
使用Tensorflow将自己的数据分割成batch训练实例
作者:非典型废言
学习神经网络的时候,网上的数据集已经分割成了batch,训练的时候直接使用batch.next()就可以获取batch,但是有的时候需要使用自己的数据集,然而自己的数据集不是batch形式,就需要将其转换为batch形式,本文将介绍一个将数据打包成batch的方法。
一、tf.slice_input_producer()
首先需要讲解两个函数,第一个函数是 :tf.slice_input_producer(),这个函数的作用是从输入的tensor_list按要求抽取一个tensor放入文件名队列,下面解释下各个参数:
tf.slice_input_producer(tensor_list, num_epochs=None, shuffle=True, seed=None,
capacity=32, shared_name=None, name=None)
tensor_list 这个就是输入,格式为tensor的列表;一般为[data, label],即由特征和标签组成的数据集
num_epochs 这个是你抽取batch的次数,如果没有给定值,那么将会抽取无数次batch(这会导致你训练过程停不下来),如果给定值,那么在到达次数之后就会报OutOfRange的错误
shuffle 是否随机打乱,如果为False,batch是按顺序抽取;如果为True,batch是随机抽取
seed 随机种子
capcity 队列容量的大小,为整数
name 名称
举个例子:我的data的shape为(4000,10),label的shape为(4000,2),运行下面这行代码
input_queue = tf.train.slice_input_producer([data, label], num_epochs=1, shuffle=True, capacity=32 )
结果如图,可以看出返回值为一个包含两组数据的list,每个list的shape与输入的data和label的shape对应
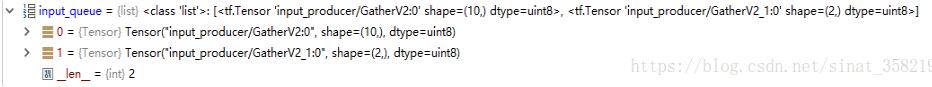
二、tf.train.batch()& tf.train.shuffle_batch()
第二个函数为:tf.train.batch(),tf.train.shuffle_batch(),这个函数的作用为生成大小为batch_size的tensor,下面解释下各个参数:
tf.train.batch([data, label], batch_size=batch_size, capacity=capacity,num_threads=num_thread,allow_smaller_final_batch= True) tf.train.shuffle_batch([example, label], batch_size=batch_size, capacity=capacity,num_threads=num_thread,allow_smaller_final_batch=True)
[data,label] 输入的样本和标签
batch_size batch的大小
capcity 队列的容量
num_threads 线程数,使用多少个线程来控制整个队列
allow_smaller_final_batch 这个是当最后的几个样本不够组成一个batch的时候用的参数,如果为True则会重新组成一个batch
下面给出生成batch的函数,由上面两个函数组成:
def get_Batch(data, label, batch_size): print(data.shape, label.shape) input_queue = tf.train.slice_input_producer([data, label], num_epochs=1, shuffle=True, capacity=32 ) x_batch, y_batch = tf.train.batch(input_queue, batch_size=batch_size, num_threads=1, capacity=32, allow_smaller_final_batch=False) return x_batch, y_batch
还是同样的输入,batch_size设为2000,看下运行后的返回值的shape:

可以发现,返回是样本数目为2000的tensor,也就是达到了将自己的数据打包成batch的功能
三、batch的使用方法
生成batch只完成了一半,后面的使用方法也比较复杂,直接上一个完整的程序来讲解会方便理解一些:下面代码构建了一个单层感知机,对数据进行分类,主要看一下训练过程中如何使用生成好了的batch,具体细节都写在注释里面了。
import tensorflow as tf
import scipy.io as sio
import numpy as np
def get_Batch(data, label, batch_size):
print(data.shape, label.shape)
input_queue = tf.train.slice_input_producer([data, label], num_epochs=1, shuffle=True, capacity=32 )
x_batch, y_batch = tf.train.batch(input_queue, batch_size=batch_size, num_threads=1, capacity=32, allow_smaller_final_batch=False)
return x_batch, y_batch
data = sio.loadmat('data.mat')
train_x = data['train_x']
train_y = data['train_y']
test_x = data['test_x']
test_y = data['test_y']
x = tf.placeholder(tf.float32, [None, 10])
y = tf.placeholder(tf.float32, [None, 2])
w = tf.Variable(tf.truncated_normal([10, 2], stddev=0.1))
b = tf.Variable(tf.truncated_normal([2], stddev=0.1))
pred = tf.nn.softmax(tf.matmul(x, w) + b)
loss = tf.reduce_mean(-tf.reduce_sum(y * tf.log(pred), reduction_indices=[1]))
optimizer = tf.train.AdamOptimizer(2e-5).minimize(loss)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(pred, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32), name='evaluation')
x_batch, y_batch = get_Batch(train_x, train_y, 1000)
# 训练
with tf.Session() as sess:
#初始化参数
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
# 开启协调器
coord = tf.train.Coordinator()
# 使用start_queue_runners 启动队列填充
threads = tf.train.start_queue_runners(sess, coord)
epoch = 0
try:
while not coord.should_stop():
# 获取训练用的每一个batch中batch_size个样本和标签
data, label = sess.run([x_batch, y_batch])
sess.run(optimizer, feed_dict={x: data, y: label})
train_accuracy = accuracy.eval({x: data, y: label})
test_accuracy = accuracy.eval({x: test_x, y: test_y})
print("Epoch %d, Training accuracy %g, Testing accuracy %g" % (epoch, train_accuracy, test_accuracy))
epoch = epoch + 1
except tf.errors.OutOfRangeError: # num_epochs 次数用完会抛出此异常
print("---Train end---")
finally:
# 协调器coord发出所有线程终止信号
coord.request_stop()
print('---Programm end---')
coord.join(threads) # 把开启的线程加入主线程,等待threads结束
总共训练的次数为(样本数目/batch_size)*num_epochs
四、 简单生成Batch的方法
最近发现了一种简单生生成batch的方法,实现简单,操作方便,就是时间复杂度可能高了一点,直接上代码。通过np.random.choice方法每次在范围[0, len(all_data))内抽取大小为size的索引。然后通过这部分索引构建batch。
epoch = 150
for i in tqdm(range(epoch)):
# 在total_train_xs, total_train_ys数据集中随机抽取batch_size个样本出来
# 作为本轮迭代的训练数据batch_xs, batch_ys
batch_size = 1000
sample_idxs = np.random.choice(range(len(all_data)), size=batch_size)
batch_xs = []
batch_ys = []
val_sample_idxs = np.random.choice(range(len(all_data)), size=batch_size)
val_batch_xs = []
val_batch_ys = []
for j in range(batch_size):
train_id = sample_idxs[j]
batch_xs.append(all_data[train_id])
batch_ys.append(all_label[train_id])
val_id = val_sample_idxs[j]
val_batch_xs.append(all_data[val_id])
val_batch_ys.append(all_label[val_id])
batch_xs = np.array(batch_xs)
batch_ys = np.array(batch_ys)
val_batch_xs = np.array(val_batch_xs)
val_batch_ys = np.array(val_batch_ys)
# 喂训练数据进去训练
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
if i % 50 == 0:
y_train_pred = np.array(sess.run(y, feed_dict={x: batch_xs})).reshape(len(batch_xs))
y_pred = np.array(sess.run(y, feed_dict={x: val_batch_xs})).reshape(len(val_batch_xs))
# draw(y_test, y_pred)
print("Iteration %d, train RMSE %f, val RMSE %f" % (i, calcaulateRMSE(batch_ys, y_train_pred), calcaulateRMSE(val_batch_ys, y_pred)))
以上这篇使用Tensorflow将自己的数据分割成batch训练实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。