
使用Lucene实现一个简单的布尔搜索功能
作者:鸿武
Lucene是一个全文搜索框架,而不是应用产品。因此它并不像www.baidu.com 或者google Desktop那么拿来就能用,它只是提供了一种工具让你能实现这些产品。接下来通过本文给大家介绍使用Lucene实现一个简单的布尔搜索功能
什么是lucene
Lucene是apache软件基金会jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。
Lucene是一个全文搜索框架,而不是应用产品。因此它并不像www.baidu.com 或者google Desktop那么拿来就能用,它只是提供了一种工具让你能实现这些产品。
在布尔查询的对象中,包含一个子句的集合,各个子句间都是如“与”、“或”这样的布尔逻辑。Lucene中所遇到的各种复杂查询,最终都可以表示成布尔型的查询。下面代码就是实现了一个简单的布尔查询。
package LuceneSearch;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.BooleanClause;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.Hits;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.TermQuery;
/**
* 布尔搜索测试
* @author sdu20
*
*/
public class BooleanQueryTest {
static final String INDEX_STORE_PATH = "E:\\编程局\\Java编程处\\Index\\";
public static void main(String[] args) {
// TODO Auto-generated method stub
try{
IndexWriter writer = new IndexWriter(INDEX_STORE_PATH,new StandardAnalyzer(),true);
writer.setUseCompoundFile(false);
//创建8个文档
Document doc1 = new Document();
Document doc2 = new Document();
Document doc3 = new Document();
Document doc4 = new Document();
Document doc5 = new Document();
Document doc6 = new Document();
Document doc7 = new Document();
Document doc8 = new Document();
Field f1 = new Field("bookname","钢铁是怎样炼成的",Field.Store.YES,Field.Index.TOKENIZED);
Field f2 = new Field("bookname","英雄儿女",Field.Store.YES,Field.Index.TOKENIZED);
Field f3 = new Field("bookname","浮生六记",Field.Store.YES,Field.Index.TOKENIZED);
Field f4 = new Field("bookname","太平广记",Field.Store.YES,Field.Index.TOKENIZED);
Field f5 = new Field("bookname","文化苦旅",Field.Store.YES,Field.Index.TOKENIZED);
Field f6 = new Field("bookname","白夜行",Field.Store.YES,Field.Index.TOKENIZED);
Field f7 = new Field("bookname","白毛女",Field.Store.YES,Field.Index.TOKENIZED);
Field f8 = new Field("bookname","子不语",Field.Store.YES,Field.Index.TOKENIZED);
doc1.add(f1);
doc2.add(f2);
doc3.add(f3);
doc4.add(f4);
doc5.add(f5);
doc6.add(f6);
doc7.add(f7);
doc8.add(f8);
writer.addDocument(doc1);
writer.addDocument(doc2);
writer.addDocument(doc3);
writer.addDocument(doc4);
writer.addDocument(doc5);
writer.addDocument(doc6);
writer.addDocument(doc7);
writer.addDocument(doc8);
writer.close();
System.out.println("创建索引成功");
IndexSearcher searcher = new IndexSearcher(INDEX_STORE_PATH);
//创建两个词条对象
Term t1 = new Term("bookname","生");
Term t2 = new Term("bookname","记");
TermQuery q1 = new TermQuery(t1);
TermQuery q2 = new TermQuery(t2);
BooleanQuery query = new BooleanQuery();
query.add(q1,BooleanClause.Occur.MUST);
query.add(q2,BooleanClause.Occur.MUST);
Hits hits = searcher.search(query);
for(int i = 0;i<hits.length();i++){
System.out.println(hits.doc(i));
}
System.out.println("搜索成功");
}catch(Exception e){
System.out.println(e.getStackTrace());
}
}
}
BooleanClause.Occur类主要有3种表示,即MUST、MUST_NOT和SHOULD。MUST与MUST_NOT不难理解,一看名字就知道是什么意思,而SHOULD是一个比较特殊的约束,当它与MUST联用时,它将失去意义。检索的结果为MUST子句的检索结果。当它与MUST_NOT联用时,SHOULD的功能就与MUST一样,就退变为MUST和MUST_NOT的查询结果。当SHOULD与SHOULD联用时,它们就表示一种“或”关系。最终检索结果为所有检索子句的检索结果的并集。
上面代码就是查询索引中有“生”字和“记”字的文档,程序运行结果截图如下
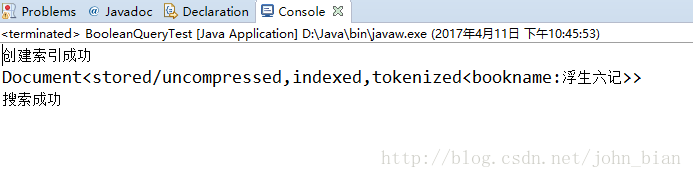
索引目录文件夹下截图如下

以上所述是小编给大家介绍的使用Lucene实现一个简单的布尔搜索功能,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对脚本之家网站的支持!