
从零开始学习SQL查询语句执行顺序
作者:alwayssmile21
SQL查询语句执行顺序如下:
(7) SELECT (8) DISTINCT <select_list> (1) FROM <left_table> (3) <join_type> JOIN <right_table> (2) ON <join_condition> (4) WHERE <where_condition> (5) GROUP BY <group_by_list> (6) HAVING <having_condition> (9) ORDER BY <order_by_condition> (10) LIMIT <limit_number>
前期准备工作
1、新建一个测试数据库
create database testData;
2、创建测试表,并插入数据如下:
用户表
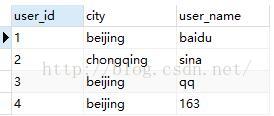
订单表

准备SQL逻辑查询测试语句
SELECT a.user_id,COUNT(b.order_id) as total_orders FROM user as a LEFT JOIN orders as b ON a.user_id = b.user_id WHERE a.city = 'beijing' GROUP BY a.user_id HAVING COUNT(b.order_id) < 2 ORDER BY total_orders desc
使用上述SQL查询语句来获得来自北京,并且订单数少于2的客户;
在这些SQL语句的执行过程中,都会产生一个虚拟表,用来保存SQL语句的执行结果
一、执行FROM语句
第一步,执行FROM语句。我们首先需要知道最开始从哪个表开始的,这就是FROM告诉我们的。现在有了<left_table>和<right_table>两个表,我们到底从哪个表开始,还是从两个表进行某种联系以后再开始呢?它们之间如何产生联系呢?——笛卡尔积
经过FROM语句对两个表执行笛卡尔积,会得到一个虚拟表,VT1(vitual table 1),内容如下:

总共有28(user的记录条数 * orders的记录条数)条记录。这就是VT1的结果,接下来的操作就在VT1的基础上进行
二、执行ON过滤
执行完笛卡尔积以后,接着就进行ON a.user_id = b.user_id条件过滤,根据ON中指定的条件,去掉那些不符合条件的数据,得到VT2如下:
select * from user as a inner JOIN orders as b ON a.user_id = b.user_id;

三、添加外部行
这一步只有在连接类型为OUTER JOIN时才发生,如LEFT OUTER JOIN、RIGHT OUTER JOIN和FULL OUTER JOIN。在大多数的时候,我们都是会省略掉OUTER关键字的,但OUTER表示的就是外部行的概念。
LEFT OUTER JOIN把左表记为保留表:即左表的数据会被全部查询出来,若右表中无对应数据,会用NULL来填充:

RIGHT OUTER JOIN把右表记为保留表:即右表的数据会被全部查询出来,若左表中无对应数据,则用NULL补充;

FULL OUTER JOIN把左右表都作为保留表,但在Mysql中不支持全连接,可以通过以下方式实现全连接:

由于我在准备的测试SQL查询逻辑语句中使用的是LEFT JOIN,得到的VT3表如下:

四、执行where条件过滤
对添加了外部行的数据进行where条件过滤,只有符合<where_condition>条件的记录会被筛选出来,执行WHERE a.city = 'beijing' 得到VT4如下:

但是在使用WHERE子句时,需要注意以下两点:
1、由于数据还没有分组,因此现在还不能在where过滤条件中使用where_condition=MIN(col)这类对分组统计的过滤;
2、由于还没有进行列的选取操作,因此在select中使用列的别名也是不被允许的,如:select city as c from table1 wherec='beijing' 是不允许的
五、执行group by分组语句
GROU BY子句主要是对使用WHERE子句得到的虚拟表进行分组操作,执行GROUP BY a.user_id得到VT5如下:

六、执行having
HAVING子句主要和GROUP BY子句配合使用,对分组得到VT5的数据进行条件过滤,执行 HAVING COUNT(b.order_id) < 2,得到VT6如下:

七、select列表
现在才会执行到SELECT子句,不要以为SELECT子句被写在第一行,就是第一个被执行的。
我们执行测试语句中的SELECT a.user_id,user_name,COUNT(b.order_id) as total_orders,从VT6中选择出我们需要的内容,得到VT7如下:

八、执行distinct去重复数据
如果在查询中指定了DISTINCT子句,则会创建一张内存临时表(如果内存放不下,就需要存放在硬盘了)。这张临时表的表结构和上一步产生的虚拟表是一样的,不同的是对进行DISTINCT操作的列增加了一个唯一索引,以此来除重复数据。测试SQL中没有DISTINCT字句,所以不会执行
九、执行order by字句
对虚拟表VT7中的内容按照指定的列进行排序,然后返回一个新的虚拟表,我们执行测试SQL语句中的ORDER BY total_orders DESC ,得到结果如下:
DESC倒序排序,ASC升序排序

十、执行limit字句
LIMIT子句从上一步得到的虚拟表中选出从指定位置开始的指定行数据,常用来做分页;
MySQL数据库的LIMIT支持如下形式的选择:limit n,m
表示从第n条记录开始选择m条记录。对于小数据,使用LIMIT子句没有任何问题,当数据量非常大的时候,使用LIMIT n, m是非常低效的。因为LIMIT的机制是每次都是从头开始扫描,如果需要从第60万行开始,读取3条数据,就需要先扫描定位到60万行,然后再进行读取,而扫描的过程是一个非常低效的过程。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。