
Node.js+jade抓取博客所有文章生成静态html文件的实例
作者:ghostwu
这篇文章,我们就把上文中采集到的所有文章列表的信息整理一下,开始采集文章并且生成静态html文件了.先看下我的采集效果,我的博客目前77篇文章,1分钟不到就全部采集生成完毕了,这里我截了部分的图片,文件名用文章的id生成的,生成的文章,我写了一个简单的静态模板,所有的文章都是根据这个模板生成的.
项目结构:

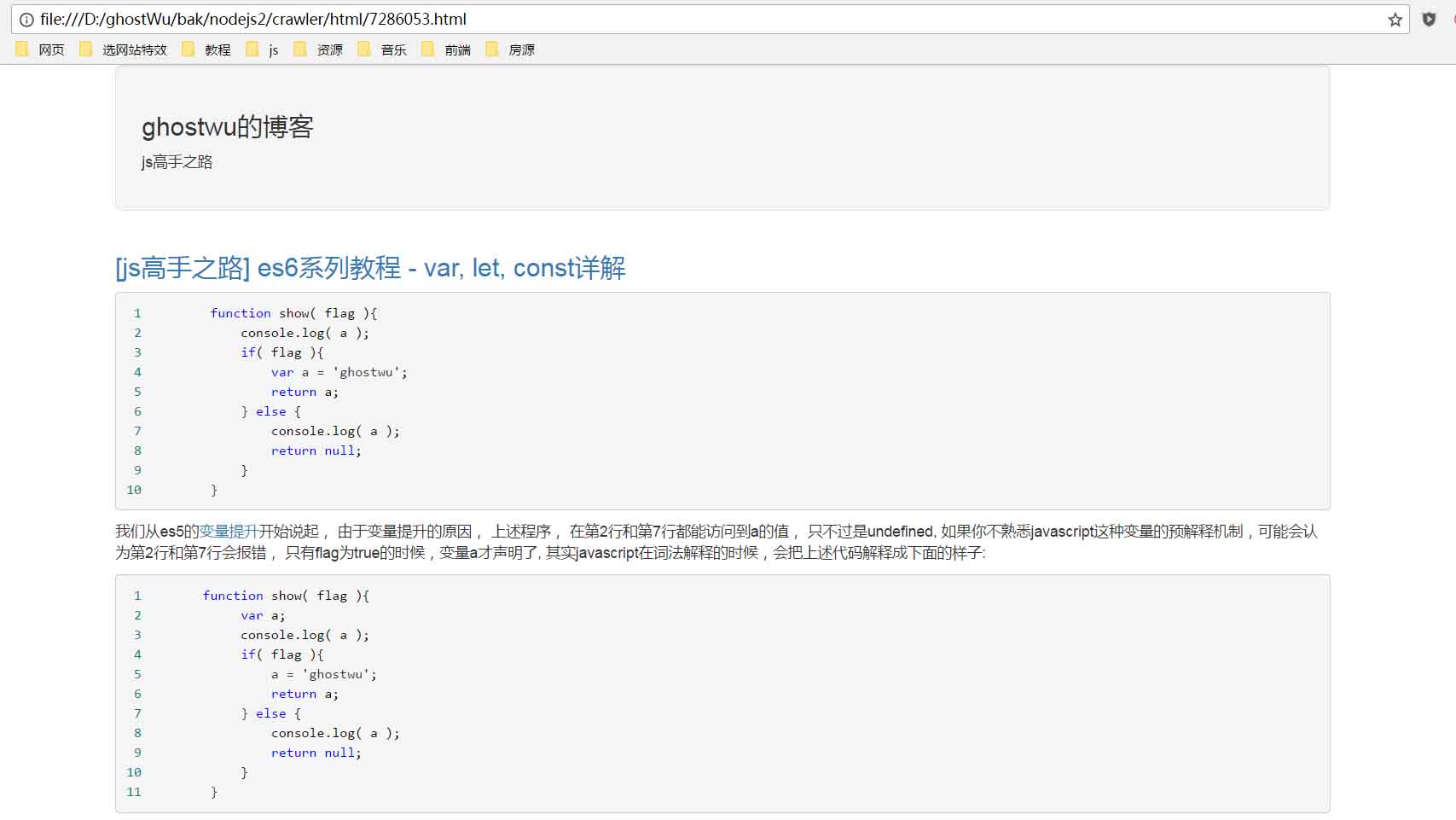
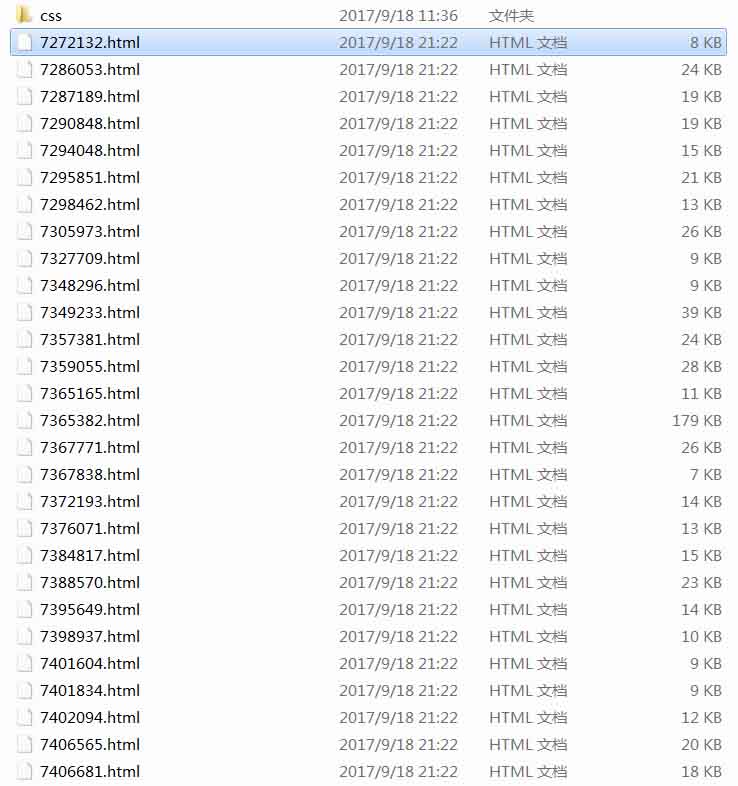
好了,接下来,我们就来讲解下,这篇文章主要实现的功能:
1,抓取文章,主要抓取文章的标题,内容,超链接,文章id(用于生成静态html文件)
2,根据jade模板生成html文件
一、抓取文章如何实现?
非常简单,跟上文抓取文章列表的实现差不多
function crawlerArc( url ){
var html = '';
var str = '';
var arcDetail = {};
http.get(url, function (res) {
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
arcDetail = filterArticle( html );
str = jade.renderFile('./views/layout.jade', arcDetail );
fs.writeFile( './html/' + arcDetail['id'] + '.html', str, function( err ){
if( err ) {
console.log( err );
}
console.log( 'success:' + url );
if ( aUrl.length ) crawlerArc( aUrl.shift() );
} );
});
});
}
参数url就是文章的地址,把文章的内容抓取完毕之后,调用filterArticle( html ) 过滤出需要的文章信息(id, 标题,超链接,内容),然后用jade的renderFile这个api,实现模板内容的替换,
模板内容替换完之后,肯定就需要生成html文件了, 所以用writeFile写入文件,写入文件时候,用id作为html文件名称。这就是生成一篇静态html文件的实现,
接下来就是循环生成静态html文件了, 就是下面这行:
if ( aUrl.length ) crawlerArc( aUrl.shift() );
aUrl保存的是我的博客所有文章的url, 每次采集完一篇文章之后,就把当前文章的url删除,让下一篇文章的url出来,继续采集
完整的实现代码server.js:
var fs = require( 'fs' );
var http = require( 'http' );
var cheerio = require( 'cheerio' );
var jade = require( 'jade' );
var aList = [];
var aUrl = [];
function filterArticle(html) {
var $ = cheerio.load( html );
var arcDetail = {};
var title = $( "#cb_post_title_url" ).text();
var href = $( "#cb_post_title_url" ).attr( "href" );
var re = /\/(\d+)\.html/;
var id = href.match( re )[1];
var body = $( "#cnblogs_post_body" ).html();
return {
id : id,
title : title,
href : href,
body : body
};
}
function crawlerArc( url ){
var html = '';
var str = '';
var arcDetail = {};
http.get(url, function (res) {
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
arcDetail = filterArticle( html );
str = jade.renderFile('./views/layout.jade', arcDetail );
fs.writeFile( './html/' + arcDetail['id'] + '.html', str, function( err ){
if( err ) {
console.log( err );
}
console.log( 'success:' + url );
if ( aUrl.length ) crawlerArc( aUrl.shift() );
} );
});
});
}
function filterHtml(html) {
var $ = cheerio.load(html);
var arcList = [];
var aPost = $("#content").find(".post-list-item");
aPost.each(function () {
var ele = $(this);
var title = ele.find("h2 a").text();
var url = ele.find("h2 a").attr("href");
ele.find(".c_b_p_desc a").remove();
var entry = ele.find(".c_b_p_desc").text();
ele.find("small a").remove();
var listTime = ele.find("small").text();
var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
listTime = listTime.match(re)[0];
arcList.push({
title: title,
url: url,
entry: entry,
listTime: listTime
});
});
return arcList;
}
function nextPage( html ){
var $ = cheerio.load(html);
var nextUrl = $("#pager a:last-child").attr('href');
if ( !nextUrl ) return getArcUrl( aList );
var curPage = $("#pager .current").text();
if( !curPage ) curPage = 1;
var nextPage = nextUrl.substring( nextUrl.indexOf( '=' ) + 1 );
if ( curPage < nextPage ) crawler( nextUrl );
}
function crawler(url) {
http.get(url, function (res) {
var html = '';
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
aList.push( filterHtml(html) );
nextPage( html );
});
});
}
function getArcUrl( arcList ){
for( var key in arcList ){
for( var k in arcList[key] ){
aUrl.push( arcList[key][k]['url'] );
}
}
crawlerArc( aUrl.shift() );
}
var url = 'http://www.cnblogs.com/ghostwu/';
crawler( url );
layout.jade文件:
doctype html
html
head
meta(charset='utf-8')
title jade+node.js express
link(rel="stylesheet", href='./css/bower_components/bootstrap/dist/css/bootstrap.min.css')
body
block header
div.container
div.well.well-lg
h3 ghostwu的博客
p js高手之路
block container
div.container
h3
a(href="#{href}" rel="external nofollow" ) !{title}
p !{body}
block footer
div.container
footer 版权所有 - by ghostwu
后续的打算:
1,采用mongodb入库
2,支持断点采集
3,采集图片
4,采集小说
等等....
以上这篇Node.js+jade抓取博客所有文章生成静态html文件的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。