
python3常用的数据清洗方法(小结)
作者:竹子莱西
这篇文章主要介绍了python3常用的数据清洗方法(小结),文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
首先载入各种包:
import pandas as pd import numpy as np from collections import Counter from sklearn import preprocessing from matplotlib import pyplot as plt %matplotlib inline import seaborn as sns plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体 plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题 sns.set(font='SimHei') # 解决Seaborn中文显示问题
读入数据:这里数据是编造的
data=pd.read_excel('dummy.xlsx')
本案例的真实数据是这样的:

对数据进行多方位的查看:
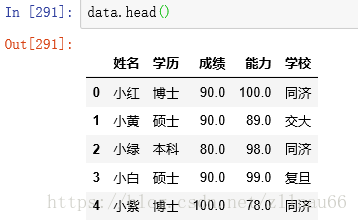
实际情况中可能会有很多行,一般用head()看数据基本情况
data.head() #查看长啥样 data.shape #查看数据的行列大小 data.describe()

#列级别的判断,但凡某一列有null值或空的,则为真 data.isnull().any() #将列中为空或者null的个数统计出来,并将缺失值最多的排前 total = data.isnull().sum().sort_values(ascending=False) print(total) #输出百分比: percent =(data.isnull().sum()/data.isnull().count()).sort_values(ascending=False) missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent']) missing_data.head(20)

也可以从视觉上直观查看缺失值:
import missingno missingno.matrix(data) data=data.dropna(thresh=data.shape[0]*0.5,axis=1) #至少有一半以上是非空的列筛选出来
#如果某一行全部都是na才删除: data.dropna(axis=0,how='all')

#默认情况下是只保留没有空值的行 data=data.dropna(axis=0)
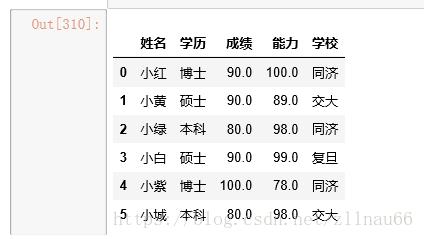
#统计重复记录数 data.duplicated().sum() data.drop_duplicates()
对连续型数据和离散型数据分开处理:
data.columns #第一步,将整个data的连续型字段和离散型字段进行归类 id_col=['姓名'] cat_col=['学历','学校'] #这里是离散型无序,如果有序,请参考map用法,一些博客上有写 cont_col=['成绩','能力'] #这里是数值型 print (data[cat_col]) #这里是离散型的数据部分 print (data[cont_col])#这里是连续性数据部分
对于离散型部分:
#计算出现的频次 for i in cat_col: print (pd.Series(data[i]).value_counts()) plt.plot(data[i])

#对于离散型数据,对其获取哑变量 dummies=pd.get_dummies(data[cat_col]) dummies
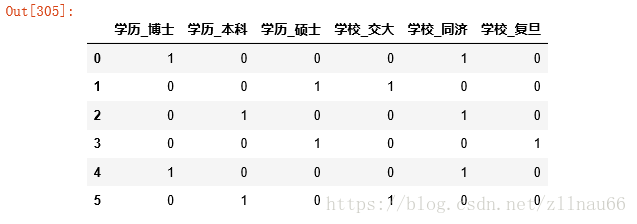
对于连续型部分:
#对于连续型数据的大概统计: data[cont_col].describe() #对于连续型数据,看偏度,一般大于0.75的数值做一个log转化,使之尽量符合正态分布,因为很多模型的假设数据是服从正态分布的 skewed_feats = data[cont_col].apply(lambda x: (x.dropna()).skew() )#compute skewness skewed_feats = skewed_feats[skewed_feats > 0.75] skewed_feats = skewed_feats.index data[skewed_feats] = np.log1p(data[skewed_feats]) skewed_feats
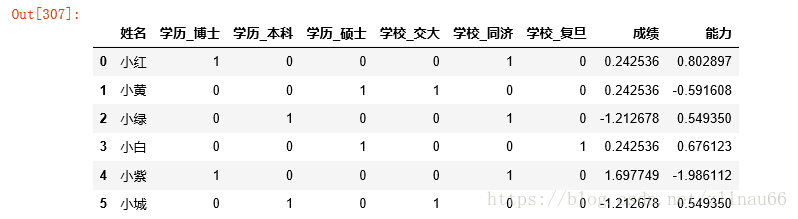
#对于连续型数据,对其进行标准化 scaled=preprocessing.scale(data[cont_col]) scaled=pd.DataFrame(scaled,columns=cont_col) scaled

m=dummies.join(scaled) data_cleaned=data[id_col].join(m) data_cleaned
看变量之间的相关性:
data_cleaned.corr()

#以下是相关性的热力图,方便肉眼看
def corr_heat(df):
dfData = abs(df.corr())
plt.subplots(figsize=(9, 9)) # 设置画面大小
sns.heatmap(dfData, annot=True, vmax=1, square=True, cmap="Blues")
# plt.savefig('./BluesStateRelation.png')
plt.show()
corr_heat(data_cleaned)

如果有觉得相关性偏高的视情况删减某些变量。
#取出与某个变量(这里指能力)相关性最大的前四个,做出热点图表示
k = 4 #number of variables for heatmap
cols = corrmat.nlargest(k, '能力')['能力'].index
cm = np.corrcoef(data_cleaned[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。