
对dbunit进行mybatis DAO层Excel单元测试(必看篇)
投稿:jingxian
DAO层测试难点
可重复性,每次运行单元测试,得到的数据是重复的
独立性,测试数据与实际数据相互独立
数据库中脏数据预处理
不能给数据库中数据带来变化
DAO层测试方法
使用内存数据库,如H2。优点:无需清空无关数据;缺点:单元测试中需要进行数据库初始化过程,如果初始化过程复杂,单元测试工作量增大
使用dbunit。优点:数据库初始化简单,大大减轻单元测试工作量;缺点:目前官方提供jar包只支持xml格式文件,需要自己开发Excel格式文件
基于dbunit进行DAO单元测试
应用环境:Spring、Mybatis、MySql、Excel
配置文件
1. pom.xml
引入jar包,unitils整合了dbunit,database,spring,io等模块
<dependency>
<groupId>org.unitils</groupId>
<artifactId>unitils-core</artifactId>
<version>3.4.2</version>
</dependency>
<dependency>
<groupId>org.unitils</groupId>
<artifactId>unitils-dbunit</artifactId>
<version>3.4.2</version>
</dependency>
<dependency>
<groupId>org.unitils</groupId>
<artifactId>unitils-io</artifactId>
<version>3.4.2</version>
</dependency>
<dependency>
<groupId>org.unitils</groupId>
<artifactId>unitils-database</artifactId>
<version>3.4.2</version>
</dependency>
<dependency>
<groupId>org.unitils</groupId>
<artifactId>unitils-spring</artifactId>
<version>3.4.2</version>
</dependency>
<dependency>
<groupId>org.dbunit</groupId>
<artifactId>dbunit</artifactId>
<version>2.5.3</version>
</dependency>
配置maven对resourcew文件过滤规则,如果不过滤maven会对resource文件重编码,导致Excel文件被破坏
<resources>
<resource>
<directory>src/test/resources</directory>
<includes>
<include>**/*.*</include>
</includes>
<filtering>false</filtering>
</resource>
</resources>
2. unitils.properties
在测试源码根目录中创建一个项目级别的unitils.properties配置文件,主要用于配置自定义拓展模块,数据加载等相关信息
#启用unitils所需模块 unitils.modules=database,dbunit #自定义扩展模块,加载Excel文件,默认拓展模块org.unitils.dbunit.DbUnitModule支持xml unitils.module.dbunit.className=org.agoura.myunit.module.MyDbUnitModule #配置数据库连接 database.driverClassName=com.mysql.jdbc.Driver database.url=jdbc:mysql://127.0.0.1:3306/teams?autoReconnect=true&useUnicode=true&characterEncoding=utf-8 database.userName=root database.password=agoura #配置为数据库名称 database.schemaNames=teams #配置数据库方言 database.dialect=mysql #需设置false,否则我们的测试函数只有在执行完函数体后,才将数据插入的数据表中 unitils.module.database.runAfter=false #配置数据库维护策略.请注意下面这段描述 # If set to true, the DBMaintainer will be used to update the unit test database schema. This is done once for each # test run, when creating the DataSource that provides access to the unit test database. updateDataBaseSchema.enabled=true #配置数据库表创建策略,是否自动建表以及建表sql脚本存放目录 dbMaintainer.autoCreateExecutedScriptsTable=true dbMaintainer.keepRetryingAfterError.enabled=true dbMaintainer.script.locations=src/main/resources/dbscripts #dbMaintainer.script.fileExtensions=sql #数据集加载策略 #CleanInsertLoadStrategy:先删除dateSet中有关表的数据,然后再插入数据 #InsertLoadStrategy:只插入数据 #RefreshLoadStrategy:有同样key的数据更新,没有的插入 #UpdateLoadStrategy:有同样key的数据更新,没有的不做任何操作 DbUnitModule.DataSet.loadStrategy.default=org.unitils.dbunit.datasetloadstrategy.impl.CleanInsertLoadStrategy #配置数据集工厂,自定义 DbUnitModule.DataSet.factory.default=org.agoura.myunit.utils.MultiSchemaXlsDataSetFactory DbUnitModule.ExpectedDataSet.factory.default=org.agoura.myunit.utils.MultiSchemaXlsDataSetFactory #配置事务策略 commit、rollback 和disabled;或者在代码的方法上标记@Transactional(value=TransactionMode.ROLLBACK) #commit 是单元测试方法过后提交事务 #rollback 是回滚事务 #disabled 是没有事务,默认情况下,事务管理是disabled DatabaseModule.Transactional.value.default=commit #配置数据集结构模式XSD生成路径,可以自定义目录,但不能为空 dataSetStructureGenerator.xsd.dirName=src/main/resources/xsd dbMaintainer.generateDataSetStructure.enabled=true #文件相对路径是否是测试类文件路径,false表示resource根目录 dbUnit.datasetresolver.prefixWithPackageName=false
3. spring-mybatis-unitils.xml
<?xml version="1.0" encoding="GBK"?>
<beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns="http://www.springframework.org/schema/beans"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.1.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.1.xsd">
<context:component-scan base-package="com.agoura.agoura"/>
<context:property-placeholder location="classpath:jdbc_dbcp.properties"/>
<!--<util:properties id="jdbc_dbcp" />-->
<bean id="dataSource" class="org.unitils.database.UnitilsDataSourceFactoryBean"/>
<!-- spring和MyBatis整合,不需要mybatis的配置映射文件 -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<!-- 自动扫描mapping.xml文件 -->
<property name="mapperLocations" value="classpath*:com/agoura/agoura/mapper/xml/*.xml"></property>
</bean>
<!-- DAO接口所在包名,Spring会自动查找其下的类 -->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.agoura.agoura.mapper"/>
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"></property>
</bean>
<!-- (事务管理)transaction manager, use JtaTransactionManager for global tx -->
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
</beans>
dbunit执行流程
dbunit通过@DataSet注解读取模拟数据Excel文件,流程如下:
Excel文件 --> @DataSet --> DbUnitModule --> DataSetFactory --> 数据库(MySql)
@DataSet:将指定路径下Excel文件加载到DbUnitModule中
DbUnitModule:对传入文件进行预处理,源代码中对传入的xml文件copy一份临时文件,并将临时文件交给DataSetFactory处理,处理完后再删除临时文件
DataSetFactory:将读取的Excel数据转换为MultiSchemaDataSet,准备放入数据库中
由于原代码DbUnitModule中只有对xml文件的预处理,而我们是要对Excel文件进行预处理,所以需要对DbUnitModule进行重写。重写内容为:完善DbUnitDatabaseConnection连接;针对Excel文件,修改预处理实现;修改文件处理后续操作。示例如下:
import org.dbunit.database.DatabaseConfig;
import org.dbunit.ext.mysql.MySqlDataTypeFactory;
import org.dbunit.ext.mysql.MySqlMetadataHandler;
import org.unitils.core.UnitilsException;
import org.unitils.dbmaintainer.locator.ClassPathDataLocator;
import org.unitils.dbmaintainer.locator.resourcepickingstrategie.ResourcePickingStrategie;
import org.unitils.dbunit.DbUnitModule;
import org.unitils.dbunit.datasetfactory.DataSetFactory;
import org.unitils.dbunit.util.DbUnitDatabaseConnection;
import org.unitils.dbunit.util.MultiSchemaDataSet;
import java.io.File;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
public class MyDbUnitModule extends DbUnitModule {
//完善DbUnitDatabaseConnection连接信息
@Override
public DbUnitDatabaseConnection getDbUnitDatabaseConnection(final String schemaName) {
DbUnitDatabaseConnection result = dbUnitDatabaseConnections.get(schemaName);
if (result != null) {
return result;
}
result = super.getDbUnitDatabaseConnection(schemaName);
result.getConfig().setProperty(DatabaseConfig.PROPERTY_DATATYPE_FACTORY, new MySqlDataTypeFactory());
result.getConfig().setProperty(DatabaseConfig.PROPERTY_METADATA_HANDLER, new MySqlMetadataHandler());
return result;
}
//Excel预处理操作,将@DataSet注释读取的文件返回给DataSetFactory进行处理
@Override
protected File handleDataSetResource(ClassPathDataLocator locator, String nameResource, ResourcePickingStrategie strategy, Class<?> testClass) {
String cloneResource = new String(nameResource);
String packageName = testClass.getPackage() != null?testClass.getPackage().getName():"";
String tempName = "";
if(cloneResource.startsWith(packageName.replace(".", "/"))) {
cloneResource = tempName = cloneResource.substring(packageName.length());
} else if(cloneResource.startsWith(packageName)) {
cloneResource = tempName = cloneResource.substring(packageName.length() + 1);
} else {
tempName = cloneResource;
}
InputStream in = locator.getDataResource(packageName.replace(".", "/") + "/" + tempName, strategy);
File resolvedFile = null;
if(in == null) {
resolvedFile = this.getDataSetResolver().resolve(testClass, cloneResource);
if(resolvedFile == null) {
throw new UnitilsException("DataSetResource file with name '" + nameResource + "' cannot be found");
}
}
return resolvedFile;
}
//调用DataSetFactory.createDataSet()向数据库中注入Excel数据后,直接返回DataSet,不对DataSet执行清零操作
@Override
protected MultiSchemaDataSet getDataSet(Class<?> testClass, String[] dataSetFileNames, DataSetFactory dataSetFactory) {
List<File> dataSetFiles = new ArrayList<File>();
ResourcePickingStrategie resourcePickingStrategie = getResourcePickingStrategie();
for (String dataSetFileName : dataSetFileNames) {
File dataSetFile = handleDataSetResource(new ClassPathDataLocator(), dataSetFileName, resourcePickingStrategie, testClass);
dataSetFiles.add(dataSetFile);
}
MultiSchemaDataSet dataSet = dataSetFactory.createDataSet(dataSetFiles.toArray(new File[dataSetFiles.size()]));
return dataSet;
}
}
拓展模块DbUnitModule重写完后,由于官方版本中DataSetFactory只对xml文件进行处理,为了能处理Excel文件,需要对DataSetFactory进行重写。示例如下:
import org.unitils.core.UnitilsException;
import org.unitils.dbunit.datasetfactory.DataSetFactory;
import org.unitils.dbunit.util.MultiSchemaDataSet;
import java.io.File;
import java.util.*;
public class MultiSchemaXlsDataSetFactory implements DataSetFactory {
protected String defaultSchemaName;
public void init(Properties configuration, String s) {
this.defaultSchemaName = s;
}
public MultiSchemaDataSet createDataSet(File... dataSetFiles) {
try {
MultiSchemaXlsDataSetReader xlsDataSetReader = new MultiSchemaXlsDataSetReader(defaultSchemaName);
return xlsDataSetReader.readDataSetXls(dataSetFiles);
} catch (Exception e) {
throw new UnitilsException("创建数据集失败:" + Arrays.toString(dataSetFiles), e);
}
}
public String getDataSetFileExtension() {
return "xls";
}
}
createDataSet()为自定义的数据集工厂MultiSchemaXlsDataSetFactory中的核心方法,主要是读取传入的Excel文件,将读取数据写入MutiSchemaXlsDataSet中。MultiSchemaXlsDataSetReader通过POI实现了读取Excel数据功能,可以同时读取多个数据集,也即多个模拟数据库数据。
import org.dbunit.database.AmbiguousTableNameException;
import org.dbunit.dataset.DefaultDataSet;
import org.dbunit.dataset.IDataSet;
import org.dbunit.dataset.ITable;
import org.dbunit.dataset.excel.XlsDataSet;
import org.unitils.core.UnitilsException;
import org.unitils.dbunit.util.MultiSchemaDataSet;
import java.io.File;
import java.io.FileInputStream;
import java.util.*;
public class MultiSchemaXlsDataSetReader {
private String pattern = ".";
private String defaultSchemaName;
public MultiSchemaXlsDataSetReader(String defaultSchemaName) {
this.defaultSchemaName = defaultSchemaName;
}
public MultiSchemaDataSet readDataSetXls(File... dataSetFiles) {
try {
Map<String, List<ITable>> tbMap = getTables(dataSetFiles);
MultiSchemaDataSet dataSets = new MultiSchemaDataSet();
for (Map.Entry<String, List<ITable>> entry : tbMap.entrySet()) {
List<ITable> tables = entry.getValue();
try {
DefaultDataSet ds = new DefaultDataSet(tables.toArray(new ITable[]{}));
dataSets.setDataSetForSchema(entry.getKey(), ds);
} catch (AmbiguousTableNameException e) {
throw new UnitilsException("构造DataSet失败!", e);
}
}
return dataSets;
} catch (Exception e) {
throw new UnitilsException("解析Excel文件出错:", e);
}
}
private Map<String, List<ITable>> getTables(File... dataSetFiles) {
Map<String, List<ITable>> tableMap = new HashMap<>();
// 需要根据schema把Table重新组合一下
try {
String schema, tableName;
for (File file : dataSetFiles) {
IDataSet dataSet = new XlsDataSet(new FileInputStream(file));
String[] tableNames = dataSet.getTableNames();
for (String tn : tableNames) {
String[] temp = tn.split(pattern);
if (temp.length == 2) {
schema = temp[0];
tableName = temp[1];
} else {
schema = this.defaultSchemaName;
tableName = tn;
}
ITable table = dataSet.getTable(tn);
if (!tableMap.containsKey(schema)) {
tableMap.put(schema, new ArrayList<ITable>());
}
tableMap.get(schema).add(new XslTableWrapper(tableName, table));
}
}
} catch (Exception e) {
throw new UnitilsException("Unable to create DbUnit dataset for data set files: " + Arrays.toString(dataSetFiles), e);
}
return tableMap;
}
}
到此,unitils重写及配置完毕,下面进行测试。
测试示例
被测试DAO层代码:
public interface MembersMapper {
int deleteByPrimaryKey(Integer id);
int insert(Members record);
Members selectByPrimaryKey(Integer id);
int updateByPrimaryKey(Members record);
}
测试类文件:
import com.agoura.entity.Members;
import org.junit.Before;
import org.junit.BeforeClass;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.test.context.ContextConfiguration;
import org.unitils.UnitilsJUnit4;
import org.unitils.UnitilsJUnit4TestClassRunner;
import org.unitils.dbunit.annotation.DataSet;
import static org.junit.Assert.assertNotNull;
@RunWith(UnitilsJUnit4TestClassRunner.class)
@ContextConfiguration(locations = {"classpath*:spring-*.xml"})
public class MembersMapperTest extends UnitilsJUnit4 {
private MembersMapper membersMapper;
private static ApplicationContext ctx;
@BeforeClass
public static void setUpBeforeClass() {
ctx = new ClassPathXmlApplicationContext("classpath*:spring-mybatis-unitils.xml");
}
@Before
public void setUp() {
membersMapper = (MembersMapper) ctx.getBean("membersMapper");
}
@Test
@DataSet(value = {"test.xls"}) //test.xlsx
public void testSelectByPrimaryKey() throws Exception {
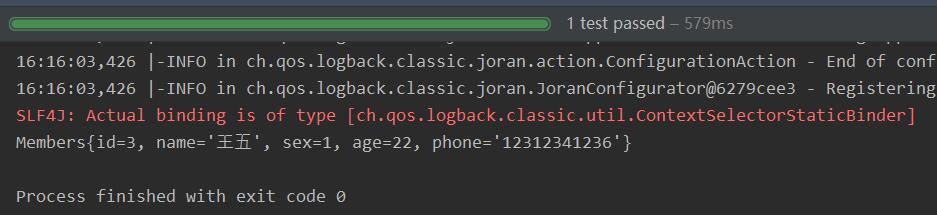
Members member = membersMapper.selectByPrimaryKey(3);
System.out.println(member);
assertEquals("王五", member.getName());
}
}
@DataSet加载Excel文件,既可以加载 .xls文件,也可以加载 .xlsx文件。
.xls示例如下:

应数据库表名,字段必须和数据库表字段一一对应。
测试结果
以上这篇对dbunit进行mybatis DAO层Excel单元测试(必看篇)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。