
Java爬虫实现爬取京东上的手机搜索页面 HttpCliient+Jsoup
作者:杂兵2号
1、需求及配置
需求:爬取京东手机搜索页面的信息,记录各手机的名称,价格,评论数等,形成一个可用于实际分析的数据表格。

使用Maven项目,log4j记录日志,日志仅导出到控制台。
Maven依赖如下(pom.xml)
<dependencies> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.3</version> </dependency> <dependency> <!-- jsoup HTML parser library @ https://jsoup.org/ --> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.11.2</version> </dependency> <!-- https://mvnrepository.com/artifact/log4j/log4j --> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> </dependencies>
log4j配置(log4j.properties),将INFO及以上等级信息输出到控制台,不单独设置输出文档。
log4j.rootLogger=INFO, Console #Console log4j.appender.Console=org.apache.log4j.ConsoleAppender log4j.appender.Console.layout=org.apache.log4j.PatternLayout log4j.appender.Console.layout.ConversionPattern=%d [%t] %-5p [%c] - %m%n
2、需求分析与代码
2.1需求分析
第一步,建立客户端与服务端的连接,并通过URL获得网页上的HTML内容。
第二步,解析HTML内容,获取需要的元素。
第三步,将HTML内容输出到本地的文本文档中,可直接通过其他数据分析软件进行分析。
根据以上分析,建立4个类,GetHTML(用于获取网站HTML), ParseHTML(用于解析HTML), WriteTo(用于输出文档), Maincontrol(主控).下面分别对四个类进行说明。为使代码尽量简洁,所有的异常均从方法上直接抛出,不catch。
2.2代码
2.2.1GetHTML类
该类包含两个方法:getH(String url), urlControl(String baseurl, int page),分别用于获取网页HTML及控制URL。由于此次爬取的网页内容只是京东上某一类商品的搜索结果,所以不需要对页面上所有的URL进行遍历,只需要观察翻页时URL的变化,推出规律即可。只向外暴露urlControl方法,类中设置一个private的log属性:private static Logger log = Logger.getLogger(getHTML.class); 用于记录日志。
getH(String url),对单个URL的HTML内容进行获取。
urlControl(String baseurl, int page),设置循环,访问多个页面的数据。通过审查元素可以看到京东上搜索页page的变化实际是奇数顺序的变化。
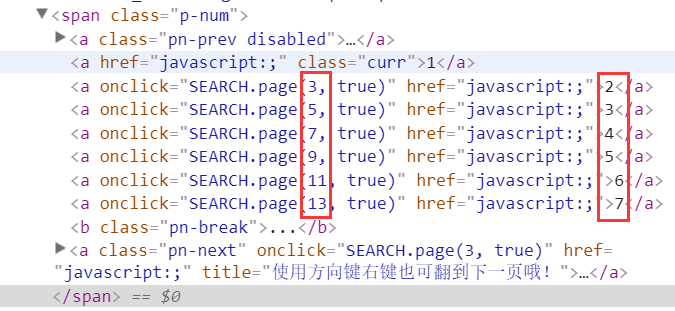
再看一下点击后网址的变化,可以发现实际变化的是page属性的值。通过拼接的方式就可以很的容易的获得下一个网页的地址。
https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=3&s=47&click=0
https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=5&s=111&click=0
https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=7&s=162&click=0
整体代码:
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.apache.log4j.Logger;
public class getHTML {
//建立日志
private static Logger log = Logger.getLogger(getHTML.class);
private static String getH(String url) throws ClientProtocolException, IOException {
//控制台输出日志,这样每条访问的URL都可以在控制台上看到访问情况
log.info("正在解析" + url);
/*
* 以下内容为HttpClient建立连接的一般用法
* 使用HttpClient建立客户端
* 使用get方法访问指定URL
* 获得应答
* */
CloseableHttpClient client = HttpClients.createDefault();
HttpGet get = new HttpGet(url);
CloseableHttpResponse response = client.execute(get);
/*
* 以下内容为将HTML内容转化为String
* 获得应答体
* 将应答体转为String格式,此处使用了EntityUtils中的toString方法,编码格式设置为"utf-8"
* 完成后关闭客户端与应答
* */
HttpEntity entity = response.getEntity();
String content;
if (entity != null) {
content = EntityUtils.toString(entity, "utf-8");
client.close();
response.close();
return content;
} else
return null;
}
public static void urlControl(String baseurl, int page) throws ClientProtocolException, IOException {
//设置当前页count
int count = 1;
//如果当前页小于想要爬取的页数则执行
while (count < page) {
//实际访问的URL为不变的URL值拼接上URL变化的值
String u = baseurl + (2 * count - 1) + "&click=0";
//此处调用ParseHTML类中的方法对URL中的HTML页面进行处理,后面详细介绍该类
String content = ParseHTML.parse(getH(u)).toString();
//此处调用WriteTo类中的方法对解析出来的内容写入到本地,后面详细介绍该类
WriteTo.writeto(content);
count++;
}
}
}
2.2.2ParseHTML类
该步骤需要通过审查元素对需要爬取内容的标签进行确定,再通过Jsoup中的CSS选择器进行获取。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class ParseHTML {
public static StringBuilder parse(String content)
{
//使用Jsoup中的parse方法对已经转换为String的HTML内容进行分析,返回值为Document类
Document doc = Jsoup.parse(content);
//使用选择器select对需要找的元素进行抓取,例如第一个select中选择的是ul标签中class属性等于gl-warp clearfix的内容
Elements ele = doc.select("ul[class = gl-warp clearfix]").select("li[class=gl-item]");
//设置一个容器,用于装各个属性
StringBuilder sb = new StringBuilder();
//通过上一个选择器可以获得整个页面中所有符合要求的元素,也即各款手机,下面则需要对每款手机进行遍历,获取其属性
for (Element e : ele) {
//此处对各个属性的获取参考了网上一篇爬取京东上内容的文章,应该有其他不同的写法
String id = e.attr("data-pid");
String mingzi = e.select("div[class = p-name p-name-type-2]").select("a").select("em").text();
String jiage = e.select("div[class=p-price]").select("strong").select("i").text();
String pinglun = e.select("div[class=p-commit]").select("strong").select("a").text();
//向容器中添加属性
sb.append(id+"\t");
sb.append(mingzi+"\t");
sb.append(jiage+"\t");
sb.append(pinglun+"\t");
sb.append("\r\n");
}
return sb;
}
}
2.2.3WriteTo类
此类中的方法将解析完成的内容写入到一个本地文件中。只是简单的IO。
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class WriteTo {
// 设置文件存放的位置
private static File f = new File("C:\\jingdong.txt");
public static void writeto(String content) throws IOException {
//使用续写的方式,以免覆盖前面写入的内容
BufferedWriter bw = new BufferedWriter(new FileWriter(f, true));
bw.append(content);
bw.flush();
bw.close();
}
}
2.2.4MainControl类
主控程序,写入基地址与想要获取的页面数。调用getHTML类中的urlControl方法对页面进行抓取。
import java.io.IOException;
import org.apache.http.client.ClientProtocolException;
public class MainControl {
public static void main(String[] args) throws ClientProtocolException, IOException {
// TODO Auto-generated method stub
String baseurl = "https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc="
+ "utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=";
int page = 5;//设置爬取页数
getHTML.urlControl(baseurl, page);
}
}
3、爬取结果
爬取20页。
3.1控制台输出
3.2文档输出
可以直接使用Excel打开,分隔符为制表符。列分别为商品编号,名称,价格与评论数。

4、小结
此次爬取使用了HttpClient与Jsoup,可以看到对于简单的需求,这些工具还是非常高效的。实际上也可以把所有类写到一个类当中,写多个类的方式思路比较清晰。
以上这篇Java爬虫实现爬取京东上的手机搜索页面 HttpCliient+Jsoup就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。