
java 中模式匹配算法-KMP算法实例详解
投稿:lqh
java 中模式匹配算法-KMP算法实例详解
朴素模式匹配算法的最大问题就是太低效了。于是三位前辈发表了一种KMP算法,其中三个字母分别是这三个人名的首字母大写。
简单的说,KMP算法的对于主串的当前位置不回溯。也就是说,如果主串某次比较时,当前下标为i,i之前的字符和子串对应的字符匹配,那么不要再像朴素算法那样将主串的下标回溯,比如主串为“abcababcabcabcabcabc”,子串为“abcabx”.第一次匹配的时候,主串1,2,3,4,5字符都和子串相应的匹配,第6为‘c'与子串中的‘x'不匹配,说明此时i=6,下次匹配的时候,就不用再像朴素那样,将i置为2,再循环置为3,4,5去和子串匹配了。而是直接从i=6(以i=6为开头)开始和子串去进行匹配。
那么子串的下标的变化呢,是不是每次要从第一位开始去和主串匹配,实际上也不需要。还是上面的例子,第一次匹配后,子串的当前位置(下标)为j=6,因为前两位a,b和主串的4,5位的a,b已经比较完成,是匹配的,所以这两位也无需比较,也就是从j=3开始和主串匹配。现在的问题是,如何找到子串的下标j的变化。
我们把子串各个位置的j值得变化定义为1个数组next,那么next的长度就是T串的长度。于是可以得到下面的函数定义:

上图引用自《大话数据结构》,关于更多的KMP算法的说明,尤其是next[j]的推导,读者可以参考该书,讲解的非常的详细。下面给出该算法的java实现。
在《大话数据结构》,保存串的数组的首位,也就是0下标位置保存的是字符串的长度。但是上面的next[j]却可取值为0,这点我没有弄明白,如有哪位牛人能帮忙解释,万分感谢。下面编写的代码略有不同,在0下标位置不再是保存字符串的长度,而是保存字符串的首字符,也就是是与字符串对应的。所以next[j]的计算函数也不太一样,如下:
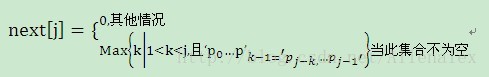
实现的代码:
public class Pattern_KMP {
public static void main(String args[])
{
int times;
String source="abcabaabcabcabxxzhabaabcabcabxad";
String subStr="abcabx";
times=pattren_KMP(source, subStr);
System.out.println("匹配次数:"+times);
}
static int pattren_KMP(String source,String subStr)
{
int len1,len2;
len1=source.length();
len2=subStr.length();
int i,j;
i=j=0;
int times=0;
while(i<len1)
{
if(source.charAt(i)==subStr.charAt(j))
{
i++;
j++;
}else
{
if(j==0)/*这一步很重要,如果没有会进入死循环,也就是,如果主串某位与子串*/
i++;/*第一位不等的话,必须往后移位。*/
j=next(subStr,j);
}
if(j==len2)
{
times++;
j=0;
}
}
return times;
}
static int next(String subStr,int j)
{
if(j==0)
return 0;
else {
int next=0;
int k=1;
int m1;
int m2;
int i,n;
/*这一循环对应实现上面函数的第二项*/
while(k<j)
{
String sub1="",sub2="";
for(m1=0,m2=j-k;m1<k&&m2<j;m1++,m2++)
{
sub1+=subStr.charAt(m1);
sub2+=subStr.charAt(m2);
}
for(i=0,n=0;i<sub1.length()&&n<sub2.length();i++,n++)
{
if(sub1.charAt(i)!=sub2.charAt(n))
break;
}
if(i==sub1.length()&&n==sub2.length())
next=k;
k++;
}
return next;
}
}
}
下面附上《大话数据结构》中的KMP算法(c代码)供对照参考(不是完整可执行程序)
/* 通过计算返回子串T的next数组。 */
void get_next(String T, int *next)
{
int i,j;
i=1;
j=0;
next[1]=0;
while (i<T[0]) /* 此处T[0]表示串T的长度 */
{
if(j==0 || T[i]== T[j]) /* T[i]表示后缀的单个字符,T[j]表示前缀的单个字符 */
{
++i;
++j;
next[i] = j;
}
else
j= next[j]; /* 若字符不相同,则j值回溯 */
}
}
/* 返回子串T在主串S中第pos个字符之后的位置。若不存在,则函数返回值为0。 */
/* T非空,1≤pos≤StrLength(S)。 */
int Index_KMP(String S, String T, int pos)
{
int i = pos; /* i用于主串S中当前位置下标值,若pos不为1,则从pos位置开始匹配 */
int j = 1; /* j用于子串T中当前位置下标值 */
int next[255]; /* 定义一next数组 */
get_next(T, next); /* 对串T作分析,得到next数组 */
while (i <= S[0] && j <= T[0]) /* 若i小于S的长度并且j小于T的长度时,循环继续 */
{
if (j==0 || S[i] == T[j]) /* 两字母相等则继续,与朴素算法增加了j=0判断 */
{
++i;
++j;
}
else /* 指针后退重新开始匹配 */
j = next[j];/* j退回合适的位置,i值不变 */
}
if (j > T[0])
return i-T[0];
else
return 0;
}
感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!