
基于python爬虫数据处理(详解)
投稿:jingxian
一、首先理解下面几个函数
设置变量 length()函数 char_length() replace() 函数 max() 函数
1.1、设置变量 set @变量名=值
set @address='中国-山东省-聊城市-莘县'; select @address
1.2 、length()函数 char_length()函数区别
select length('a')
,char_length('a')
,length('中')
,char_length('中')
1.3、 replace() 函数 和length()函数组合
set @address='中国-山东省-聊城市-莘县'; select @address ,replace(@address,'-','') as address_1 ,length(@address) as len_add1 ,length(replace(@address,'-','')) as len_add2 ,length(@address)-length(replace(@address,'-','')) as _count
etl清洗字段时候有明显分割符的如何确定新的数据表增加几个分割出的字段
计算出com_industry中最多有几个 - 符 以便确定增加几个字段 最大值+1 为可以拆分成的字段数 此表为3 因此可以拆分出4个行业字段 也就是4个行业等级
select max(length(com_industry)-length(replace(com_industry,'-',''))) as _max_count from etl1_socom_data
1.4、设置变量 substring_index()字符串截取函数用法
set @address='中国-山东省-聊城市-莘县'; select substring_index(@address,'-',1) as china, substring_index(substring_index(@address,'-',2),'-',-1) as province, substring_index(substring_index(@address,'-',3),'-',-1) as city, substring_index(@address,'-',-1) as district
1.5、条件判断函数 case when
case when then when then else 值 end as 字段名 select case when 89>101 then '大于' else '小于' end as betl1_socom_data
二、kettle转换etl1清洗
首先建表 步骤在视频里
字段索引 没有提 索引算法建议用BTREE算法增强查询效率
2.1.kettle文件名:trans_etl1_socom_data
2.2.包括控件:表输入>>>表输出
2.3.数据流方向:s_socom_data>>>>etl1_socom_data

kettle转换1截图
2.4、表输入2.4、SQL脚本 初步清洗com_district和com_industry字段
select a.*, case when com_district like '%业' or com_district like '%织' or com_district like '%育' then null else com_district end as com_district1 ,case when com_district like '%业' or com_district like '%织' or com_district like '%育' then concat(com_district,'-',com_industry) else com_industry end as com_industry_total ,replace(com_addr,'地 址:','') as com_addr1 ,replace(com_phone,'电 话:','') as com_phone1 ,replace(com_fax,'传 真:','') as com_fax1 ,replace(com_mobile,'手机:','') as com_mobile1 ,replace(com_url,'网址:','') as com_url1 ,replace(com_email,'邮箱:','') as com_email1 ,replace(com_contactor,'联系人:','') as com_contactor1 ,replace(com_emploies_nums,'公司人数:','') as com_emploies_nums1 ,replace(com_reg_capital,'注册资金:万','') as com_reg_capital1 ,replace(com_type,'经济类型:','') as com_type1 ,replace(com_product,'公司产品:','') as com_product1 ,replace(com_desc,'公司简介:','') as com_desc1 from s_socom_data as a
2.5、表输出
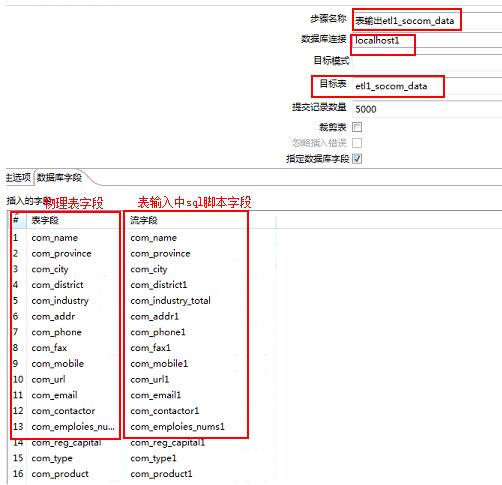
表输出设置注意事项
注意事项:
① 涉及爬虫增量操作 不要勾选裁剪表选项
②数据连接问题 选择表输出中表所在的数据库
③字段映射问题 确保数据流中的字段和物理表的字段数量一致 对应一致
三、kettle转换etl2清洗
首先建表增加了4个字段 演示步骤在视频里
字段索引 没有提 索引算法建议用BTREE算法增强查询效率
主要针对etl1 生成的新的com_industry进行字段拆分 清洗
3.1.kettle文件名:trans_etl2_socom_data
3.2.包括控件:表输入>>>表输出
3.3.数据流方向:etl1_socom_data>>>>etl2_socom_data
注意事项:
① 涉及爬虫增量操作 不要勾选裁剪表选项
②数据连接问题 选择表输出中表所在的数据库
③字段映射问题 确保数据流中的字段和物理表的字段数量一致 对应一致

kettle转换2截图
3.4、SQL脚本 对com_industry进行拆分 完成所有字段清洗 注册资金字段时间关系没有进行细致拆解 调整代码即可
select a.*, case #行业为''的值 置为空 when length(com_industry)=0 then null #其他的取第一个-分隔符之前 else substring_index(com_industry,'-',1) end as com_industry1, case when length(com_industry)-length(replace(com_industry,'-',''))=0 then null #'交通运输、仓储和邮政业-' 这种值 行业2 也置为null when length(com_industry)-length(replace(com_industry,'-',''))=1 and length(substring_index(com_industry,'-',-1))=0 then null when length(com_industry)-length(replace(com_industry,'-',''))=1 then substring_index(com_industry,'-',-1) else substring_index(substring_index(com_industry,'-',2),'-',-1) end as com_industry2, case when length(com_industry)-length(replace(com_industry,'-',''))<=1 then null when length(com_industry)-length(replace(com_industry,'-',''))=2 then substring_index(com_industry,'-',-1) else substring_index(substring_index(com_industry,'-',3),'-',-1) end as com_industry3, case when length(com_industry)-length(replace(com_industry,'-',''))<=2 then null else substring_index(com_industry,'-',-1) end as com_industry4 from etl1_socom_data as a
四、清洗效果质量检查
4.1爬虫数据源数据和网站数据是否相符
如果本身工作是爬虫和数据处理在一起处理,抓取的时候其实已经判断,此步骤可以省略,如果对接上游爬虫同事,这一步首先判断,不然清洗也是无用功,一般都要求爬虫同事存储请求的url便于后面数据处理查看数据质量
4.2计算爬虫数据源和各etl清洗数据表数据量
注:SQL脚本中没有经过聚合过滤 3个表数据量应相等
4.2.1、sql查询 下面表我是在同一数据库中 如果不在同一数据库 from 后面应加上表所在的数据库名称
不推荐数据量大的时候使用
select count(1) from s_socom_data union all select count(1) from etl1_socom_data union all select count(1) from etl2_socom_data
4.2.2 根据 kettle转换执行完毕以后 表输出总量对比
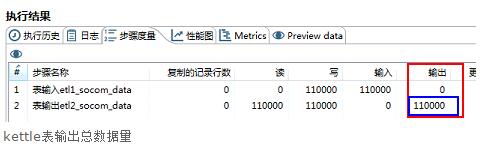
kettle表输出总数据量
4.3查看etl清洗质量
确保前两个步骤已经无误,数据处理负责的etl清洗工作自查开始 针对数据源清洗的字段 写脚本检查 socom网站主要是对地区 和行业进行了清洗 对其他字段做了替换多余字段处理 ,因此采取脚本检查,
找到page_url和网站数据进行核查
where里面这样写便于查看某个字段的清洗情况
select * from etl2_socom_data where com_district is null and length(com_industry)-length(replace(com_industry,'-',''))=3
http://www.socom.cn/company/7320798.html此页面数据和etl2_socom_data表最终清洗数据对比

网站页面数据

etl2_socom_data表数据
清洗工作完成。
以上这篇基于python爬虫数据处理(详解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。