\1\1)(\1))+讲解的文章就介绍到这了,更多相关正则表达式高级规则内容请搜素脚本之家以前的文章或下面相关文章,希望大家以后多多支持脚本之家!