
Java 堆排序实例(大顶堆、小顶堆)
作者:Sun_Ru
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
堆排序的平均时间复杂度为Ο(nlogn) 。
算法步骤:
1. 创建一个堆H[0..n-1]
2. 把堆首(最大值)和堆尾互换
3. 把堆的尺寸缩小1,并调用shift_down(0),目的是把新的数组顶端数据调整到相应位置
4. 重复步骤2,直到堆的尺寸为1
堆:
堆实际上是一棵完全二叉树,其任何一非叶节点满足性质: Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]或者Key[i]>=Key[2i+1]&&key>=key[2i+2] 即任何一非叶节点的关键字不大于或者不小于其左右孩子节点的关键字。 堆分为大顶堆和小顶堆,满足Key[i]>=Key[2i+1]&&key>=key[2i+2]称为大顶堆,满足 Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]称为小顶堆。由上述性质可知大顶堆的堆顶的关键字肯定是所有关键字中最大的,小顶堆的堆顶的关键字是所有关键字中最小的。
堆排序思想:
利用大顶堆(小顶堆)堆顶记录的是最大关键字(最小关键字)这一特性,使得每次从无序中选择最大记录(最小记录)变得简单。 其基本思想为(大顶堆): 1)将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区; 2)将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2...n-1]<=R[n]; 3)由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。 操作过程如下: 1)初始化堆:将R[1..n]构造为堆; 2)将当前无序区的堆顶元素R[1]同该区间的最后一个记录交换,然后将新的无序区调整为新的堆。 因此对于堆排序,最重要的两个操作就是构造初始堆和调整堆,其实构造初始堆事实上也是调整堆的过程,只不过构造初始堆是对所有的非叶节点都进行调整。
一个图示实例
给定一个整形数组a[]={16,7,3,20,17,8},对其进行堆排序。 首先根据该数组元素构建一个完全二叉树,得到
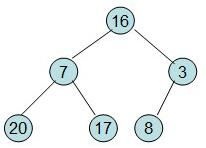
然后需要构造初始堆,则从最后一个非叶节点开始调整,调整过程如下:
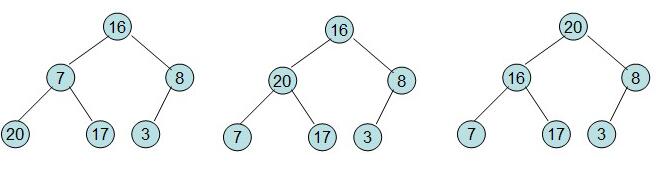
20和16交换后导致16不满足堆的性质,因此需重新调整
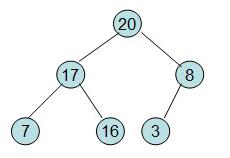
这样就得到了初始堆。
先进行一次调整时其成为大顶堆,
即每次调整都是从父节点、左孩子节点、右孩子节点三者中选择最大者跟父节点进行交换(交换之后可能造成被交换的孩子节点不满足堆的性质,因此每次交换之后要重新对被交换的孩子节点进行调整)。有了初始堆之后就可以进行排序了。
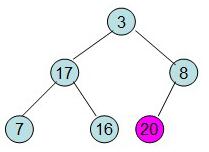
此时3位于堆顶不满堆的性质,则需调整继续调整

这样整个区间便已经有序了。从上述过程可知,堆排序其实也是一种选择排序,是一种树形选择排序。只不过直接选择排序中,为了从R[1...n]中选择最大记录,需比较n-1次,然后从R[1...n-2]中选择最大记录需比较n-2次。事实上这n-2次比较中有很多已经在前面的n-1次比较中已经做过,而树形选择排序恰好利用树形的特点保存了部分前面的比较结果,因此可以减少比较次数。对于n个关键字序列,最坏情况下每个节点需比较log2(n)次,因此其最坏情况下时间复杂度为nlogn。堆排序为不稳定排序,不适合记录较少的排序。 上面描述了这么多,简而言之,堆排序的基本做法是:首先,用原始数据构建成一个大(小)堆作为原始无序区,然后,每次取出堆顶元素,放入有序区。由于堆顶元素被取出来了,我们用堆中最后一个元素放入堆顶,如此,堆的性质就被破坏了。我们需要重新对堆进行调整,如此继续N次,那么无序区的N个元素都被放入有序区了,也就完成了排序过程。
(建堆是自底向上)
实际应用:
实际中我们进行堆排序是为了取得一定条件下的最大值或最小值,例如:需要在100个数中找到10个最大值,因此我们定义一个大小为10的堆,把100中的前十个数据建立成小顶堆(堆顶最小),然后从100个数据中的第11个数据开始与堆顶比较,若堆顶小于当前数据,则把堆顶弹出,把当前数据压入堆顶,然后把数据从堆顶下移到一定位置即可,
代码:
public class Test0 {
static int[] arr;//堆数组,有效数组
public Test0(int m){
arr= new int[m];
}
static int m=0;
static int size=0;//用来标记堆中有效的数据
public void addToSmall(int v){
//int[] a = {16,4,5,9,1,10,11,12,13,14,15,2,3,6,7,8,111,222,333,555,66,67,54};
//堆的大小为10
//arr = new int[10];
if(size<arr.length){
arr[size]=v;
add_sort(size);
//add_sort1(size);
size++;
}else{
arr[0]=v;
add_sort1(0);
}
}
public void printSmall(){
for(int i=0;i<size;i++){
System.out.println(arr[i]);
}
}
public void del(){
size--;
arr[0]=arr[9];
add_sort1(0);
}
public void Small(int index){
if(m<arr.length){
add_sort(index);
m++;
}else{
add_sort1(index);
m++;
}
}
public void add_sort( int index){//小顶堆,建堆
/*
* 父节点坐标:index
* 左孩子节点:index*2
* 右孩子节点:index*2+1
*若数组中最后一个为奇数则为 左孩子
*若数组中最后一个为偶数则为 右孩子
若孩子节点比父节点的值大,则进行值交换,若右孩子比左孩子大则进行值交换
*
*/
int par;
if(index!=0){
if(index%2==0){
par=(index-1)/2;
if(arr[index]<arr[par]){
swap(arr,index,par);
add_sort(par);
}
if(arr[index]>arr[par*2]){
swap(arr,index,par*2);
if(arr[index]<arr[par]){
swap(arr,index,par);
}
add_sort(par);
}
}else{
par=index/2;
if(arr[index]<arr[par]){
swap(arr,index,par);
add_sort(par);
}
if(arr[index]<arr[par*2+1]){
swap(arr, index, par*2+1);
if(arr[index]<arr[par]){
swap(arr,index,par);
}
add_sort(par);
}
}
}
}
public void add_sort1(int index){//调整小顶堆
/*调整自顶向下
* 只要孩子节点比父节点的值大,就进行值交换,
*/
int left=index*2;
int right=index*2+1;
int max=0;
if(left<10&&arr[left]<arr[index]){
max=left;
}else{
max=index;
}
if(right<10&&arr[right]<arr[max]){
max=right;
}
if(max!=index){
swap(arr,max,index);
add_sort1(max);
}
}
}
测试代码:
package 大顶堆;
import java.util.Scanner;
public class Main_test0 {
public static void main(String args[]){
Scanner scan = new Scanner(System.in);
System.out.println("(小顶堆)请输入堆大小:");
int m=scan.nextInt();
Test0 test = new Test0(m);
int[] a = {16,4,5,9,1,10,11,12,13,14,15,2,3,6,7,8};
for(int i=0;i<a.length;i++){
test.addToSmall(a[i]);
}
test.printSmall();
test.del();
test.printSmall();
scan.close();
}
}
以上这篇Java 堆排序实例(大顶堆、小顶堆)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。