
PyTorch中topk函数的用法详解
作者:咆哮的阿杰
今天小编就为大家分享一篇PyTorch中topk函数的用法详解,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
听名字就知道这个函数是用来求tensor中某个dim的前k大或者前k小的值以及对应的index。
用法
torch.topk(input, k, dim=None, largest=True, sorted=True, out=None) -> (Tensor, LongTensor)
input:一个tensor数据
k:指明是得到前k个数据以及其index
dim: 指定在哪个维度上排序, 默认是最后一个维度
largest:如果为True,按照大到小排序; 如果为False,按照小到大排序
sorted:返回的结果按照顺序返回
out:可缺省,不要
topk最常用的场合就是求一个样本被网络认为前k个最可能属于的类别。我们就用这个场景为例,说明函数的使用方法。
假设一个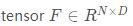 ,N是样本数目,一般等于batch size, D是类别数目。我们想知道每个样本的最可能属于的那个类别,其实可以用torch.max得到。如果要使用topk,则k应该设置为1。
,N是样本数目,一般等于batch size, D是类别数目。我们想知道每个样本的最可能属于的那个类别,其实可以用torch.max得到。如果要使用topk,则k应该设置为1。
import torch
pred = torch.randn((4, 5))
print(pred)
values, indices = pred.topk(1, dim=1, largest=True, sorted=True)
print(indices)
# 用max得到的结果,设置keepdim为True,避免降维。因为topk函数返回的index不降维,shape和输入一致。
_, indices_max = pred.max(dim=1, keepdim=True)
print(indices_max == indices)
# pred
tensor([[-0.1480, -0.9819, -0.3364, 0.7912, -0.3263],
[-0.8013, -0.9083, 0.7973, 0.1458, -0.9156],
[-0.2334, -0.0142, -0.5493, 0.0673, 0.8185],
[-0.4075, -0.1097, 0.8193, -0.2352, -0.9273]])
# indices, shape为 【4,1】,
tensor([[3], #【0,0】代表 第一个样本最可能属于第一类别
[2], # 【1, 0】代表第二个样本最可能属于第二类别
[4],
[2]])
# indices_max等于indices
tensor([[True],
[True],
[True],
[True]])
现在在尝试一下k=2
import torch
pred = torch.randn((4, 5))
print(pred)
values, indices = pred.topk(2, dim=1, largest=True, sorted=True) # k=2
print(indices)
# pred
tensor([[-0.2203, -0.7538, 1.8789, 0.4451, -0.2526],
[-0.0413, 0.6366, 1.1155, 0.3484, 0.0395],
[ 0.0365, 0.5158, 1.1067, -0.9276, -0.2124],
[ 0.6232, 0.9912, -0.8562, 0.0148, 1.6413]])
# indices
tensor([[2, 3],
[2, 1],
[2, 1],
[4, 1]])
可以发现indices的shape变成了【4, k】,k=2。
其中indices[0] = [2,3]。其意义是说明第一个样本的前两个最大概率对应的类别分别是第3类和第4类。
大家可以自行print一下values。可以发现values的shape和indices的shape是一样的。indices描述了在values中对应的值在pred中的位置。
以上这篇PyTorch中topk函数的用法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。