
Python爬虫天气预报实例详解(小白入门)
作者:敲代码的猴
本文研究的主要是Python爬虫天气预报的相关内容,具体介绍如下。
这次要爬的站点是这个:http://www.weather.com.cn/forecast/
要求是把你所在城市过去一年的历史数据爬出来。
分析网站
首先来到目标数据的网页 http://www.weather.com.cn/weather40d/101280701.shtml
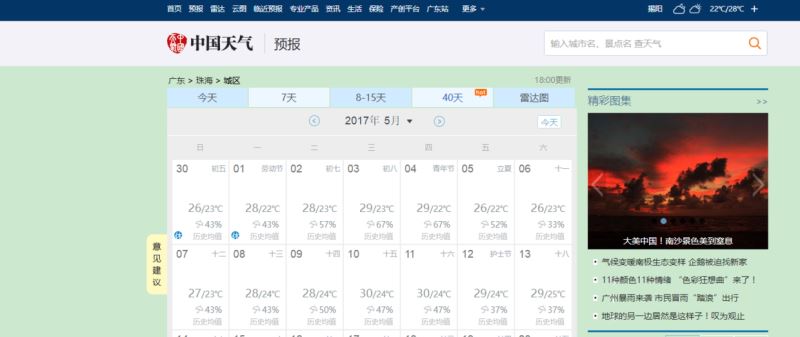
我们可以看到,我们需要的天气数据都是放在图表上的,在切换月份的时候,发现只有部分页面刷新了,就是天气数据的那块,而URL没有变化。
这是因为网页前端使用了JS异步加载的技术,更新时不用加载整个页面,从而提升了网页的加载速度。
对于这种非静态页面,我们在请求数据时,就不能简单的通过替换URL来请求不同的页面。
着眼点要放在Network,观察整个请求的过程,从中寻找突破口。
老规矩按下F12 > network,切换下页面,发现多了一些东西,这就是切换月份,浏览器发出的请求,可以很清楚的看到请求头和请求参数。
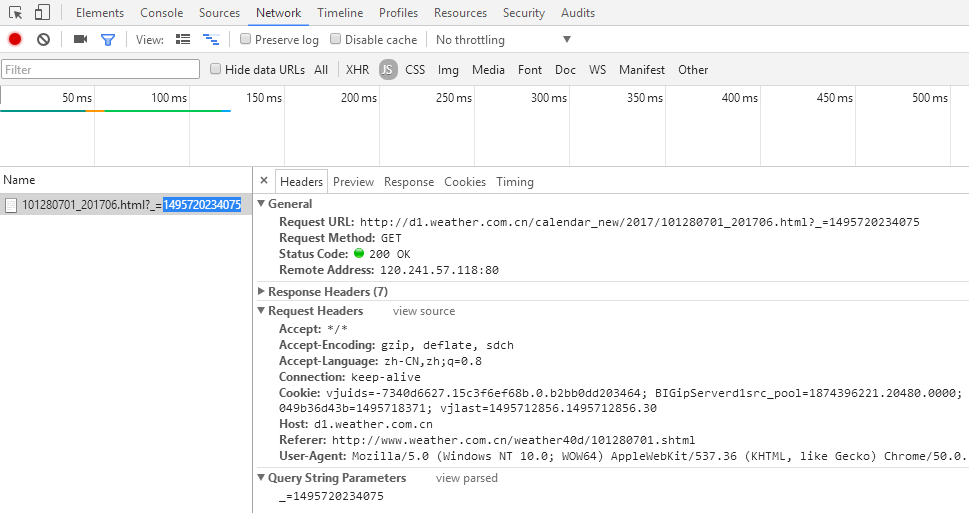
再来看看Response是怎样的吧

真是没想到,返回的居然是json格式的天气数据!直接做 json 反序化就能变成字典的形式,省掉了我们解析 html 的麻烦呀。既然找到了数据所在的地方,就可以开始尝试构建请求了。
构建请求
先直接copy上面的Request URL,试下请求。http://d1.weather.com.cn/calendar_new/2017/101280701_201706.html?_=1495720234075
然后发现报错了,先把请求头全部满上怼进去,发现可以正常的响应。
但是我们还要分析下到底哪个参数不对出了问题。经过尝试,发现请求头里的Referer的原因,去掉就会报错。
这是因为这是浏览器发出请求时,会通过Referer告诉服务器我是从哪个页面链接过来的,有些网站会对这个做验证,主要时为了防止别人盗链的问题。
这个中国天气网,就是验证了Referer里的域名是不是自己的,不是的话就会403禁止访问服务器。
接下来就要考虑怎么请求不同月份的数据。
通过观察URL,发现其实很简单,直接替换年月,就可以循环抓取,得到整年的数据。
那中间的101280701是什么意思呢,经过请求不同的城市对比URL,我发现这是表示地理位置的一个数据。
前3位表示国家中国,后6位依次表示,省份,城市和区县。修改这里,就能实现对不同城市进行查询了。
最后一个参数1495720234075,开始以为是随机数,后来有朋友提醒这是unix时间戳,实际上就算去掉这个,也能正常访问数据,没什么影响。
解析数据
拿到数据以后,就可以开始解析了。不过这里根本用不上xpath,直接用Json.load(),就能反序列化成json对象,从中取出字典,节省很多麻烦。需要注意的是,返回的40天的天气数据 fc40 字符串是这样
var fc40 = [{"blue":"","c1":"","c2":"","cla":"history","date":"20151227","des":"历史均值","fe":"","hgl":"17%","hmax":"17","hmin":"13","hol":"","jq":""
.....]}
前面的字符串需要去掉,才能反序列化,注意这里的json对象实际是个存储字典的list[]。开始想用正则,不过不熟没弄好。后来发现 python 字符串也能使用这样的语法 [a:b] 来取出位置a到位置b的字符串,所以就直接用[11 : ], 就能取出fc40 后面的字符串,也很方便。
保存数据
因为数据量比较大,就采用mongodb来做数据持久化。mongodb 我也是才学习,参考了别人的教程,才做好了环境配置,过程打算总结到另一篇,这里就打算不多说了。
因为原本的放了天气数据的字典里面有太多没用的数据,我只想提取出我想要的部分,就用了一个小技巧。
将想要的数据的key,保存成subkey这个字典,用 for in取出subkey中的key,再回到原本的dict中取出对应的值,最后将这些键值对,都存储在一个subdict字典里,就完成了提取出子字典的功能。说起来很麻烦,但是代码却很简单,这可能就是python的魅力吧。
subkey = {'date', 'hmax', 'hmin', 'hgl', 'fe', 'wk', 'time'}
subdict = {key: dict[key] for key in subkey}
然后我还做了个用中文替换的原来key的功能,只需要稍作修改,for in 取出来的是键值对,然后用中文的value,替换英文的key,就ok了。
subkey = {'date': '日期', 'hmax': '最高温度', 'hmin': '最低温度', 'hgl':
'降水概率', 'fe': '节日', 'wk': '星期'}
subdict = {value: dict[key] for key, value in subkey.items()}
最后的结果如下图,这是用pycharm上的mongodb可视化插件Mongo Plugin看到的,在pycharm>settings>plugins里面可以搜索安装。需要注意的是,默认只显示300条数据。想要看到更多,就在Row limit 上输入总数就行。

Python的代码非常短才30多行,就完成了爬虫的整个流程, 请求,解析,保存,一气呵成,可谓是爬虫界的豪杰。
# encoding=utf-8
import requests
import json
import pymongo
import time
def request(year, month):
url = "http://d1.weather.com.cn/calendar_new/" + year + "/101280701_" + year + month + ".html?_=1495685758174"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36",
"Referer": "http://www.weather.com.cn/weather40d/101280701.shtml",
}
return requests.get(url, headers=headers)
def parse(res):
json_str = res.content.decode(encoding='utf-8')[11:]
return json.loads(json_str)
def save(list):
subkey = {'date': '日期', 'hmax': '最高温度', 'hmin': '最低温度', 'hgl': '降水概率', 'fe': '节日', 'wk': '星期', 'time': '发布时间'}
for dict in list:
subdict = {value: dict[key] for key, value in subkey.items()} #提取原字典中部分键值对,并替换key为中文
forecast.insert_one(subdict) #插入mongodb数据库
if __name__ == '__main__':
year = "2016"
month = 1
client = pymongo.MongoClient('localhost', 27017) # 连接mongodb,端口27017
test = client['test'] # 创建数据库文件test
forecast = test['forecast'] # 创建表forecast
for i in range(month, 13):
month = str(i) if i > 9 else "0" + str(i) #小于10的月份要补0
save(parse(request(year, month)))
time.sleep(1)
总结
以上就是本文关于Python爬虫天气预报实例详解(小白入门)的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站其他相关专题,如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!