
IntelliJ IDEA下Maven创建Scala项目的方法步骤
作者:Python之简
环境:IntelliJ IDEA
版本:Spark-2.2.1 Scala-2.11.0
利用 Maven 第一次创建 Scala 项目也遇到了许多坑
创建一个 Scala 的 WordCount 程序
第一步:IntelliJ IDEA下安装 Scala 插件
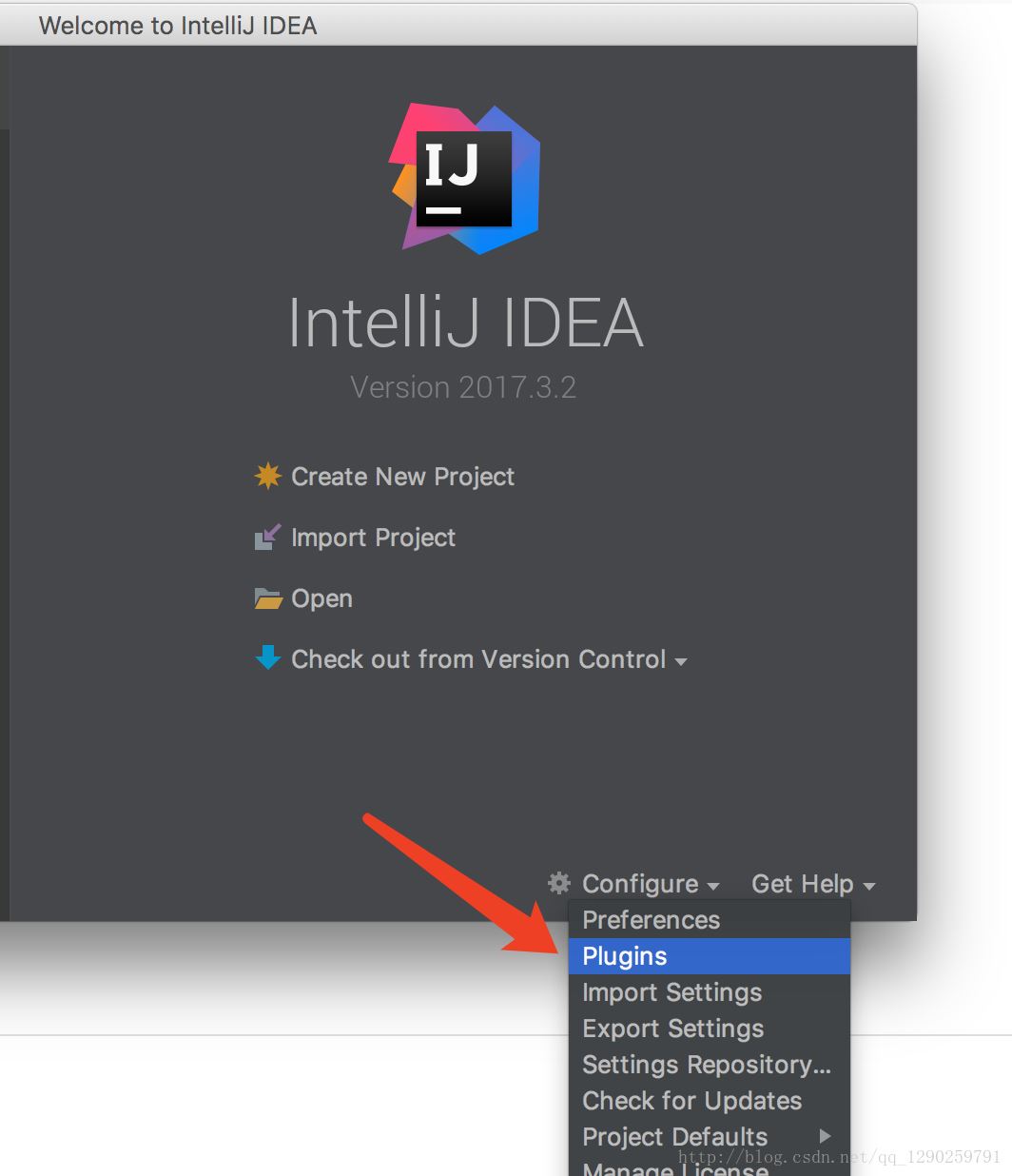
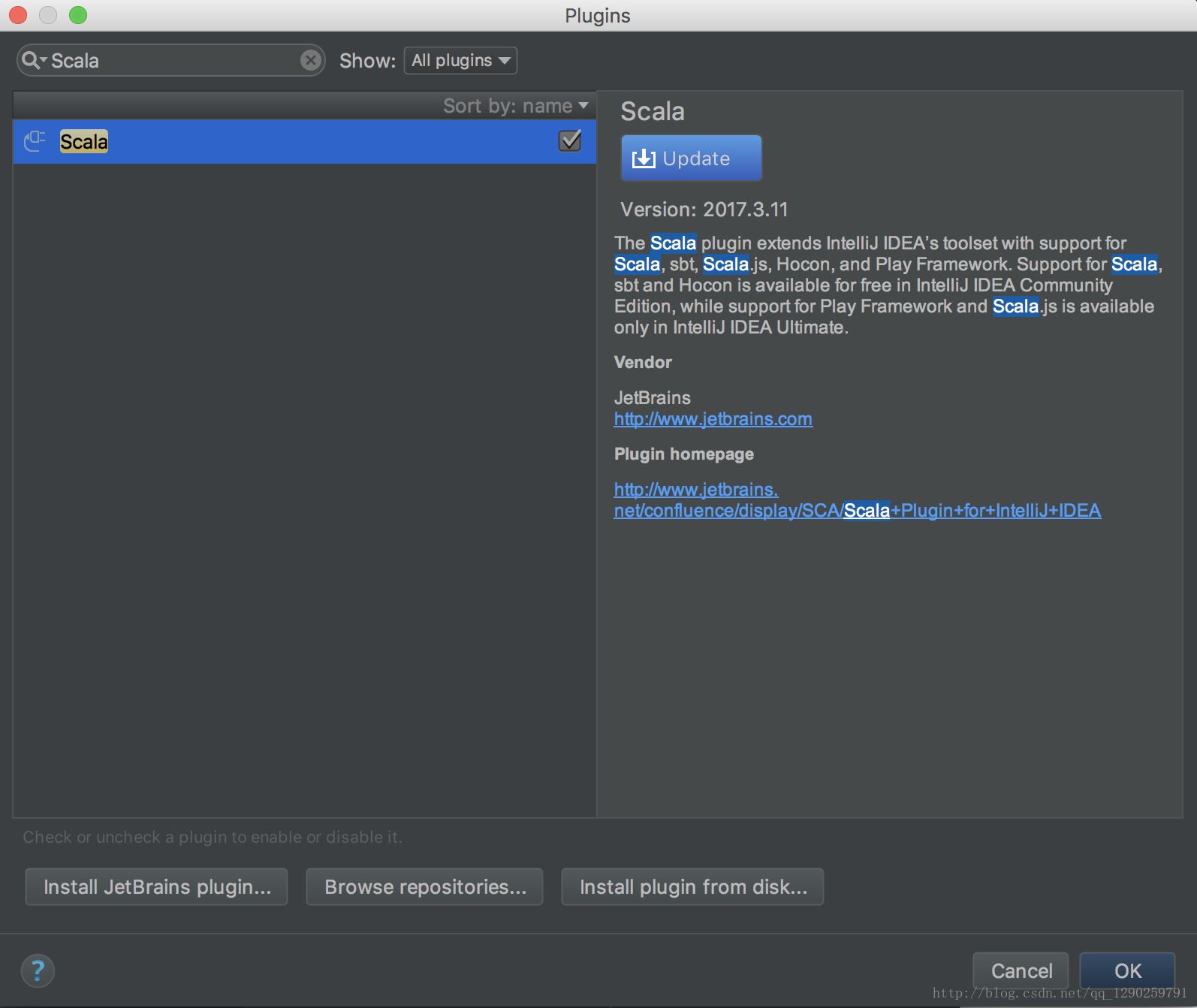
安装完 Scala 插件完成
第二步:Maven 下 Scala 下的项目创建
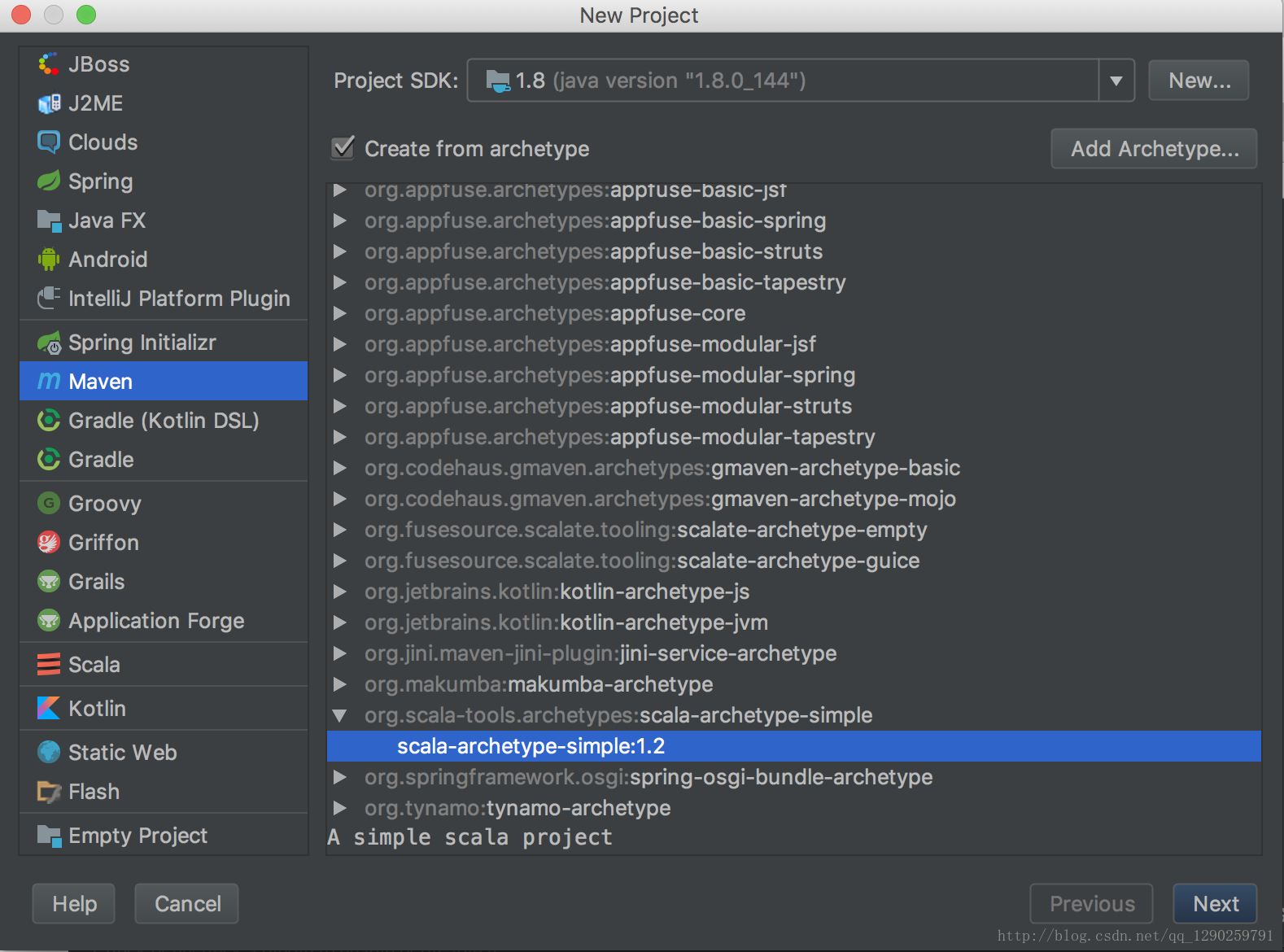
正常创建 Maven 项目(不会的看另一篇 Maven 配置)
第三步:Scala 版本的下载及配置
通过Spark官网下载页面http://spark.apache.org/downloads.html 可知“Note: Starting version 2.0, Spark is built with Scala 2.11 by default.”,建议下载Spark2.2对应的 Scala 2.11。
登录Scala官网http://www.scala-lang.org/,单击download按钮,然后再“Other Releases”标题下找到“下载2.11.0
根据自己的系统下载相应的版本
接下来就是配置Scala 的环境变量(跟 jdk 的配置方法一样)
输入 Scala -version 查看是否配置成功 会显示 Scala code runner version 2.11.0 – Copyright 2002-2013, LAMP/EPFL
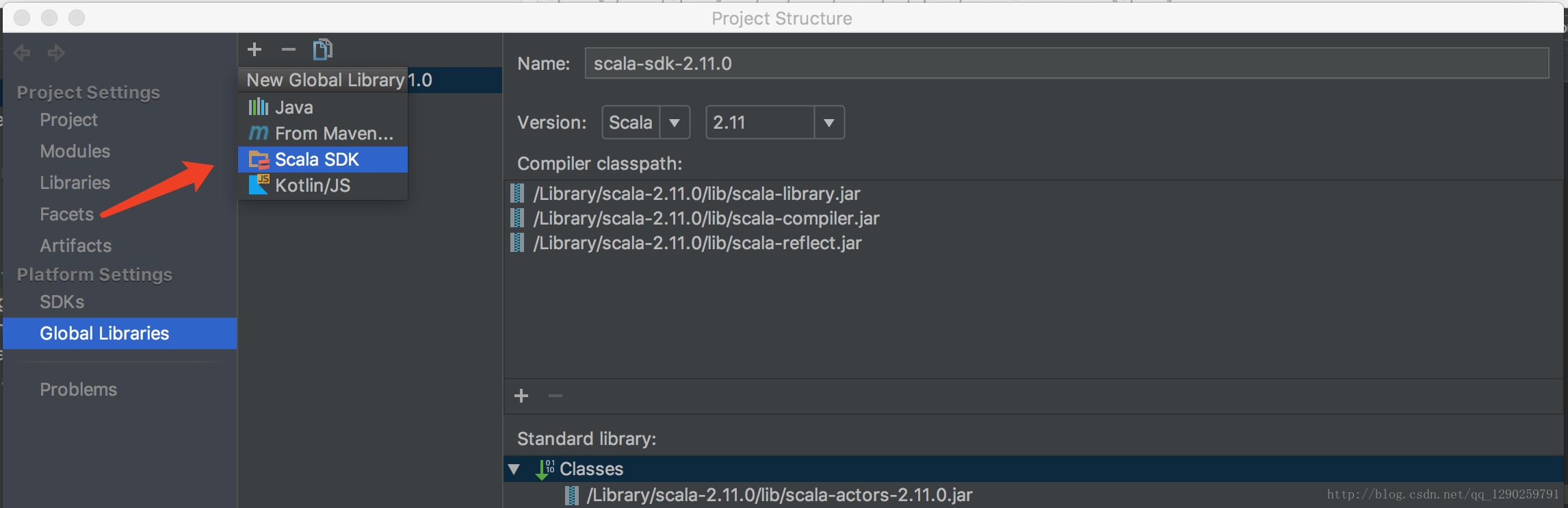
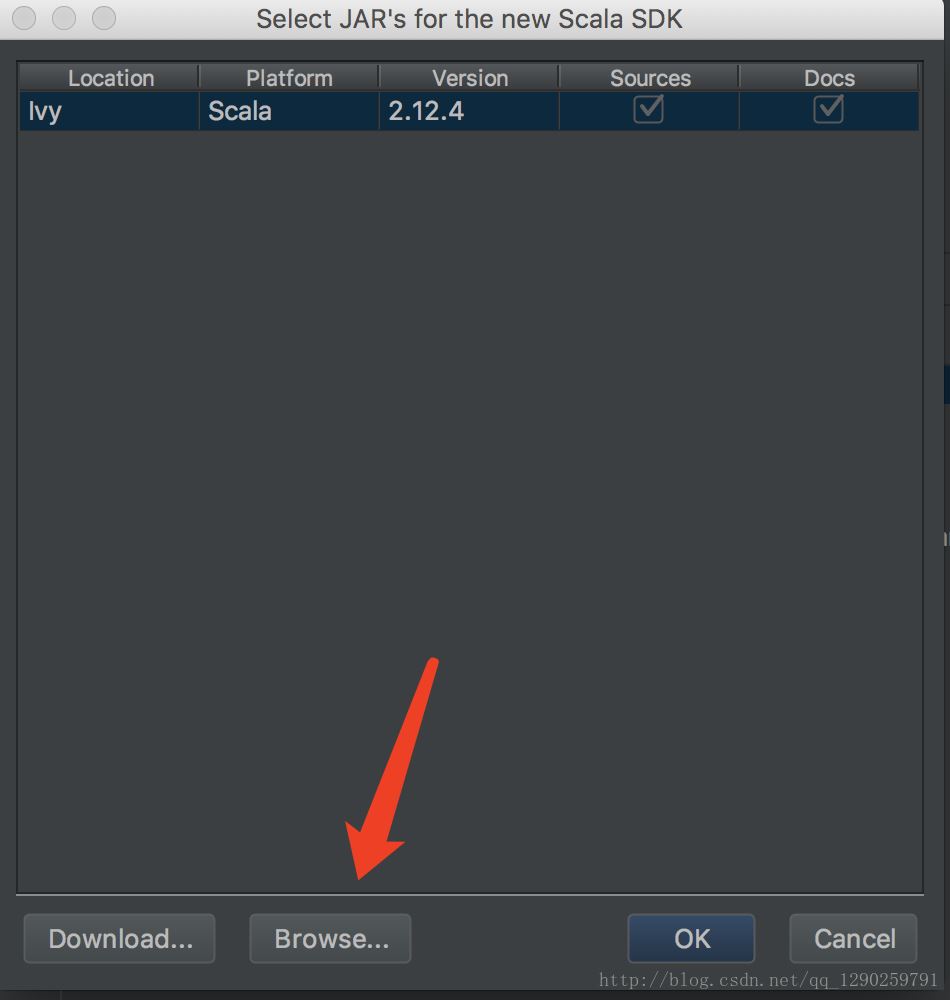
选择自己安装 Scala 的路径
第四步:编写 Scala 程序
将其他的代码删除,不然在编辑的时候会报错
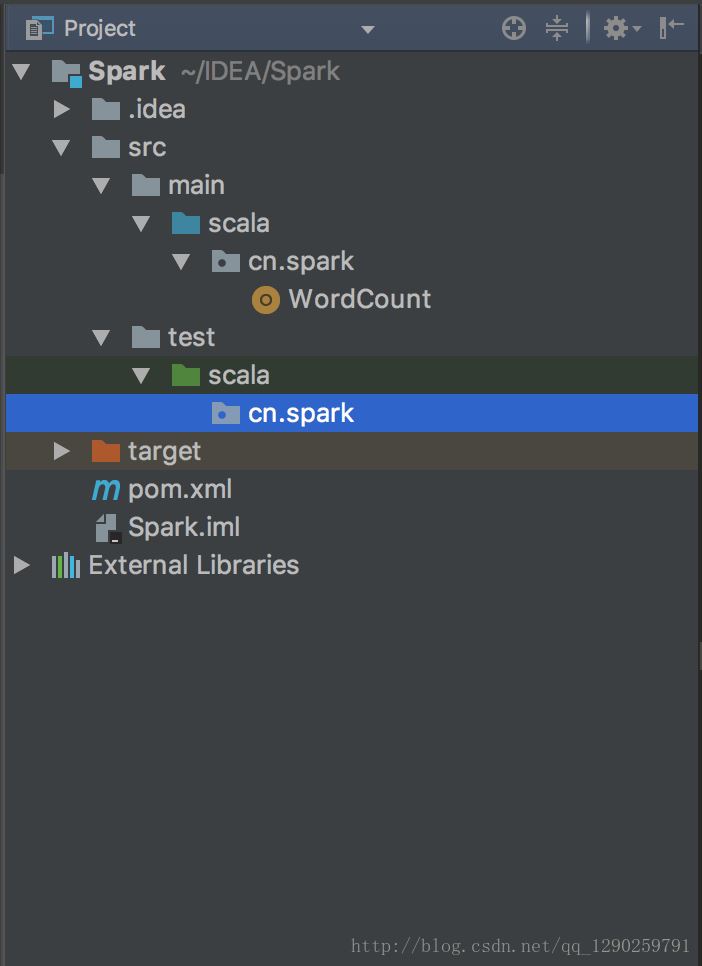
配置 pom.xml文件
在里面添加一个 Spark
<properties>
<scala.version>2.11.0</scala.version>
<spark.version>2.2.1</spark.version>
</properties>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
具体的 pom.xml 内容
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.spark</groupId>
<artifactId>Spark</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.11.0</scala.version>
<spark.version>2.2.1</spark.version>
</properties>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
编写 WordCount 文件
package cn.spark
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by hubo on 2018/1/13
*/
object WordCount {
def main(args: Array[String]) {
var masterUrl = "local"
var inputPath = "/Users/huwenbo/Desktop/a.txt"
var outputPath = "/Users/huwenbo/Desktop/out"
if (args.length == 1) {
masterUrl = args(0)
} else if (args.length == 3) {
masterUrl = args(0)
inputPath = args(1)
outputPath = args(2)
}
println(s"masterUrl:$masterUrl, inputPath: $inputPath, outputPath: $outputPath")
val sparkConf = new SparkConf().setMaster(masterUrl).setAppName("WordCount")
val sc = new SparkContext(sparkConf)
val rowRdd = sc.textFile(inputPath)
val resultRdd = rowRdd.flatMap(line => line.split("\\s+"))
.map(word => (word, 1)).reduceByKey(_ + _)
resultRdd.saveAsTextFile(outputPath)
}
}
var masterUrl = “local”
local代表自己本地运行,在 hadoop 上运行添加相应地址
在配置中遇到的错误,会写在另一篇文章里。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。